
Big Data
Basic Interview Q&A

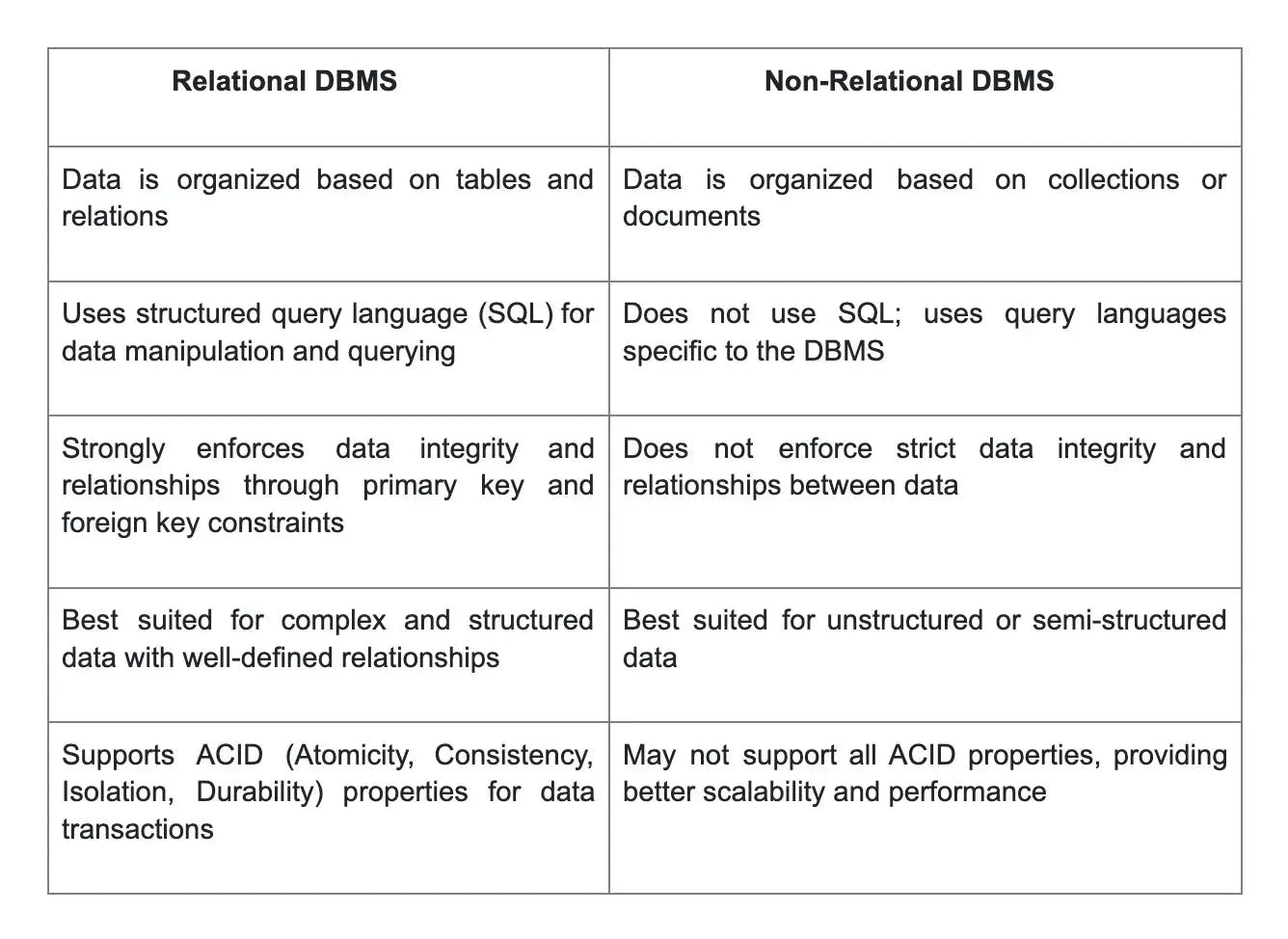
1. Differentiate between relational and non-relational database management systems.
2. What is data modeling?
Data modeling is the process of creating a conceptual representation of data structures and relationships between different data elements. It involves identifying the required data elements, determining their relationships, and mapping out how they will be stored and accessed in a database.
Here are some key points to note:
- Data modeling helps ensure that data is accurately organized and stored, which leads to efficient retrieval and manipulation of data.
