Deep Learning vs Machine Learning: The Ultimate Battle
•6 min read
- Software comparisons

Artificial intelligence, machine learning, deep learning - most of us have come across these terms in recent years. How are they related? What, especially, do machine learning and deep learning have in common and how are they different? This article will lift the lid on these two disruptive technologies as well as explore their advantages, constraints, and use cases.
A brief overview of AI, ML and DL
AI
Artificial intelligence (AI) is the bigger domain with innovations in new sectors. All technologies where machines are taught or trained to act/perform like human brains fall under AI.
ML
Machine learning (ML) is a subset of artificial intelligence. Algorithms and models that are trained on available data to predict, classify, and cluster them come under ML. It’s important to note that machine learning models are never explicitly programmed; rather, they learn from patterns of data.
DL
Deep learning (DL) is, in turn, a subset of machine learning. It uses artificial neural networks to work on datasets and perform tasks. The unit cells of these neural networks are neurons, which mimic the functioning of the human brain.
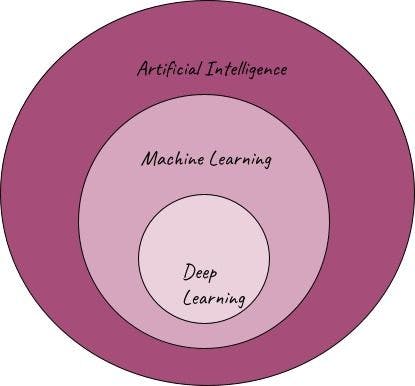
Image source: Author
Major differences between ML and DL
Machine learning uses statistical learning algorithms to find patterns in available data and perform predictions and classifications on new data. ML also comprises both supervised and unsupervised learning.
Deep learning relies on multi-layered neural network models to perform complex tasks. There is a significant difference in the capabilities and applications of both. Understanding them is essential to knowing which to use in projects and get the best results.
- Data characteristics
Deep learning models are best used on large volumes of data, while machine learning algorithms are generally used for smaller datasets. In fact, using complex DL models on small, simple datasets culminate in inaccurate results and high variance - a mistake often made by beginners in the field.
DL algorithms are capable of learning from unlabeled or unstructured data, whereas ML models generally learn to process structured data.
- Complexity
Deep learning algorithms are far more complex than machine learning models. DL is best suited for handling high-complexity decision-making-like recommendations, speech recognition, image classification, etc. In essence, large-scale problem-solving.
- Hardware requirement
Due to their complexity, deep learning algorithms require powerful high-end hardware, including GPUs (graphical processing units), for implementation. By comparison, machine learning algorithms have low-end hardware requirements, making the overall cost lower.
- Computation time and cost
The training time associated with DL models is longer than for ML models. As DL involves complex mathematical computations, execution time can range from hours to weeks. On the other hand, the execution period of ML models can span seconds to hours. Hence, the computation cost and resources are lower for ML than for DL models.
- Need for feature engineering
Feature engineering is the task of selecting important and relevant features to decide a model's input parameters. Discarding irrelevant features is essential for reducing dimension and complexity.
In the machine learning pipeline, feature engineering comes right after data cleaning and visualization where the expertise of data scientists is required. This step also involves engineering new features to boost model performance.
Alternatively, there is no need for explicit feature engineering in the deep learning pipeline. The neural network architecture learns features from the data by itself and captures all non-linear relationships.
Applications and approaches
ML and DL algorithms are implemented using different approaches. Usually, machine learning algorithms are applied to data in tabular formats, while deep learning is applied when data is unstructured in the form of text, speech, images, etc.
There is a basic difference in the approach adopted by machine learning and deep learning. In the ML pipeline, a problem is divided into pieces and solved individually to provide the end result. Deep learning, on the other hand, aims to solve it from end-to-end.
