A Guide to Generative Adversarial Networks (GANs) For Beginners
•5 min read
- Languages, frameworks, tools, and trends

Yann LeCun, Meta’s VP and Chief AI Scientist, called generative adversarial networks (GANs) "the most exciting idea in machine learning in the last ten years”. Indeed, since its introduction in 2014 by Ian J. Goodfellow and other researchers at the University of Montreal, GANs have been a major success.
What are generative adversarial networks?
GANs are computational structures that pit two neural networks against one another (hence, the name "adversarial") to generate new, synthetic examples of data that can pass for real data. They're generally implemented in picture, video, and voice creation.
Since GANs can learn to replicate any data distribution, they have enormous potential for both good and evil. They may be trained to construct worlds astonishingly similar to our own in any domain, be it pictures, music, speech, and literature.
In some ways, GANs are robot artists and their work is excellent. They can, however, be used to create fraudulent media material, such as deep fakes.
The ‘magic’ of GANs
Adversarial training is a fascinating concept. It’s beautiful in its simplicity and marks a significant conceptual advance in machine learning, particularly for generative models - in the same way that backpropagation is a simple yet smart trick that helped propel the popularity and efficiency of neural networks.
Generative adversarial networks sometimes appear to be ‘magical’ because of their capacity to produce new content.
In the next sections, we'll look behind this magic and dig into the theories, arithmetic, and modeling that underpin these models. We will also develop the logic that leads to these concepts step by step.
How do GANs work?
Generative adversarial networks are divided into three parts:
1. Generative: A generative model specifies how data is created in terms of a probabilistic model.
2. Adversarial: The model is trained in an adversarial environment.
3. Networks: Deep neural networks, which are artificial intelligence (AI) systems, are used for training.
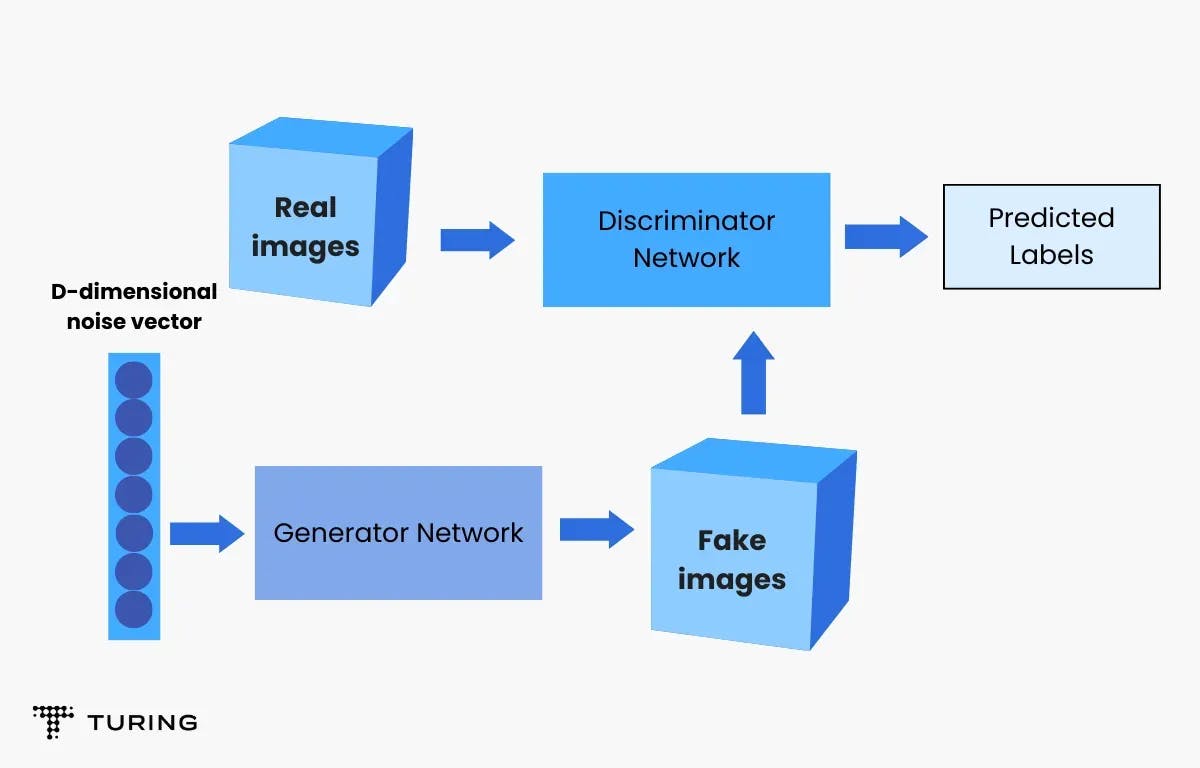
A generator and a discriminator are both present in GANs. The generator creates fake data samples (images, audio, etc.) to deceive the discriminator. On the other hand, the discriminator seeks to discriminate between actual and fraudulent samples.
