
AI
Basic Interview Q&A

1. Explain Artificial Intelligence and give its applications.
Artificial Intelligence (AI) is a field of Computer Science focuses on creating systems that can perform tasks that would typically require human intelligence, such as recognizing speech, understanding natural language, making decisions, and learning. We use AI to build various applications, including image and speech recognition, natural language processing (NLP), robotics, and machine learning models like neural networks.
2. How are machine learning and AI related?
Machine learning and Artificial Intelligence (AI) are closely related but distinct fields within the broader domain of computer science. AI includes not only machine learning but also other approaches, like rule-based systems, expert systems, and knowledge-based systems, which do not necessarily involve learning from data. Many state-of-the-art AI systems are built upon machine learning techniques, as these approaches have proven to be highly effective in tackling complex, data-driven problems.
3. What is Deep Learning based on?
Deep learning is a subfield of machine learning that focuses on the development of artificial neural networks with multiple layers, also known as deep neural networks. These networks are particularly effective in modeling complex, hierarchical patterns and representations in data. Deep learning is inspired by the structure and function of the human brain, specifically the biological neural networks that make up the brain.
Learn more about AI vs ML vs Deep Learning here.
4. How many layers are in a Neural Network?
Neural networks are one of many types of ML algorithms that are used to model complex patterns in data. They are composed of three layers — input layer, hidden layer, and output layer.
5. Explain TensorFlow.
TensorFlow is an open-source platform developed by Google designed primarily for high-performance numerical computation. It offers a collection of workflows that can be used to develop and train models to make machine learning robust and efficient. TensorFlow is customizable, and thus, helps developers create experiential learning architectures and work on the same to produce desired results.
6. What are the pros of cognitive computing?
Cognitive computing is a type of AI that mimics human thought processes.We use this form of computing to solve problems that are complex for traditional computer systems. Some major benefits of cognitive computing are:
- It is the combination of technology that helps to understand human interaction and provide answers.
- Cognitive computing systems acquire knowledge from the data.
- These computing systems also enhance operational efficiency for enterprises.
7. What’s the difference between NLP and NLU?
Natural Language Processing (NLP) and Natural Language Understanding (NLU) are two closely related subfields within the broader domain of Artificial Intelligence (AI), focused on the interaction between computers and human languages. Although they are often used interchangeably, they emphasize different aspects of language processing.
NLP deals with the development of algorithms and techniques that enable computers to process, analyze, and generate human language. NLP covers a wide range of tasks, including text analysis, sentiment analysis, machine translation, summarization, part-of-speech tagging, named-entity recognition, and more. The goal of NLP is to enable computers to effectively handle text and speech data, extract useful information, and generate human-like language outputs.
While, NLU is a subset of NLP that focuses specifically on the comprehension and interpretation of meaning from human language inputs. NLU aims to disambiguate the nuances, context, and intent in human language, helping machines grasp not just the structure but also the underlying meaning, sentiment, and purpose. NLU tasks may include sentiment analysis, question-answering, intent recognition, and semantic parsing.
8. Give some examples of weak and strong AI.
Some examples of weak AI include rule-based systems and decision trees. Basically, those systems that require an input come under weak AI. On the other hand, a strong AI includes neural networks and deep learning, as these systems and functions can teach themselves to solve problems.
9. What is the need of data mining?
Data mining is the process of discovering patterns, trends, and useful information from large datasets using various algorithms, statistical methods, and machine learning techniques. It has gained significant importance due to the growth of data generation and storage capabilities. The need for data mining arises from several aspects, including decision-making.
10. Name some sectors where data mining is applicable.
There are many sectors where data mining is applicable, including:
Healthcare -It is used to predict patient outcomes, detection of fraud and abuse, measure the effectiveness of certain treatments, and develop patient and doctor relationships.
Finance -The finance and banking industry depends on high-quality, reliable data. It can be used to predict stock prices, predict loan payments and determine credit ratings.
Retail - It is used to predict consumer behavior, noticing buying patterns to improve customer service and satisfaction.
