
Machine Learning
Basic Interview Q&A

1. Differentiate between Training Sets and Test Sets?
Training Set
- The data in the training set are the examples provided to the model to train that particular model.
- Usually, around 70-80% of the data is used for training purposes. The number is completely up to the user. However, having a higher amount of training data than testing data is recommended.
- To train the model, the training set is the labeled data that is used.
Test Set
- The data in the test are used to test the model accuracy of the already trained model.
- The Test Set contains around 20%-30% of the total data. This data is then further used to test the accuracy of the trained model.
- For testing purposes, labeled data is not used at all, however, the results are further verified with the labels.
2. Define Bias and Variance.
Bias
When a model makes predictions, a disparity between the model's prediction values and actual values arises, and this difference is known as bias. Bias is the incapacity of machine learning algorithms like Linear Regression to grasp the real relationship between data points.
Variance
If alternative training data were utilized, the variance would describe the degree of variation in the prediction. In layman's terms, variance describes how far a random variable deviates from its predicted value.
3. You have come across some missing data in your dataset. How will you handle it?
In order to handle some missing or corrupted data, the easiest way is to just replace the corresponding rows and columns, which contain the incorrect data, with some different values. The two most useful functions in Panda for this purpose are isnull() and fillna().
- isnull(): is used to find missing values in a dataset
- fillna(): is used to fill missing values with 0’s
4. Explain Decision Tree Classification.
A decision tree uses a tree structure to generate any regression or classification models. While the decision tree is developed, the datasets are split up into ever-smaller subsets in a tree-like manner with branches and nodes. Decision trees can handle both category and numerical data.
5. How is a logistic regression model evaluated?
One of the best ways to evaluate a logistic regression model is to use a confusion matrix, which is a very specific table that is used to measure the overall performance of any algorithm.
Using a confusion matrix, you can easily calculate the Accuracy Score, Precision, Recall, and F1 score. These can be extremely good indicators for your logistic regression model.
If the recall of your model is low, then it means that your model has too many False Negatives. Similarly, if the precision of your model is low, it signifies that your model has too many False Positives. In order to select a model with a balanced precision and recall score, the F1 Score must be used.
6. To start Linear Regression, you would need to make some assumptions. What are those assumptions?
To start a Linear Regression model, there are some fundamental assumptions that you need to make:
- The model should have a multivariate normal distribution
- There should be no auto-correlation
- Homoscedasiticity, i.e, the dependent variable’s variance should be similar to all of the data
- There should be a linear relationship
- There should be no or almost no multicollinearity present
7. What is multicollinearity and how will you handle it in your regression model?
If there is a correlation between the independent variables in a regression model, it is known as multicollinearity. Multicollinearity is an area of concern as independent variables should always be independent. When you fit the model and analyze the findings, a high degree of correlation between variables might present complications.
There are various ways to check and handle the presence of multicollinearity in your regression model. One of them is to calculate the Variance Inflation Factor (VIF). If your model has a VIF of less than 4, there is no need to investigate the presence of multicollinearity. However, if your VIF is more than 4, an investigation is very much required, and if VIF is more than 10, there are serious concerns regarding multicollinearity, and you would need to correct your regression model.
8. Explain why the performance of XGBoost is better than that of SVM?
XGBoost is an ensemble approach that employs a large number of trees. This implies that when it repeats itself, it becomes better.
If our data isn't linearly separable, SVM, being a linear separator, will need to use a Kernel to bring it to a point where it can be split. Due to there not being an ideal Kernel for every dataset, this can be limiting.
9. Why is an encoder-decoder model used for NLP?
An encoder-decoder model is used to create an output sequence based on a given input sequence. The final state of the encoder is used as the initial state of the decoder, and this makes the encoder-decoder model extremely powerful. This also allows the decoder to access the information that is taken from the input sequence by the encoder.
10. What are Machine Learning and Artificial Intelligence?
Artificial Intelligence is a system of producing intelligent machines that can imitate human intelligence. Machine Learning is training machines to learn from present data and act on these experiences in the future. To know further through in-depth comparison, read machine learning vs artificial intelligence vs deep learning.
11. Differentiate between Deep Learning and Machine Learning?
Machine Learning adopts algorithms to learn from data sets and apply this to future decision making. Deep Learning is a subset of Machine Learning that uses large amounts of data and complex algorithms to create neural networks that can learn and make decisions on their own.
