Remote site reliability engineer jobs
We, at Turing, are looking for site reliability engineers who will be responsible for automating solutions including capacity and performance planning, managing risks, disaster response, and on-call monitoring. Here’s your chance to work with elite U.S. companies and collaborate with top professionals across the globe.
Find remote software jobs with hundreds of Turing clients
Job description
Job responsibilities
- Build software applications to help operations and support teams
- Gather and analyze metrics to help in performance tuning and troubleshooting errors
- Contribute to system design consulting, platform management, and capacity planning
- Develop sustainable systems and services with automation and uplifts
- Improve feature development speed and system reliability through optimization of on-call processes
- Prepare documentation of historical knowledge concerning software development, support, IT operations, and on-call duties
- Monitor application performance and keep the sites up and running
Minimum requirements
- Bachelor’s/Master’s degree in Engineering, Computer Science, or IT (or equivalent experience)
- At least 3+ years of experience as a site reliability engineer (rare exceptions for highly skilled engineers)
- Proficient understanding of operating systems (Linux/Windows)
- Expert knowledge of DevOps concepts and best practices
- Expertise in CI/CD implementation
- Hands-on experience in troubleshooting issues
- Knowledge of one or more high-level programming languages like Python, Java, JavaScript, C/C++, Ruby, etc.
- Experience with distributed storage technologies and dynamic resource management frameworks
- Fluent in English to communicate effectively
- Ability to work full-time (40 hours/week) with a 4 hour overlap with US time zones
Preferred skills
- Working knowledge of code versioning tools such as Git
- Proactivity in finding issues, performance bottlenecks, and areas for improvement
- Passion for automation, coding skills, and software-centric mindset
- Understanding of distributed computing, cloud-native applications, application monitoring, and database management
- Excellent organizational and interpersonal skills
Interested in this job?
Apply to Turing today.
Why join Turing?

1Elite US Jobs

2Career Growth

3Developer success support







How to become a Turing developer?
Create your profile
Fill in your basic details - Name, location, skills, salary, & experience.
Take our tests and interviews
Solve questions and appear for technical interview.
Receive job offers
Get matched with the best US and Silicon Valley companies.
Start working on your dream job
Once you join Turing, you’ll never have to apply for another job.

