Natural Language Processing in Action: Understanding, Analyzing, and Generating Text With Python
•5 min read
- Languages, frameworks, tools, and trends

What do Apple’s Siri, Microsoft’s Cortana, and Amazon’s Alexa have in common? They’re some of the most well-known products of natural language processing (NLP).
NLP is a method of teaching machines to decipher the way humans communicate so that they can respond to us in a similar or natural manner. Although NLP is widely used for voice assistance, it has applications elsewhere, from search engines and email filters to language translation, phone calls, and text analysis.
An excellent example is chatbots, tiny messaging icons usually seen on the first page of websites. Their way of interacting is oftentimes so human-like that it can be hard to tell whether we’re texting with a machine or a human.
The uses of natural language processing are limitless. But how is NLP even possible? And what role does Python play? How can we generate text with Python? This article will address these questions and more.
How is text generation possible?
If you compare natural languages such as Chinese, French or German, they differ in writing, dialects, semantics, and syntaxes. Their intricacies become more evident when we write on the internet as we use a lot of jargon and abbreviations.
Regardless of the complexities of human languages, we have successfully built systems that combine machine language and linguistics to understand our thoughts and write back to us with the same sentiment. All of this is possible because of NLP and Python and its libraries. Python's role is significant because text is a type of unstructured data, and Python helps computers understand it in the most efficient way.
Text generation with Python
As stated, text is a non-structured and sequential form of data. Non-structured means data that is difficult for computers to comprehend. On the other hand, sequential data refers to a series or an order where one thing follows the other. For machines to generate text for humans, they must first be trained to convert unstructured data into structured data and learn how to produce text. They can then generate data for us.
Below are the list of steps used to generate text with Python:
- Importing dependencies
- Loading and mapping data into Python
- Analyzing text
- NLP modeling and text generation.
Step 1: Importing dependencies
When starting a new project in Python, the first task is to import all the dependencies. Some of the most helpful dependencies are:
- NLTK: Natural Language Toolkit that’s used for building Python programs related to NLP.
- NumPy: A library used for mathematical tasks on data.
- Pandas: Another library that’s helpful in organizing data for Python.
You can find the steps to import dependencies here.
Step 2: Loading and mapping data into Python
The next step is to load the data into Python to make it easy to read and access. Then, it’s time to map it. Mapping is a simple process where the computer assigns a number and stores it in a dictionary, which is a form of data structure. For instance: 0011, a 4-digit binary number, is assigned to the word ‘hello’.
The purpose of mapping is to help computers read the text effectively because they deal with numbers better.
Step 3: Analyzing text
Since text is unstructured data, it has a lot of meaningless words. In text analysis, data is cleared, processed, and converted into structured data.
Here, the input fed to the system is also referred to as a corpus, which is a collection of texts.
The steps are listed below:
- Data clearing: It involves removing numbers and punctuation and converting data into lower cases.
Input:
Stephen Hawking was an English theoretical physicist, author, and cosmologist.
Output:
stephen hawking was an english theoretical physicist author and cosmologist
- Tokenization: It splits the input into smaller units or words. It can be applied to sentences and paragraphs. The function sent_tokenize is used to tokenize data.
Input:
stephen hawking was an english theoretical physicist author and cosmologist
Output:
stephen hawking was an
english theoretical physicist author
and cosmologist
- Filtering: This helps remove stop words, which are words that have no unique meaning. Words such as an, and, all, that, who, didn’t, is, am, etc. are examples of stop words.
Input:
stephen hawking was an
english theoretical physicist author
and cosmologist
Output:
stephen hawking english theoretical
physicist author cosmologist
The data obtained after filtering is called a ‘bag of words’. At this stage, the data is simple text that can be put into a matrix form.
- Stemming: A process where words are reduced to their root. For instance, stemming teaches the machine that ‘killing’ and ‘kill’ derive from the same word, ‘kill’. For this purpose, NPTK imports porterStemmer.
- Tagging parts of speech: Every natural language has parts of speech. Tagging parts of speech or POS tagging marks data to the different parts of speech.
- Lemmatization: It helps computers to derive the morphological analysis of each word or lemma. This process requires a dictionary to perform the analysis.
Once text analysis is done, the data is ready in a structured form.
Step 4: Modeling and generating text
Modeling is the most crucial stage in generating text. First, the computer system is trained on how to produce text by being fed both input and output. In doing so, it is taught to identify various patterns in natural languages. This means that in the future, it can generate an output of its own if it is fed the input.
This is achieved with the help of the LSTM (long short-term memory) model, a form of model that helps predict sequential data. It can remember patterns for longer durations - a feature that was missing in the previous models. This benefits NLP products such as speech recognition and text generation.
Example:
Let’s suppose we are training a model of input length = 4 and output length = 1 (Text: world)
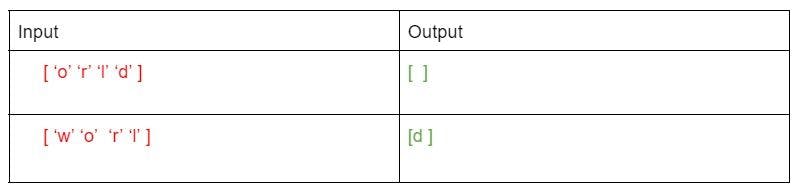
This pattern goes for n different combinations, from a letter and a word to a complete sentence. The model is tested after being trained. For the given example, if the input is “worl”, it will generate the output ‘d’.
Being a raw form of data, text is difficult to read. But with preprocessing, it can be converted into a structured format. Note that text-generating efficiency depends on the model. Text generation can be distributed in two parts - training and testing. The former involves ways of teaching systems how to identify patterns in texts, while testing involves generating texts based on modeling. All of this is possible because of Python and NLTK.