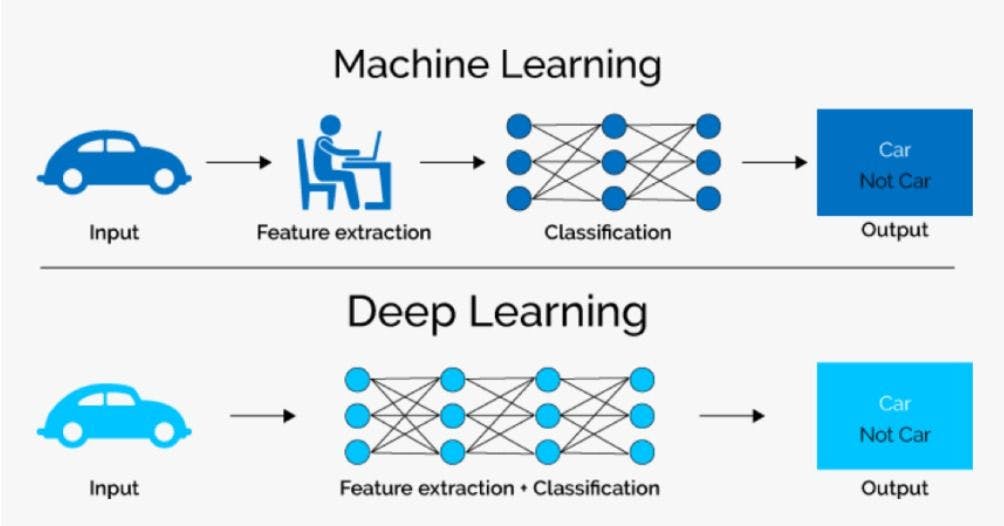
Consider the case of a simple image classification of a car in the figure above. In machine learning, the input image is processed, features are extracted, and classification is done. Conversely, deep learning performs both steps together.
Types of Machine Learning algorithms
ML algorithms fall under three major categories: supervised learning, unsupervised learning, and reinforcement learning.
1. Supervised learning
These algorithms learn patterns from properly labeled data, i.e., the ‘target’ variable and the features are clearly defined. For example, consider a song popularity prediction problem statement. The values of the target ‘popularity metric’ are available as a part of the training dataset.
Major applications under supervised learning include regression-based prediction and classification problems. Classifying data points into defined categories using XGBoost and decision trees is a common use case.
2. Unsupervised learning
Such algorithms can be used on datasets where there is a lack of labeled data. The available data is provided as input but there are no clear targets defined. The models independently find similarities and patterns in the data and classify/group them.
A common example is clustering and recommendation systems. News content is clustered through this way to suggest similar kinds of topics for users. Market segmentation is also another prominent example.
3. Reinforcement learning
This category of algorithms learn through experimentation, and success and failure. When a model performs well (better accuracy/prediction), it is rewarded. If it performs poorly, it is punished. Over time, it learns and adapts to perform in the right direction.
This feedback-based learning process also falls under deep learning technology. Prominent applications of reinforcement learning in real life include self-driving cars, personalized games, etc.
Types of Deep Learning neural networks
There are three major types of widely-used neural networks in deep learning: convolutional neural networks (CNNs), recurrent neural networks (RNNs), and generative adversarial neural networks (GANs).
1. CNNs
These networks have convolutional and fully connected layers. They are specifically used in image datasets as the convolutional layers are capable of extracting essential features from images with less computation cost and time. They are widely applied to image classification and object detection use cases.
2. RNNs
In RNNs, feedback connections are used to learn patterns. The networks are applied to situations where the context of previous results is relevant for the prediction of the next.
One such example is language-based models in natural language processing (NLP). It has advancements like long short-term memory (LSTM) that remember previous sequences for current predictions in translation and text generation tasks. RNNs are also used in voice recognition and time series datasets.
3. GANs
There are instances when sufficient training data may not be available. In these cases, GANs can be used to generate similar data (images, texts) to that of the provided input data.
GANs consist of two main parts: generator and discrimintor. The generator tries to create duplicate data similar to the original pattern, while the discriminator attempts to differentiate between the original data and the generated duplicate data. Both are trained parallel.
Advantages and limitations of ML and DL
- A significant advantage of deep learning models is that they can be tested to produce results in a very short span of time, contrary to the high training period needed for machine learning models.
- Neural networks provide flexibility in the structure of inputs and outputs, which machine learning lacks. They are even capable of capturing spatial and temporal relationships between features.
- Deep learning models improve when the size of data increases, whereas the performance of machine learning models would deteriorate.
- The hardware requirement for deep learning is expensive while DL implementation itself requires in-depth expertise.
Machine learning is widely used in the automation of business activities. Deep learning can be used in sectors like social media analysis, banking, etc., where data is available in massive volumes. Google’s DeepMind and Netflix’s recommendation systems are excellent products of DL technology.