11. What are the components of NLP?
There are three main components to NLP:
- Language understanding - This defines the ability to interpret the meaning of a piece of text
- Language generation - This is helpful in producing text that is grammatically correct and conveys the intended meaning.
- Language processing - This helps in performing operations on a piece of text, such as tokenization, lemmatization, and part-of-speech tagging.
12. What is the full form of LSTM?
LSTM stands for Long Short-Term Memory, and it is a type of recurrent neural network (RNN) architecture that is widely used in artificial intelligence and natural language processing. LSTM networks have been successfully used in a wide range of applications, including speech recognition, language translation, and video analysis, among others.
13. What is Artificial Narrow Intelligence (ANI)?
Artificial Narrow Intelligence (ANI), also known as Weak AI, refers to AI systems that are designed and trained to perform a specific task or a narrow range of tasks. These systems are highly specialized and can perform their designated task with a high degree of accuracy and efficiency. This type of technology is also known as Weak AI.
14. What is a data cube?
A data cube is a multidimensional (3D) representation of data that can be used to support various types of analysis and modeling. Data cubes are often used in machine learning and data mining applications to help identify patterns, trends, and correlations in complex datasets.
15. What is the difference between model accuracy and model performance?
Model accuracy refers to how often a model correctly predicts the outcome of a specific task on a given dataset. Model performance, on the other hand, is a broader term that encompasses various aspects of a model's performance, including its accuracy, precision, recall, F1 score, AUC-ROC, etc. Depending on the problem you're solving, one metric may be more important than the other.
16. What are different components of GAN?
Generative Adversarial Network (GAN) are a class of deep learning models that consist of two primary components working together in a competitive setting. GANs are used to generate new, synthetic data that closely resemble a given real-world dataset. The two main components of a GAN are:
Generator: The generator is a neural network that takes random noise as input and generates synthetic data samples. The aim of the generator is to produce realistic data that mimic the distribution of the real-world data. As the training progresses, the generator becomes better at generating data that closely resemble the original dataset, without actually replicating any specific instances.
Discriminator: The discriminator is another neural network that is responsible for distinguishing between real data samples (from the original dataset) and synthetic data samples (generated by the generator). Its objective is to correctly classify the input as real or synthesized.
17. What are common data structures used in deep learning?
Deep learning models involve handling various types of data, which require specific data structures to store and manipulate the data efficiently. Some of the most common data structures used in deep learning are:
Tensors: Tensors are multi-dimensional arrays and are the fundamental data structure used in deep learning frameworks like TensorFlow and PyTorch. They are used to represent a wide variety of data, including scalars, vectors, matrices, or higher-dimensional arrays.
Matrices: Matrices are two-dimensional arrays and are a special case of tensors. They are widely used in linear algebra operations that are common in deep learning, such as matrix multiplication, transpose, and inversion.
Vectors: Vectors are one-dimensional arrays and can also be regarded as a special case of tensors. They are used to represent individual data points, model parameters, or intermediate results during calculations.
Arrays: Arrays are fixed-size, homogeneous data structures that can store elements in a contiguous memory location. Arrays can be one-dimensional (similar to vectors) or multi-dimensional (similar to matrices or tensors).
18. What is the role of the hidden layer in a neural network?
The hidden layer in a neural network is responsible for mapping the input to the output. The hidden layer's function is to extract and learn features from the input data that are relevant for the given task. These features are then used by the output layer to make predictions or classifications.
In other words, the hidden layer acts as a "black box" that transforms the input data into a form that is more useful for the output layer.
19. Mention some advantages of neural networks.
Some advantages of neural networks include:
- Neural networks need less formal statistical training.
- Neural networks can detect non-linear relationships between variables and can identify all types of interactions between predictor variables.
- Neural networks can handle large amounts of data and extract meaningful insights from it. This makes them useful in a variety of applications, such as image recognition, speech recognition, and natural language processing.
- Neural networks are able to filter out noise and extract meaningful features from data. This makes them useful in applications where the data may be noisy or contain irrelevant information.
- Neural networks can adapt to changes in the input data and adjust their parameters accordingly. This makes them useful in applications where the input data is dynamic or changes over time.