12. What is cross validation?
Cross validation is a concept used to evaluate models’ performances to avoid overfitting. It is an easy method to compare the predictive capabilities of models and is best suitable when limited data is available.
13. What are the types of Machine learning?
There are mainly three types of Machine Learning, viz:
Reinforcement learning: It is about taking the best possible action to maximize reward in a particular scenario. It is used by various software and machines to find the best path it should take in a given situation.
Supervised learning: Using labeled datasets to train algorithms to classify data easily for predicting accurate outcomes.
Unsupervised learning: It uses ML to analyze and cluster unlabeled datasets.
14. Differentiate between Supervised and Unsupervised learning.
Supervised algorithms are those that use labeled data to learn a mapping function from input variables to output variables. Unsupervised algorithms learn from unlabeled data and discover hidden patterns and structures in the data.
15. What is Selection Bias?
Selection Bias is a statistical error that brings about a bias in the sampling portion of the experiment. This, in turn, causes more selection of the sampling portion than other groups, which brings about an inaccurate conclusion.
16. What is the difference between correlation and causality?
Correlation is the relation of one action (A) to another action (B) when A does not necessarily lead to B, but Causality is the situation where one action (A) causes a result (B).
17. What is the difference between Correlation and Covariance?
Correlation quantifies the relationship between two random variables with three values: 0,1 and -1.
Covariance is the measure of how two different variables are related and how changes in one impact the other. Read correlation vs covariance to know about these two and for a further in-depth comparison.
18. What is the difference between supervised and reinforcement learning?
Supervised learning algorithms are trained using labeled data, while reinforcement learning algorithms are trained using a reward function. Supervised learning algorithms are used to predict a given output, while reinforcement learning algorithms are used to maximize a reward by taking a series of actions.
19. What are the requirements of reinforcement learning environments?
State, reward data, agent, and environment. It is entirely different from other machine learning paradigms. Here we have an agent and an environment. The environment refers to a task or simulation; the agent is an algorithm that interacts with the environment and tries to solve it.
20. What different targets do classification and regression algorithms require?
Regression algorithms require categorical and numerical targets. Here, regression finds correlations between dependent and independent variables. It helps predict continuous variables such as market trends and weather patterns.
On the other hand, classification is an algorithm that segregates the dataset into classes on various parameters. Here classification algorithms work to predict the willingness of bank customers to pay their loans, email, or spam classification.
21. What are five popular algorithms used in Machine Learning?
Neural Networks: It is a set of algorithms designed to help machines recognize patterns without being explicitly programmed.
Decision trees: It is a Supervised learning technique where internal nodes represent the features of a dataset, branches represent the decision rules, and each leaf node represents the outcome.
K-nearest neighbor: K-nearest neighbor (KNN) is a supervised learning algorithm used for classification and regression. The algorithm finds the k-nearest data points in the training dataset and uses them to make predictions. It works by calculating the distance between the query point and the k-nearest data points and then uses the labels of these points to make a prediction.
Support Vector Machines (SVM): It is used to create the best line or decision boundary that can segregate n-dimensional space into classes to put the new data point in the correct category quickly.
Probabilistic networks: They are graphical models of interactions among a set of variables, where the variables are represented as nodes of a graph and the interaction as directed edges between the vertices. It allows a compact description of complex stochastic relationships among several random variables.
22. What is the confusion matrix?
The confusion matrix consists of an error matrix table used for concluding the performance of a classification algorithm. It determines the classification models' performance for a given test data set. It has multiple categorical outputs, but it can only be determined if the actual values for test data are known.