- It provides a clear view of the data entities and how they relate, which is important for data analysis, decision-making, and integration with other systems.
- Data models can be either high-level or detailed, depending on the project requirements.
- Techniques used in data modeling include entity-relationship diagrams, data flow diagrams, and Unified Modeling Language diagrams.
- Data modeling can help identify areas where data quality can be improved, and data inconsistencies can be detected.
- Data modeling is a key part of the database design process and also feeds into application development, system integration, and architecture planning.
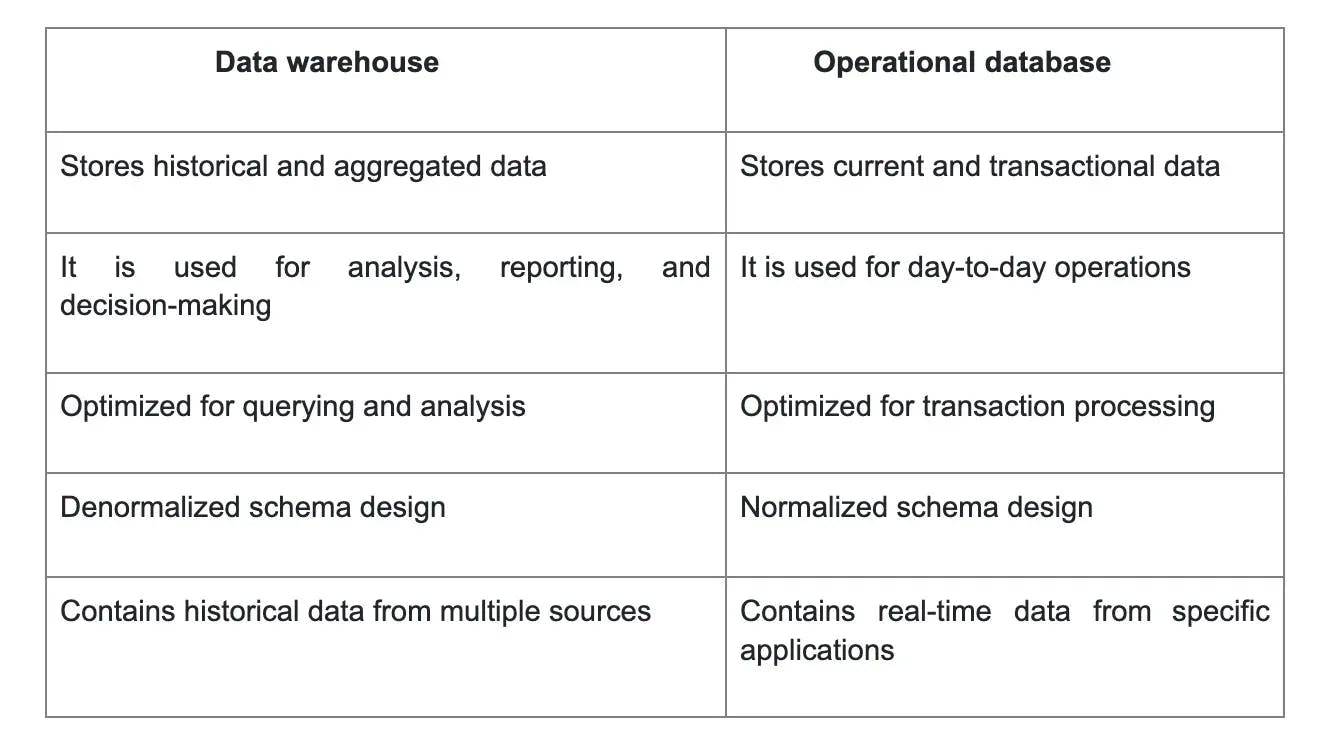
3. How is a data warehouse different from an operational database?
4. What are the big four V’s of Big Data?
- Volume refers to the sheer amount of data being generated and collected. With the explosion of digital devices and online platforms, there is an unprecedented amount of data being generated every second.
- Variety refers to the diverse types and formats of data. It includes structured data (like databases and spreadsheets) as well as unstructured data (like emails, social media posts, and videos).
- Velocity refers to the speed at which data is being generated and needs to be processed. Real-time data streams and sensors contribute to the velocity of data.
- Veracity refers to the quality and trustworthiness of the data. It is important to ensure the accuracy and reliability of data sources to make informed decisions.