20. What is the difference between stemming and lemmatization?
The main difference between stemming and lemmatization is that stemming is a rule-based process, while lemmatization is a more sophisticated, dictionary-based approach.

21. What are the different types of text summarization?
There are two main types of text summarization:
Extraction-based: It does not take new phrases and words; instead, it uses the already existing phrases and words and presents only that. Extraction-based summarization ranks all the sentences according to the relevance and understanding of the text and presents you with the most important sentences.
Abstraction-based: It creates phrases and words, puts them together, and makes a meaningful word or sentence. Along with that, abstraction-based summarization adds the most important facts found in the text. It tries to find out the meaning of the whole text and presents the meaning to you.
22. What is the meaning of corpus in NLP?
Corpus in NLP refers to a large collection of texts. A corpus can be used for various tasks such as building dictionaries, developing statistical models, or simply for reading comprehension.
23. Explain binarizing of data.
Binarizing of data is the process of converting data features of any entity into vectors of binary numbers to make classifier algorithms more productive. The binarizing technique is used for the recognition of shapes, objects, and characters. Using this, it is easy to distinguish the object of interest from the background in which it is found.
24. What is perception and its types?
Perception is the process of interpreting sensory information, and there are three main types of perception: visual, auditory, and tactile.
Vision: It is used in the form of face recognition, medical imaging analysis, 3D scene modeling, video recognition, human pose tracking, and many more
Auditory: Machine Auditory has a wide range of applications, such as speech synthesis, voice recognition, and music recording. These solutions are integrated into voice assistants and smartphones.
Tactile: With this, machines are able to acquire intelligent reflexes and better interact with the environment.