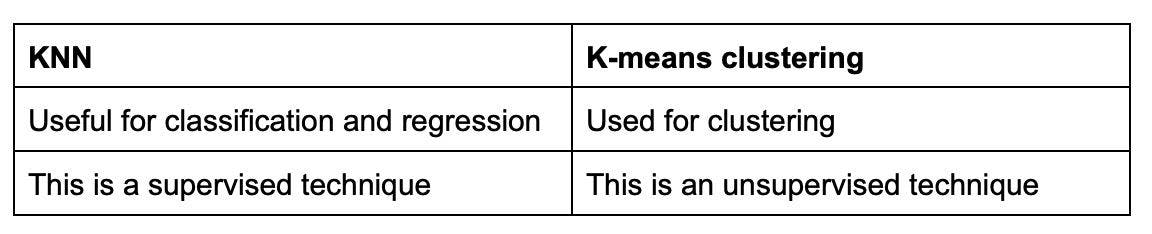
23. List the differences between KNN and k-means clustering.
24. What are the differences between Type I error and Type II error?

25. What is semi-supervised learning?
A semi-supervised learning happens when a small amount of labeled data is introduced to an algorithm. The algorithm then studies that data and uses it on unlabeled data. Semi-supervised learning combines the efficiency of unsupervised learning and the performance of supervised learning.
26. Where are semi-supervised learning applied?
Some areas it is applied include labeling data, fraud detection, and machine translation.
27. What is stemming?
Stemming is a normalization technique that removes any affix joined to a word, leaving it in its base state. It makes text easier to process. It is commonly used in information retrieval, an important step in text pre-processing and text mining applications. Stemming can be used in various NLP tasks such as text classification, information retrieval, and text summarization.
28. What is Lemmatization?
This is a normalization technique that converts a word into a lemma form, or the root word, which is not the stem word. It is a process in which a word is reduced to its base form, but not similar to stemming; it considers the context of the word and produces a valid word. Lemmatization is quite difficult compared to stemming because it requires a lot more knowledge about the structure of a language; it's a much more intensive process than just trying to set up a heuristic stemming algorithm. Lemmatization is often used in natural language processing (NLP) applications to improve text analysis and feature extraction.
29. What is a PCA?
PCA means Principal Component Analysis, and is mainly used for dimension reduction. It is a statistical technique used to reduce the dimensionality of large datasets while retaining as much information as possible. In other words, it identifies patterns and correlations among variables and summarizes them into a smaller set of uncorrelated variables called principal components.
PCA is commonly used in data preprocessing and exploratory data analysis to simplify data visualization, identify outliers, and reduce noise in the data. It is also used in machine learning and pattern recognition applications to improve model performance by reducing the number of features used in the analysis.
30. What are support vectors in SVM (Support Vector Machine)?
Support vectors are the data points in a dataset that are closest to the hyperplane (the line that separates the classes in the dataset) and are used to build the classifier.
31. In terms of access, how are array and linked lists different?
Linked lists allow users to transverse the full linked lists, even up to the element in a sequential access pattern. However, an array provides access to elements directly using their index value.
32. What is P-value?
P-value or probability value indicates the probability of obtaining the observed data or more extreme values by random chance. A small P-value suggests that the observed result is unlikely and that observed data is consistent with the null hypothesis and provides evidence to support the alternative hypothesis.
33. What techniques are used to find resemblance in the recommendation system?
Cosine and Pearson Correlation are techniques used to find resemblance in recommendation systems. Where the Pearson correlation coefficient is the covariance between two vectors divided by their standard deviation, Cosine, on the other hand, is used for measuring the similarity between two vectors.
34. What is the difference between Regression and Classification?
Classification is a concept used to produce discrete results and to classify data into specific regions. On the other hand, regression is used to assess the relationship between independent variables and dependent variables.
35. What does the area under the ROC curve indicate?
ROC stands for Receiver Operating Characteristic. It measures the usefulness of a test where the larger the area, the more useful the test. These areas are used to compare the effectiveness of the tests. A higher AUC (area under the curve) generally indicates that the model is better at distinguishing between the positive and negative classes. AUC values range from 0 to 1, with a value of 0.5 indicating that the model is no better than random guessing, and a value of 1 indicating perfect classification.
36. What is a neural network?
Much like a human brain, the neural network is a network of different neurons connected in a way that helps information flow from one neuron to the other. It is a function that maps input to desired output with a given set of inputs. Structurally, it is organized into an input layer, an output layer, and one or more hidden layers.
37. What is an Outlier?
An outlier is an observation that is significantly different from the other observations in the dataset and can be considered as an error that should be avoided in data analysis. However, they also give insight into special cases in our data at certain times.
38. What is another name for a Bayesian Network?
Casual network, Belief Network, Bayes network, Bayes net, Belief Propagation Network, etc. are some of its other names. It is a probabilistic graphical model that showcases a set of variables and their conditional dependencies.