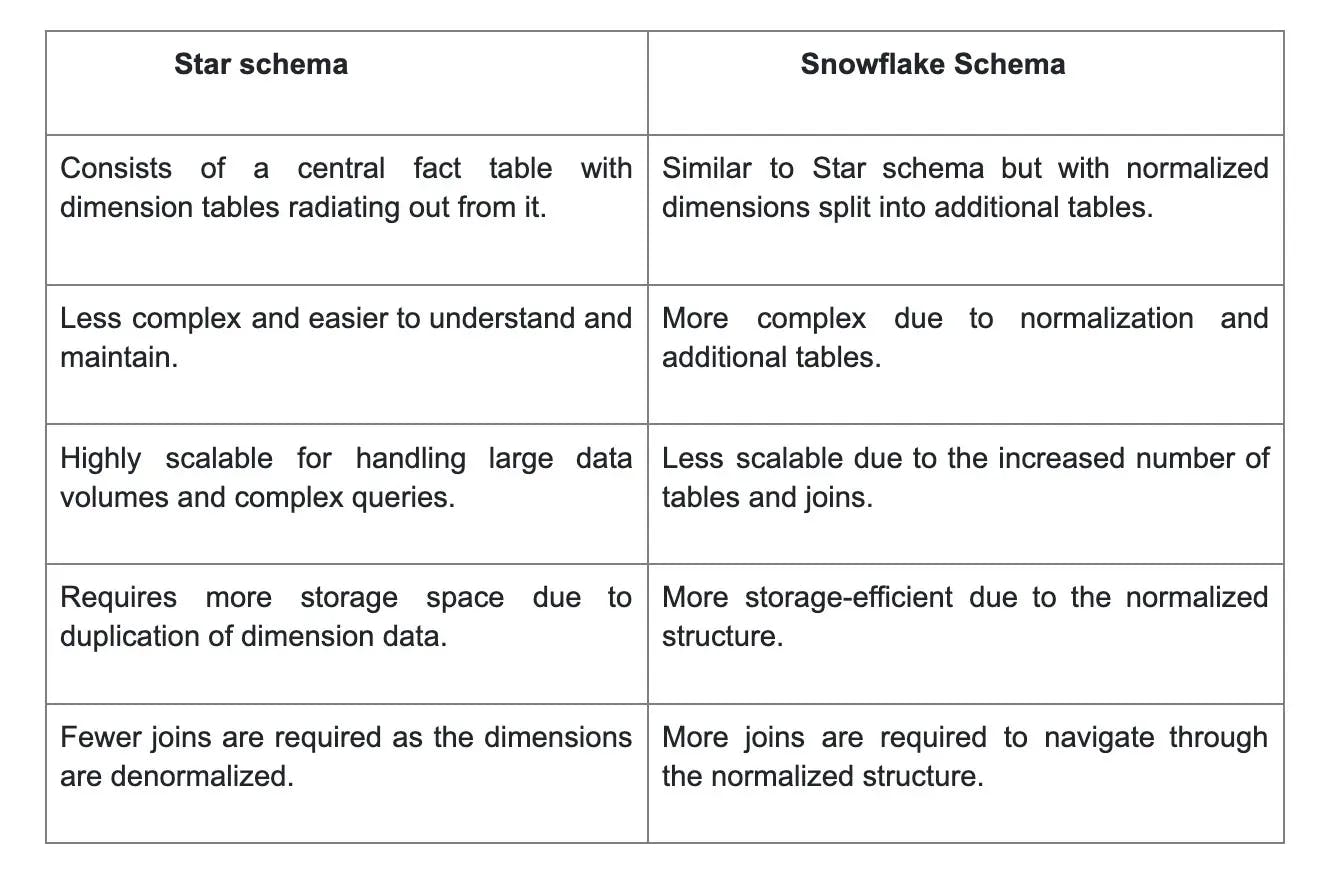
5. Differentiate between Star schema and Snowflake schema.
6. Mention the big data processing techniques.
This question makes a frequent appearance across Big Data engineer interview questions.
The following are the techniques of big data processing:
- Processing of batches of big data
- Stream processing of big data
- Big data processing in real-time
- Map-reduce
The above methods help in processing vast amounts of data. When batches of big data are processed offline, the process happens at full scale and even helps tackle random business intelligence issues. When big data is processed using real-time streams of data, the most recent data slices are used to profile data and pick outliers, expose impostor transactions, monitor for safety precautions, etc. This becomes even more challenging when large data sets need to be processed in real-time. It’s because very large data sets must be analyzed within seconds. High parallelism must be used to process data to achieve this.