Both the generator and the discriminator are neural networks and they compete with each other throughout the training phase. The procedures are performed multiple times and with each iteration, the generator and discriminator improve their performance in their respective roles.
The generator creates new data instances while the discriminator analyses them for authenticity, i.e., the discriminator determines whether or not each instance of data it examines corresponds to the real training dataset.
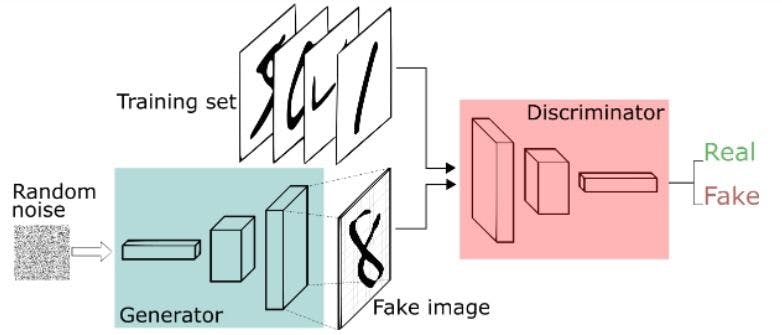
Let's assume that we are making handwritten numbers similar to those seen in the MNIST collection based on real-world data. When provided with an instance from the actual MNIST dataset, the discriminator's purpose is to identify genuine ones. Meanwhile, the generator creates fresh synthetic pictures for the discriminator to process. It does so in the hope of them being recognized as genuine, even though they are not.
The generator's objective is to create presentable handwritten digits, allowing the user to deceive without being discovered. The discriminator's purpose is to recognize pictures generated by the generator as fraudulent.
What are the stages of GANs?
- The generator generates a picture from random numbers.
- Together with a stream of photos from the real ground truth dataset, the image is sent to the discriminator.
- The discriminator accepts both actual and false photos and provides probabilities that range from 0 to 1, with 1 indicating authenticity and 0 indicating fraudulent.
As a result, there is a two-way feedback loop. This is how:
The discriminator is in a feedback loop with the picture’s ground truth and so the discriminator and the generator are in a feedback loop.
A GAN may be considered a game of cat and mouse between a counterfeiter and a cop, with the counterfeiter learning to pass counterfeit notes and the officer learning to identify them. Both are dynamic. For example, the officer is in training (to extend the analogy, perhaps the central bank is flagging money that has slipped through) and each side is always learning the other's techniques.
The discriminator network for MNIST is a conventional convolutional network that can classify pictures supplied to it - a binomial classifier that labels images as real or bogus. In a sense, the generator is an inverse convolutional network. While a conventional convolutional classifier downsamples an image to generate a probability, the generator upsamples a vector of random noise to make an image. The first discards data via downsampling techniques such as max-pooling, while the second produces new data.
In a zero-sum game, both nets attempt to maximize a separate and opposing objective function or loss function. Essentially, this is an actor-critic model. The generator alters its behavior as the discriminator does and vice versa. As a result, their losses pile on top of one other.
Benefits of GANs
- Generative adversarial networks produce data that resembles the original data. For example, when you feed GAN an image, it will create a new version of the image similar to the original. It can also produce alternative text, video, and audio versions.
- GANs delve into the nuances of data and can quickly comprehend multiple versions, making them useful in machine learning.
- Using GANs and machine learning, we can readily distinguish trees, streets, bicyclists, people, and parked automobiles. We can even measure the distance between different items.
Drawbacks of GANs
- Training is more difficult. You need to regularly submit various data to ensure it functions correctly.
- It isn't easy to get outcomes from text or speech.
GANs are an exciting and rapidly evolving field that fulfills the promise of generative models by generating realistic examples across a variety of problem domains. Noteworthy among them are image-to-image translation tasks such as converting summer to winter or day-to-night photos, and generating photorealistic photos of objects, scenes, and people that even humans can't tell are fake.
FAQs
1. What are generative adversarial networks?
They are a class of machine learning frameworks. The main attraction of GANs is that if given a training set, the technique learns to generate new data with the same statistics as the training set.
2. What is the purpose of generative adversarial networks?
The primary purpose of GANs is to create data from scratch, mostly photographs, although other domains such as music have also been explored. However, the application's reach is far broader. For example, GANs may create a zebra from a horse.
3. How do generative adversarial networks work?
GANs are computational structures that pit two neural networks against one another to generate new, synthetic examples of data that can pass for real data. They're commonly employed in picture, video, and speech creation.