39. What is ensemble learning?
Ensemble learning is a method that merges multiple machine learning models to create various powerful models. The aim is to provide better performance by combining models rather than sticking to a single model.
40. What is clustering?
Clustering is a process of grouping sets of items into several groups. Items or objects must be similar within the cluster and different from other objects in other clusters. The goal of clustering is to identify patterns and similarities in the data that can be used to gain insights and make predictions. Different clustering algorithms use different methods to group data points based on their features and similarity measures, such as distance or density. Clustering is commonly used in various applications such as customer segmentation, image and text classification, anomaly detection, and recommendation systems.
41. How would you define collinearity?
Collinearity is when two predator variables in a multiple regression share some correlations.
42. What is overfitting?
Overfitting is said to happen when a statistical model observes and learns the details in the training data to the point that it starts negatively impacting the model's performance on new datasets.
43. What is the Bayesian Network?
Bayesian network represents a graphical model between sets of variables. We say it probabilistic because these networks are built on a probability distribution and also use probability theory for prediction and anomaly detection. Bayesian networks are used in for reasoning, diagnostic, anomaly detection, prediction to list a few.
44. What is the time series?
Time series is a particular sequence of data observations in successive order collected over a period. It usually does not need any maximum or minimum time input. It basically forecasts target values based solely on a known history of target values. It is used to predict time-based predictions such as signal processing, engineering domain- communications and control systems, and weather forecasting models.
45. What is dimension reduction in ML?
Dimension reduction is the reduction of variables put under consideration. It lessens the number of features in a dataset while saving as much information as possible. This can be done for various reasons, such as to improve the performance of a learning algorithm, reduce the complexity of a model, or make it easier to visualize the data.
46. What is underfitting?
Underfitting is a type of error in ML models where the model fails to capture the underlying pattern of the data. It occurs when a model is too simplistic and is unable to capture the complexity of the data, leading to poor generalization performance on unseen data. In other words, the model is not complex enough to accurately capture the relationship between the input and output variables. This often leads to high bias and low variance.
47. What is sensitivity?
This is the probability that the prediction outcome of the model is true when the value is positive. It can be described as the metric for evaluating a model’s ability to predict the true positives of each available category.
Sensitivity = TP / TP+FN (i.e. True Positive/True Positive + False Negative)
48. What is specificity?
This is the probability the prediction of the model is negative when the actual value is negative. It can be termed as the model’s ability to foretell the true negative for each category available..
Specificity = TN / TN + FP (i.e. True Negative/True Negative + False Positive)
49. What are the differences between stochastic gradient descent (SGD) and gradient descent (GD)?
Both of these gradients are algorithms used to ascertain the parameters that will minimize a loss function. However, in the case of GB, all training samples are evaluated for each set of parameters. On the contrary, for SGB, one training sample is always evaluated for a set of parameters.
50. What is an Array?
An array is a collection of data elements of the same type, such as integers, strings, or floating-point numbers, stored in contiguous memory locations. Every component of an array is identified by an index that represents its position in the array.
51. What is a linked list?
This is an ordered collection of similar data type elements joined with pointers. It consists of several individual allocated nodes or a series of connected nodes. Each node contains data plus a pointer or the address of the next node in the list.


Wrapping up
ML interview questions cover a wide range of topics which can be challenging for even experienced professionals. We have prepared the above content to help you ace ML engineer interviews because it touches all aspects of machine learning across three levels basic, intermediate, and advanced.
It is also helpful for tech recruiters looking to test or vet machine-learning engineering candidates. Alternatively, tech recruiters can opt for a better route of hiring Machine Learning Engineers through Turing. Hiring with Turing saves time and allows you to hire top Machine Learning engineers from across the globe. If you are a Machine learning engineer, Join Turing and get the opportunity to work with top U.S. companies from your home!
Hire Silicon Valley-caliber Machine Learning developers at half the cost
Turing helps companies match with top quality remote JavaScript developers from across the world in a matter of days. Scale your engineering team with pre-vetted JavaScript developers at the push of a buttton.
Tired of interviewing candidates to find the best developers?
Hire top vetted developers within 4 days.





Leading enterprises, startups, and more have trusted Turing

Check out more interview questions
Hire remote developers
Tell us the skills you need and we'll find the best developer for you in days, not weeks.