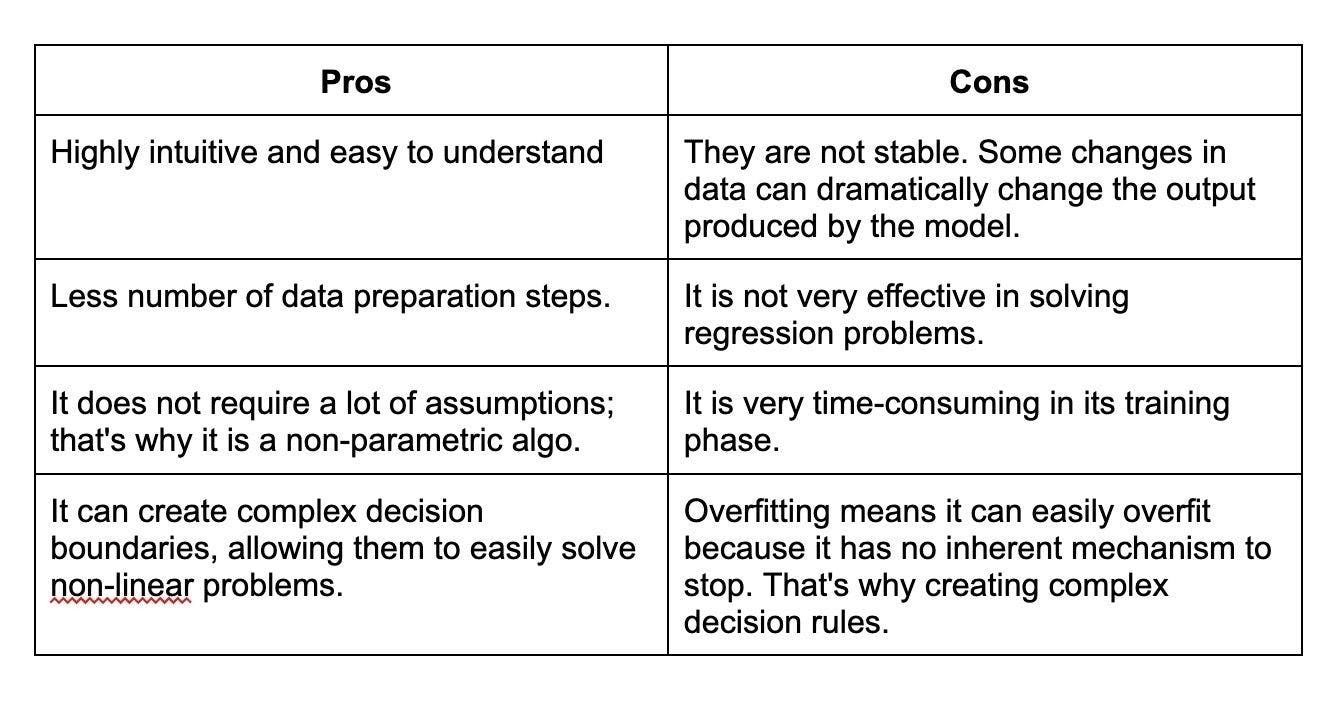
25. Give some pros and cons of decision trees.
Decision trees have some advantages, such as being easy to understand and interpret, but they also have some disadvantages, such as being prone to overfitting.
26. Explain marginalization process.
The marginalization process is used to eliminate certain variables from a set of data, in order to make the data more manageable. In probability theory, marginalization involves integrating over a subset of variables in a joint distribution to obtain the distribution of the remaining variables. The process essentially involves "summing out" the variables that are not of interest, leaving only the variables that are desired.
27. What is the function of an artificial neural network?
An artificial neural network is a ML algorithm that is used to simulate the workings of the human brain. ANNs consist of interconnected nodes (also known as neurons) that process and transmit information in a way that mimics the behavior of biological neurons.
The primary function of an artificial neural network is to learn from input data, such as images, text, or numerical values, and then make predictions or classifications based on that data. ANNs can be used for a wide range of tasks, such as image recognition, natural language processing, and predictive analytics.
28. Explain cognitive computing and its types?
Cognitive computing is a subfield of AI that focuses on creating systems that can mimic human cognition and perform tasks that require human-like intelligence. The primary goal of cognitive computing is to enable computers to interact more naturally with humans, understand complex data, reason, learn from experience, and make decisions autonomously.
There is no strict categorization of cognitive computing types; however, the key capabilities and technologies associated with cognitive computing can be grouped as follows:
NLP: NLP techniques enable cognitive computing systems to understand, process, and generate human language in textual or spoken form.
Machine Learning: Machine learning is essential for cognitive computing, as it allows systems to learn from data, adapt, and improve their performance over time.
Computer Vision: Computer vision deals with the interpretation and understanding of visual information, such as images and videos. In cognitive computing, it is used to extract useful information from visual data, recognize objects, understand scenes, and analyze emotions or expressions.
29. Explain the function of deep learning frameworks.
Deep learning frameworks are software libraries and tools designed to simplify the development, training, and deployment of deep learning models. They provide a range of functionalities that support the implementation of complex neural networks and the execution of mathematical operations required for their training and inference processes. Some popular deep learning frameworks are TensorFlow, Keras, and PyTorch.
30. How are speech recognition and video recognition different?
Speech recognition and video recognition are two distinct areas within AI and involve processing and understanding different types of data. While they share some commonalities in terms of using machine learning and pattern recognition techniques, they differ in the data, algorithms, and objectives associated with each domain.
Speech Recognition focuses on the automatic conversion of spoken language into textual form. This process involves understanding and transcribing the spoken words, phrases, and sentences from an audio signal.
Video Recognition deals with the analysis and understanding of visual information in the form of videos. This process primarily involves extracting meaningful information from a series of image frames, such as detecting objects, recognizing actions, identifying scenes, and tracking moving objects.
31. What is the pooling layer on CNN?
A pooling layer is a type of layer used in a convolutional neural network (CNN). Pooling layers downsample the input feature maps by summary pooled areas. This reduces the dimensionality of the feature map and makes the CNN more robust to small changes in the input.
32. What is the purpose of Boltzmann machine?
Boltzmann machines are a type of energy-based model which learn a probability distribution by simulating a system of diverging and converging nodes. These nodes act like neurons in a neural network, and can be used to build deep learning models.