How to become a Site Reliability engineer ?
As software development became faster and more complex, traditional software teams had trouble keeping up. To help with the transition of workflows from development to production applications, they introduced DevOps.
However, it became increasingly apparent that this system needed greater reliability and performance in order to stay competitive. This is where the field of site reliability engineering comes into play.
Site reliability engineering blends software engineering practices with information technology (IT) engineering practices to create highly reliable systems. Site reliability engineers are responsible for ensuring the reliability of all aspects of the full stack, from the front-end, customer-facing applications all the way through to the database and hardware infrastructure.
What is the scope in Site Reliability engineering?
The role of SRE (Systems and Release Engineer) is ideal for assessing the newest development in the DevOps world, expanding your knowledge and skills in high-demand areas such as infrastructure automation, release engineering, and continuous delivery. As an SRE, you’ll be highly creative, stimulated, and technically challenged every day.
Site reliability engineers are crucial to most organizations. These professionals are in high demand at successful tech companies that have large data centers and complex technical challenges. They can also be inspirational from both a financial and workplace culture perspective. Google considers them scarce resources.
What are the roles and responsibilities of a Site Reliability engineer?
Site reliability engineering (SRE) refers to software engineering approaches used by organizations to manage their IT operations. SRE teams use software tools as a way to automate operations and solve problems in a timely manner.
Software reliability engineers (SREs) are software engineers who have Unix systems administration, networking, and software engineering experience. SREs also have polished programming skills because they regularly use automation to reduce human labor and increase reliability.
Software Release Engineering (SRE) transfers the tedious work traditionally done by DevOps and operations teams to software engineers who can use automation and software to optimize processes.
Site reliability engineers spend half their time doing development work, and the other half doing operations duties, such as responding to outages and incidents and being on call.
The roles and responsibilities of a site reliability engineer include
- Building software to help Operations and Support Teams
- Conducting Post-Incident Reviews
- Documenting the knowledge to ensure a seamless flow of information between teams
- Implementing strategies to increase system reliability and performance through on-call rotation
- Fix cases related to support escalation
- Incorporate various software engineering aspects to develop and implement services that improve IT and support teams
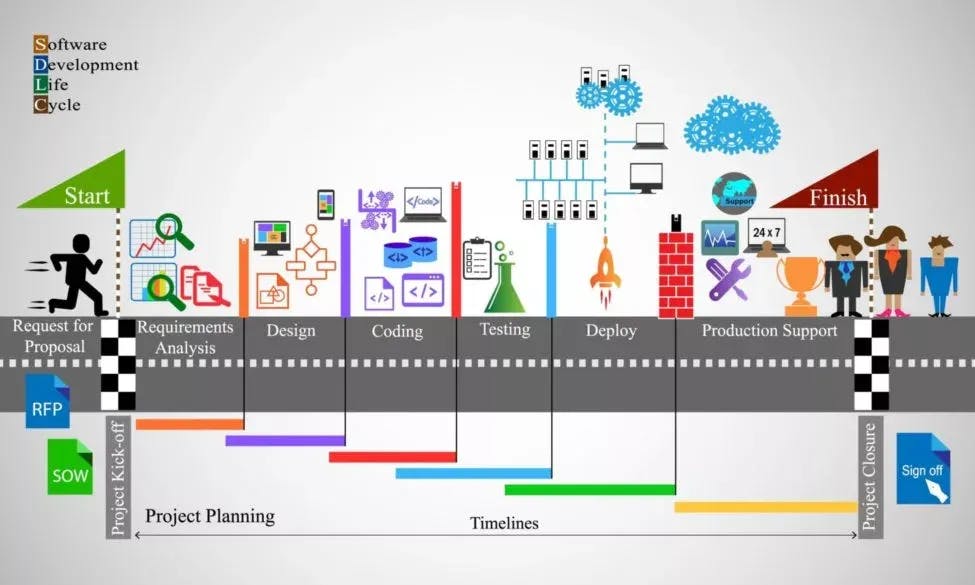
- Optimize the Software Development Life Cycle (SDLC) to boost service reliability
How to become a Site Reliability engineer?
You can become a site reliability engineer in the following ways:
- Bachelor's degree: It is mandatory for the developer to have a Bachelor’s degree or Master’s degree. This helps with growth in the software field and also aids in easy understanding of technical aspects of the job.
- 2+ years experience in operations or software engineering role: It helps if you have some previous experience working as a software engineer. This will give you an advantage over other candidates while trying for SRE positions.
- Required skills: You must have the following technical skills.
- Experience with cloud-continuous deployment based software development lifecycles
- Expertise in infrastructure automation technologies
Along with technical skills you must have a strong foundation of non-technical skills as well. What you need:
- Excellent verbal and written communication skills
- Strong problem-solving skills
- Passion and curiosity for technology
- Keenness to provide support for teams or customers.
Now let us discuss the skills and methods you will need to learn to become a successful site reliability engineer:
Interested in remote Site Reliability jobs?
Become a Turing developer!
Skills required to become a Site Reliability engineer
Fundamental skills are important in helping you land high-paying site reliability engineer jobs. Here is what you need to know!
1. DevOps
DevOps refers to a set of practices that promote better collaboration and widespread automation of the processes happening between operational and development teams. It can be extended to other business units as well.
DevOps is a new cultural movement combining software development, operations, and engineering. It stimulates the adoption of agile practices that are continuous in nature and enable continuous delivery of small batches to customers.
2. Python
Python is easy to learn. It is a high-level, dynamic language with an interpreted structure to make debugging errors relatively painless. Which helps programmers rapidly develop working application prototypes. This feature has earned Python a reputation as a language well-suited for coding. Because Python supports cross-platform operating systems, it is a good choice for programmers. Especially those who do not want to spend time writing separate programs for different operating systems.
3. Go
Go was created for applications relating to network infrastructure and was intended to replace Java and C++. It is used in cloud-based or server-side (web) applications. With DevOps, site reliability automation, micro-controller programming, robotics, and games also common users of Go. Go is also used in the world of artificial intelligence and data science.
4. CI/CD
Continuous integration/continuous delivery (CI/CD) is a software development process in which code is automatically built and tested as new code is added. CI/CD can improve the effectiveness of a software team by reducing the risk of errors or defects and enabling automated deployments, freeing up time spent manually building, testing, or releasing software.
CI/CD introduces automated processes to integrate code and test in a continuous manner with delivery and deployment, replacing error-prone manual processes. CI/CD is supported by teams working together in an agile way, either with DevOps or SRE practices.
5. Version control
Version control or revision control systems help software developers keep track of changes to application code and manage the development of a single program by more than one person. Version control systems such as Git have the ability to create branches, where a developer can make a copy of an existing project and modify one or more files.
6. NoSQL databases
NoSQL databases are a class of database management systems (DBMSs) that do not rely on the traditional relational database management system (RDBMS) structure. NoSQL databases are purpose-built for specific data models, have flexible schemas for building modern applications, and are widely recognized for their ease of development and performance at scale. These databases use various data models for accessing and managing data, which makes them optimized specifically for applications that require large data volume, low latency, and flexible data models.
Interested in remote Site Reliability jobs?
Become a Turing developer!
How to get remote Site Reliability engineer jobs?
Developers are a lot like athletes. In order to excel at their craft, they have to practice effectively and consistently. They also need to work hard enough so that their skills grow gradually over time. In that regard, there are two major factors that developers must focus on in order for that progress to happen: the support of someone who is more experienced and effective in practice techniques while you're practicing. As a developer, it's vital for you to know how much to practice - so make sure there is someone on hand who will help you out and keep an eye out for any signs of burnout!
Turing offers the best remote site reliability engineer jobs that suit your career trajectories as a site reliability engineer. Grow rapidly by working on challenging technical and business problems on the latest technologies. Join a network of the world's best developers & get full-time, long-term remote site reliability engineer jobs with better compensation and career growth.
Why become a Site Reliability engineer at Turing?
Elite US jobs
Career growth
Exclusive developer community
Once you join Turing, you’ll never have to apply for another job.
Work from the comfort of your home
Great compensation
How much does Turing pay their Site Reliability engineers?
At Turing, every site reliability engineer is allowed to set their rate. However, Turing will recommend a salary at which we know we can find a fruitful and long-term opportunity for you. Our recommendations are based on our assessment of market conditions and the demand that we see from our customers.
Frequently Asked Questions
Latest posts from Turing



Leadership
Equal Opportunity Policy
Explore remote developer jobs


Based on your skills
- React/Node
- React.js
- Node.js
- AWS
- JavaScript

- Python

- Python/React
- Typescript

- Java
- PostgreSQL

- React Native
- PHP
- PHP/Laravel

- Golang
- Ruby on Rails

- Angular
- Android

- iOS

- AI/ML

- Angular/Node
- Laravel
- MySQL

- ASP .NET

Based on your role
- Full-stack
- Back-end
- Front-end
- DevOps
- Mobile

- Data Engineer

- Business Analyst
- Data Scientist
- ML Scientist

- ML Engineer

Based on your career trajectory
- Software Engineer
- Software Developer
- Senior Engineer
- Software Architect
- Senior Architect
- Tech Lead Manager
- VP of Software Engineering