Stemming vs Lemmatization in Python
•8 min read
- Software comparisons

Stemming vs lemmatization in Python is all about reducing the texts to their root forms. These techniques are used by chatbots and search engines to analyze the meaning behind the search queries. Stemming in Python uses the stem of the search query or the word, whereas lemmatization uses the context of the search query that is being used.
When searching for any data, we want relevant search results not only for the exact search term, but also for the other possible forms of the words that we use.
Lemmatization and stemming are text normalization techniques used in Natural Language Processing (NLP). Both the techniques break down the search queries into their root forms.
In this comprehensive guide, we will walk you through stemming and lemmatization with examples and code fragments. We will also learn more about these two approaches using the Python Natural Language Tool Kit (nltk) package.
Lemmatization in Python
Lemmatization deals with reducing the word or the search query to its canonical dictionary form. The root word is called a ‘lemma’ and the method is called lemmatization. This approach takes a part of the word into consideration in a way that it is recognized as a single element.
Let’s check out a few use cases of lemmatization.
1. Search engines
Chatbots and search engines implement lemmatization as the technique analyzes the meaning of search queries. The approach finds its biggest usage in different search engines.
2. Compact indexing
It is an effective approach to storing the data in the form of index values.
3. Biomedicine
Lemmatization is used to analyze biomedicine. It increases the efficiency of data retrieval and other related operations.
Let’s take a lemmatization example for better understanding of the concept.
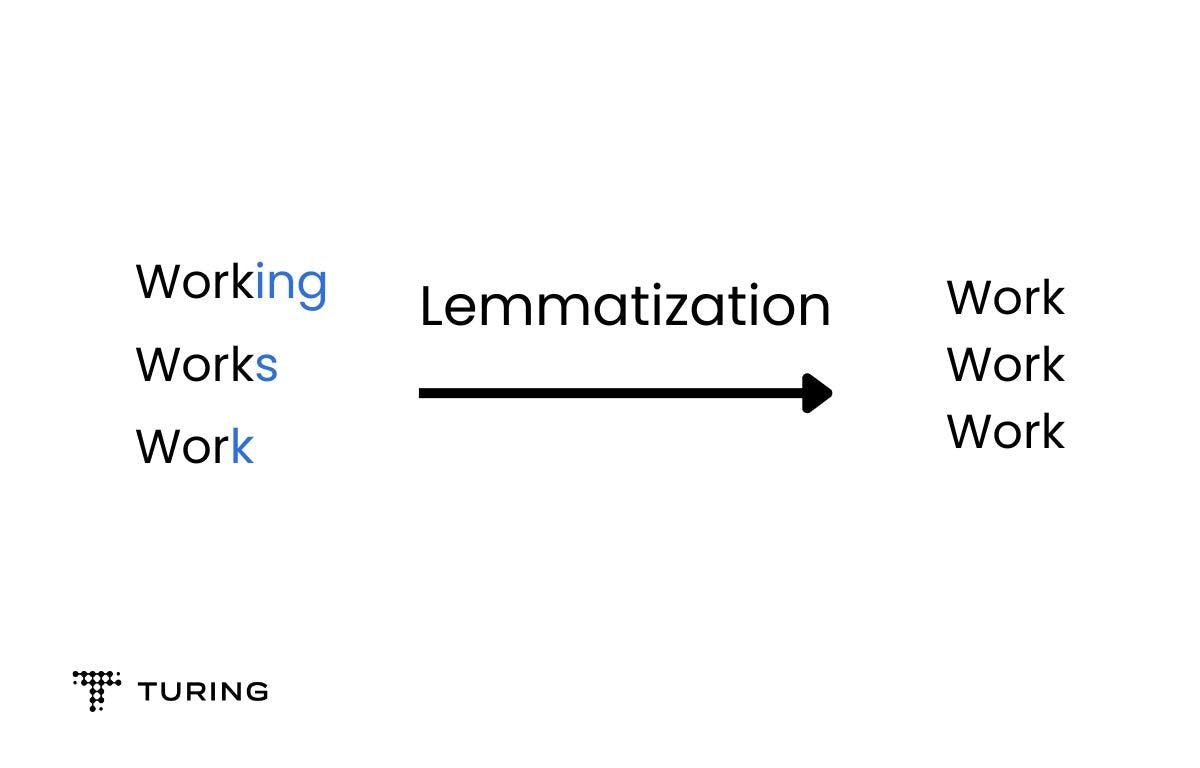
In the above example, ‘working’, ‘works’, and ‘work’ are all forms of the word ‘work’, which is the lemma of these words.
The entire process of lemmatization requires a lot of data to analyze the structure of the language. This approach is more difficult to implement than structuring a stemming algorithm.
Let’s look at how stemming is easier to implement. But first, let’s understand the concept of stemming in Python.
Stemming in Python
Stemming is a rule-based methodology that displays multiple variants of the same base word. The approach reduces the base word to its stem word. This is simpler as it involves indiscriminate reduction of the word-ends. Stemming in Python normalizes the sentences and shortens the search result for a more transparent understanding.
Let’s take a stemming example to better understand the concept using Python nltk:
Code:
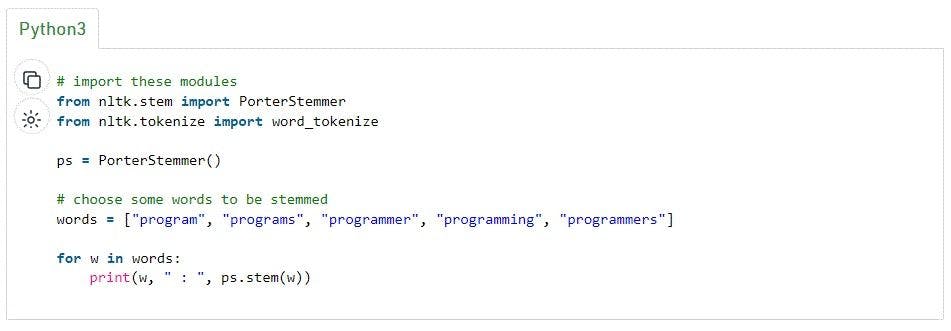
Output:

Although stemming in Python is simpler, it has two main challenges.
Over-stemming
In over-stemming, the meaning of the word is cut off and the resultant stem word makes no sense. This results in words with different meanings from the same stem. For example, the terms are reduced to ‘univers’ for search queries like:
- University
- Universal
- Universe
In this case, even though these three words are etymologically related, their meanings are completely different.
Under-stemming
Here, the expressed words have the same stem even though they have different meanings. Under-stemming is an issue when there are words that are different forms of one another.
Let’s take the example of ‘alumnus’. The different forms would be:
- Alumni
- Alumna
- Alumnae
It should be noted that this English word has a Latin morphology and these synonyms are not combined.
Stemming vs lemmatization
The approach of stemming and lemmatization involves the same methodologies. They both reduce the inflectional forms of each word into a common root word. However, the main difference is in the way these methods are implemented and the result they come up with.
The stemming technique is implemented by cutting down the root word from either the beginning or end. It keeps track of the most commonly used prefixes that are available.
On the other hand, lemmatization in Python deals with the study of the root word to look for a meaningful word. Lemma is the foundation of all its inflected parts.
Both lemmatization and stemming are methods used to prepare a word for text processing. Here is an image to better understand the difference in the concept of stemming and lemmatization.
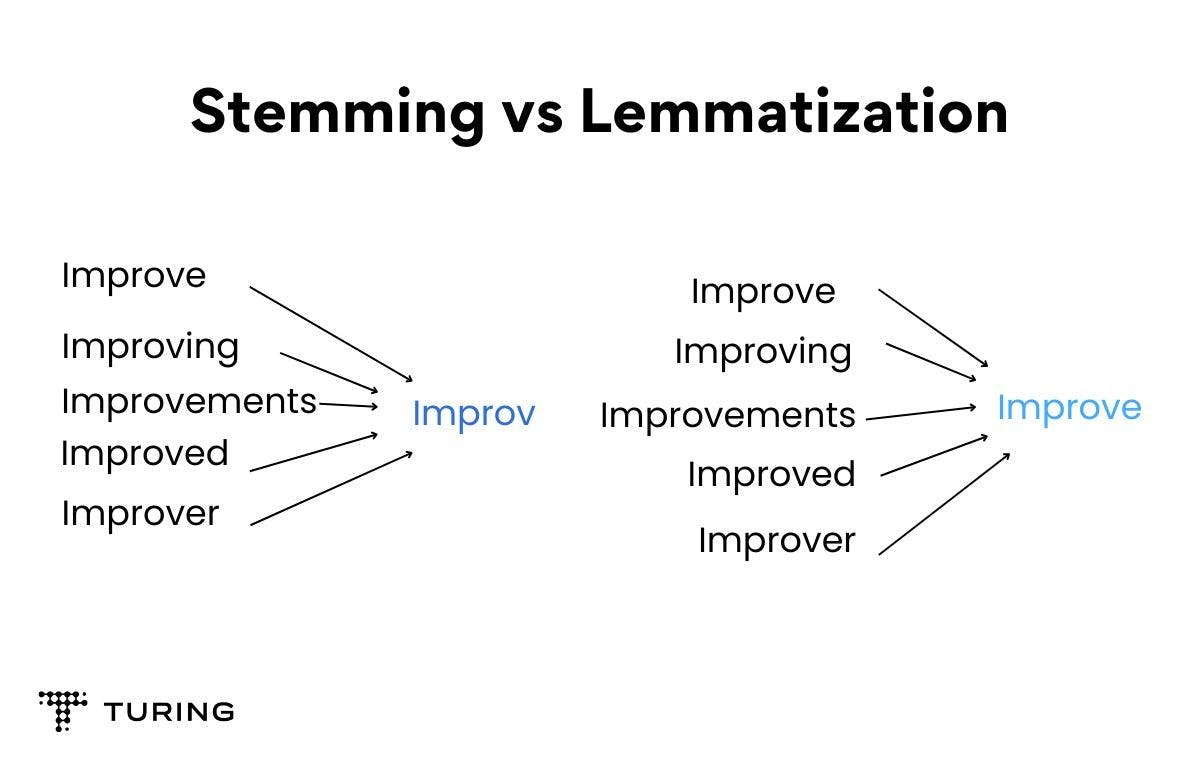
Let’s take an example where you need to process data for classification and you choose any vectorizer to transform the data. Vectorization is a process of implementing array operation without being used for loops. The vectorizer creates a unique set of data from the one you have considered.
By applying stemming or lemmatization techniques, you can easily reduce the size of the vocabulary by converting the word texts into their root forms. This makes the vocabulary more unique and also reduces ambiguity in the model. As a result, you can train your model and yield better results.
Next, we will walk you through stemming and lemmatization and how you can implement these techniques using the Python NLTK package.
Types of stemming
As mentioned previously, stemming is a rule-based text normalization technique that reduces the prefix and suffix of the word to its root form. However, stemming is a faster process compared to lemmatization as it does not consider the context of the words. Due to its aggressive nature, there always remains a possibility of invalid outcomes in a set of data.
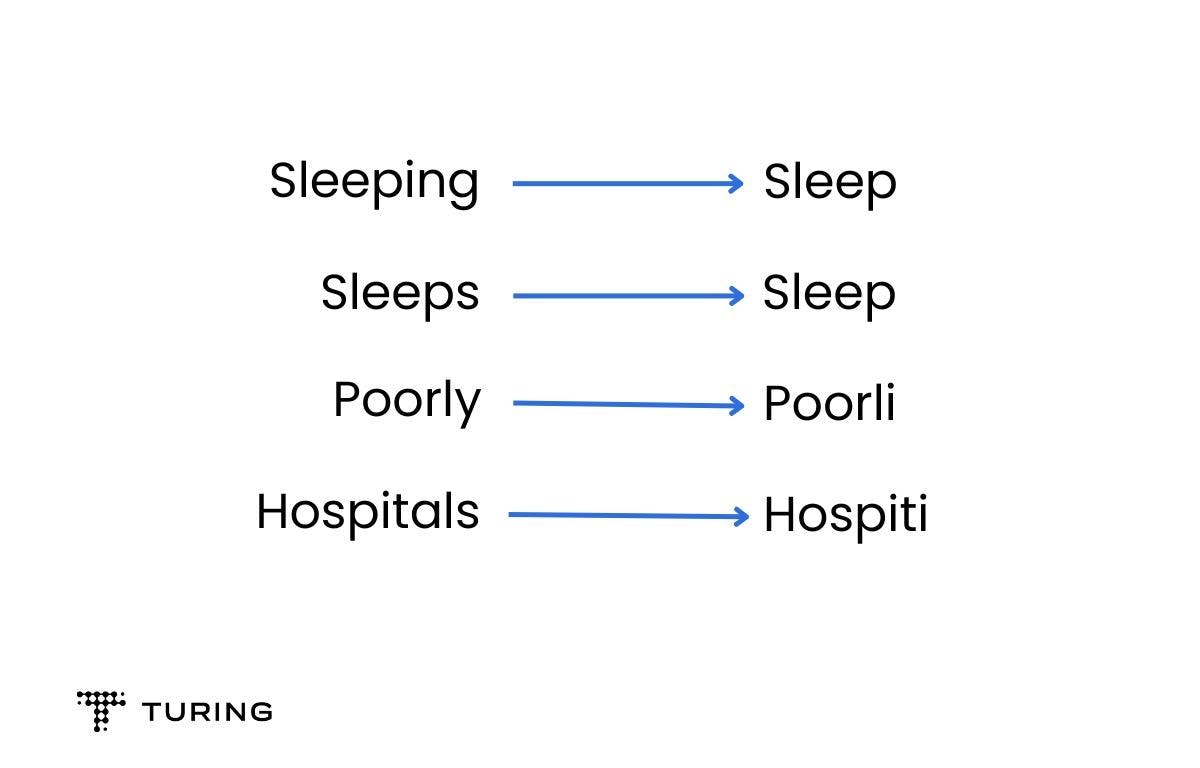
In the above example, you can see the outcomes of ‘poorly’ and ‘hospitals’ are invalid. Now let’s dig into the types of stemming methods that are most commonly used:
The porter stemmer algorithm
The Porter stemmer or the Porter stemmer algorithm uses the suffix-stemming approach to generate stems. Here is an example of a code fragment to understand the Porter stemming algorithm better. We have used nltk to create the stemmer object.
Code fragment to perform Porter stemming:

There are a few drawbacks of the Porter stemming approach and that is why the Snowball stemming approach was introduced.
Snowball stemmer
The Snowball stemmer approach is also called Porter2 stemmer. It is a better version of the Porter stemmer where a few of the stemming issues have been resolved.
A code fragment to perform Porter2 stemming:

It needs to be noted here that even though the term ‘badly’ is a valid stem, the word ‘pharmacies’ is still not a valid stem.
Lancaster stemmer
As compared to the Porter stemming and Porter2 stemming methodologies, Lancaster stemming is an aggressive approach because it implements over-stemming for a lot of terms. It reduces the word to the shortest stem possible.
Here is an example to understand the Lancaster stemming concept:

A code fragment to better understand the Lancaster stemming approach:

The example shows how the Lancaster stemming approach reduces the word to the smallest stem and creates multiple unique words.
Types of lemmatization
Unlike the stemming approach, where a word is stemmed to its root form, lemmatization in Python determines the part of the speech (POS) first. This approach always considers the context first and then converts the word to its meaningful root form called lemma.
WordNet lemmatizer
The WordNet lemmatizer is a lexical database that is used by all the major search engines. It is also used in IR research projects. It provides lemmatization features and is a popular lemmatizer.
Let’s take an example to understand how WordNet lemmatizer works.

In the above code fragment, we can see that ‘plays’ and ‘pharmacies’ are converted to their root forms while the remaining terms are in their original forms. Without the parts of speech (POS tag) tag, lemmatizer assumes every word as a noun by default. To avoid this, we need to pass a POS tag along with the word to the lemmatizer.
WordNet lemmatizer with a POS tag
Now let’s try and pass a POS tag in the WordNet lemmatizer and see the result.

It should be noted here that for the term ‘better’, the output is not the same after adding the POS tag. It detected the word ‘better’ both as an adjective and an adverb.
It will be an added task for the lemmatizer to determine the POS tag for the word. However, when we convert a large number of texts, it becomes difficult to pass a POS tag for each word.
Here is a function to automate the fetching of POS tags for each word in the dataset.

Here is the code fragment to perform WordNet Lemmatization with POS.

There are a few lemmatizers that can be implemented to a set of words.
- TextBlob lemmatizer
- Stanford CoreNLP
- Spacy lemmatizer
- Gensim lemmatizer
Out of all the lemmatizers mentioned here, the Spacy lemmatizer methodology can only be used without passing any POS tags.
Both lemmatization and stemming methodologies can generate the root form of any word. The only difference between them is the actual form of the generated stem. The ‘lemma’ is a meaningful word whereas the ‘stem’ may not be an actual word.
Compared to the stemming technique, lemmatization in Python is a bit slow but it helps in training a machine learning model efficiently. If you are using a huge dataset, the Snowball stemmer (Porter2 stemmer approach) is the best option. In case your ML model uses a count vectorizer and does not consider the context of the words or texts, stemming will be the best approach to follow.
FAQs
1. Which is better? Lemmatization or Stemming?
Stemming is faster to implement and quite straightforward. There might be some inaccuracies, they may be irrelevant to particular tasks and operations.
Lemmatization, on the other hand, provides better results by analyzing the POS of the words and thus displaying real words. Lemmatization is harder to implement and a bit slower when compared to Stemming.
In short, Lemmatization is the best choice when you are looking for qualitative results. In the modern day, Lemmatization algorithms do not affect the performance. But if you want to optimize speed then Stemming algorithms are the best option.
2. Should I use both Stemming & Lemmatization?
In both the cases, you need to vectorize the text inputs. The Term Frequency Inverse Document Frequency (TF-IDF) is a general means to vectorize your input. TF-IDF analyzes how a word is imported to a document contrasted with the frequency of the word occurring.
Implement Stemming when the vocab space is narrow and the documents are large. Secondly, go with word embeddings when the vocab space is large but the documents are small. In case of Lemmatization, the increased performance to increased cost-ratio is quite small.