33. What do you mean by regular grammar?
Regular grammar is a type of grammar that specifies a set of rules for how strings can be formed from a given alphabet. These rules can be used to generate new strings or to check if a given string is valid.
34. How do you obtain data for NLP projects?
There are many ways to obtain data for NLP projects. Some common sources of data include texts, transcripts, social media posts, and reviews. You can also use web scraping and other methods to collect data from the internet.
35. Explain regular expression in layman’s terms.
Regular expressions are a type of syntax used to match patterns in strings. They can be used to find, replace, or extract text. In layman's terms, regular expressions are a way to describe patterns in data. They are commonly used in programming, text editing, and data processing tasks to manipulate and extract text in a more efficient and precise way.
36. How is NLTK different from spaCy?
Both NLTK and spaCy are popular NLP libraries in Python, but they have some key differences:
NLTK is a general-purpose NLP library that provides a wide range of tools and algorithms for basic NLP tasks such as tokenization, stemming, and part-of-speech tagging. NLTK also has tools for text classification, sentiment analysis, and machine translation. In contrast, spaCy focuses more on advanced NLP tasks such as named entity recognition, dependency parsing, and semantic similarity.
spaCy is generally considered to be faster and more efficient than NLTK due to its optimized Cython-based implementation. spaCy is designed to process large volumes of text quickly and efficiently, making it well-suited for production environments.
37. Name some best tools useful in NLP.
There are several powerful tools and libraries available for Natural Language Processing (NLP) tasks, which cater to various needs like text processing, tokenization, sentiment analysis, machine translation, among others. Some of the best NLP tools and libraries include:
NLTK: NLTK is a popular Python library for working with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources, along with text processing libraries for classification, tokenization, stemming, tagging, parsing, and more.
spaCy: spaCy is a modern, high-performance, and industry-ready NLP library for Python. It offers state-of-the-art algorithms for fast and accurate text processing, and includes features like part-of-speech tagging, named entity recognition, dependency parsing, and word vectors.
Gensim: Gensim is a Python library designed for topic modeling and document similarity analysis. It specializes in unsupervised semantic modeling and is particularly useful for tasks like topic extraction, document comparison, and information retrieval.
OpenNLP: OpenNLP is an open-source Java-based NLP library that provides various components such as tokenizer, sentence segmenter, part-of-speech tagger, parser, and named entity recognizer. It is widely used for creating natural language processing applications.
38. Are chatbots derived from NLP?
Yes, chatbots are derived from NLP. NLP is used to process and understand human language so that chatbots can respond in a way that is natural for humans.
39. What is embedding and what are some techniques to accomplish embedding?
Embedding is a technique to represent data in a vector space so that similar data points are close together. Some techniques to accomplish embedding are word2vec and GloVe.
Word2vec: It is used to find similar words which have similar dimensions and, consequently, help bring context. It helps in establishing the association of a word with another similar meaning word through the created vectors.
GloVe: It is used for word representation. GloVe is developed for generating word embeddings by aggregating global word-word co-occurrence matrices from a corpus. The result shows the linear structure of the word in vector space.











Wrapping up
On this page, we have discussed the top 100 AI interview questions and answers that will be useful for both developers and recruiters in the hiring process. AI is a vast field and the questions are not limited to these; however, they are useful and cover the broad knowledge that an AI professional needs to be familiar with.
Moreover, if you’d like to skip this entire hiring process an onboard skilled AI developers or development teams, choose Turing and get it done seamlessly. Or, if you’re an AI developer looking for high-paying jobs with top US companies, click here to apply and get matched with elite US clients through Turing’s Talent Cloud.
Hire Silicon Valley-caliber AI developers at half the cost
Turing helps companies match with top quality remote JavaScript developers from across the world in a matter of days. Scale your engineering team with pre-vetted JavaScript developers at the push of a buttton.
Tired of interviewing candidates to find the best developers?
Hire top vetted developers within 4 days.





Leading enterprises, startups, and more have trusted Turing

Check out more interview questions
Hire remote developers
Tell us the skills you need and we'll find the best developer for you in days, not weeks.