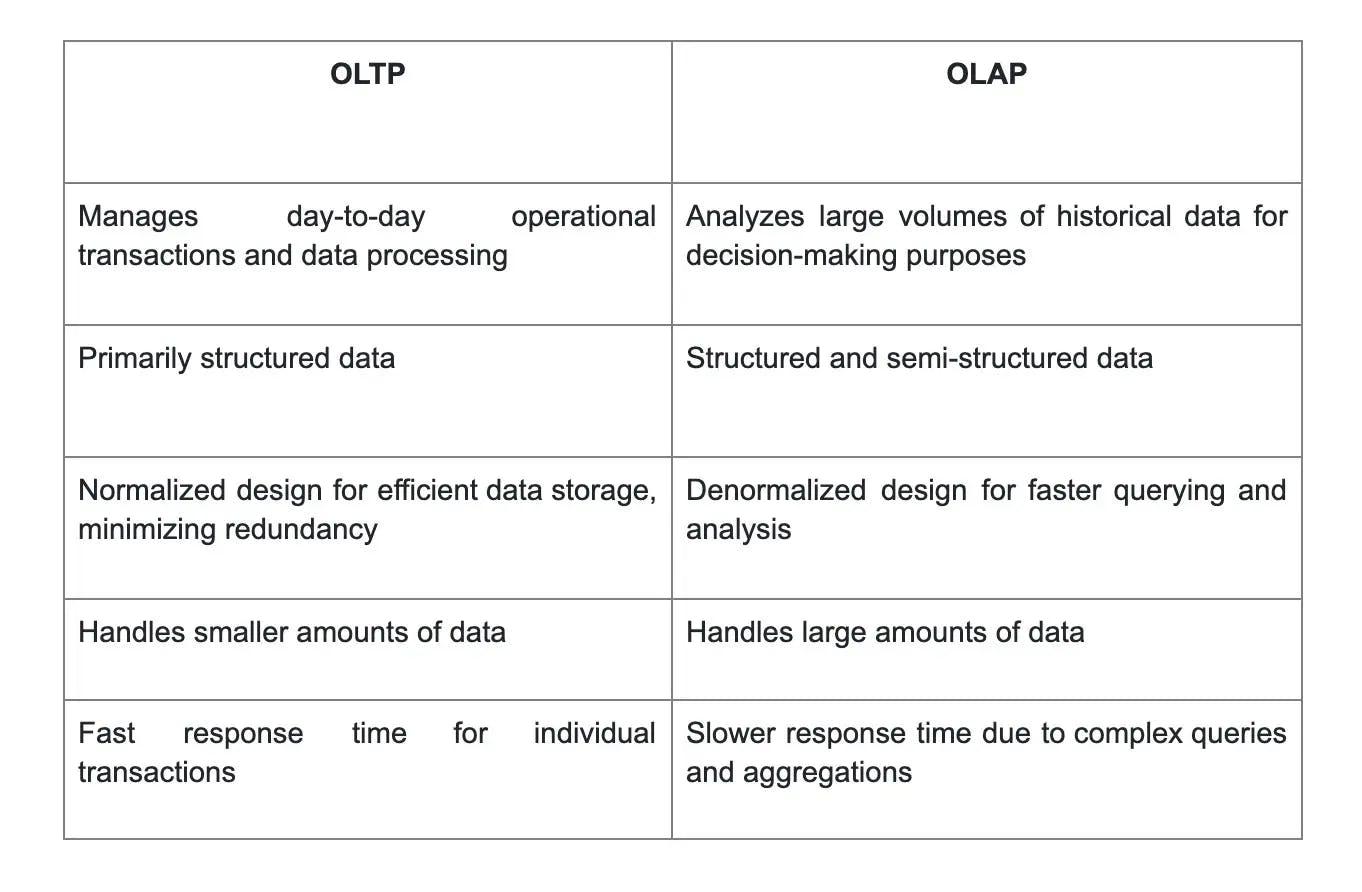
7. What are the differences between OLTP and OLAP?
8. What are some differences between a data engineer and a data scientist?
Data engineers and data scientists work very closely together, but there are some differences in their roles and responsibilities.
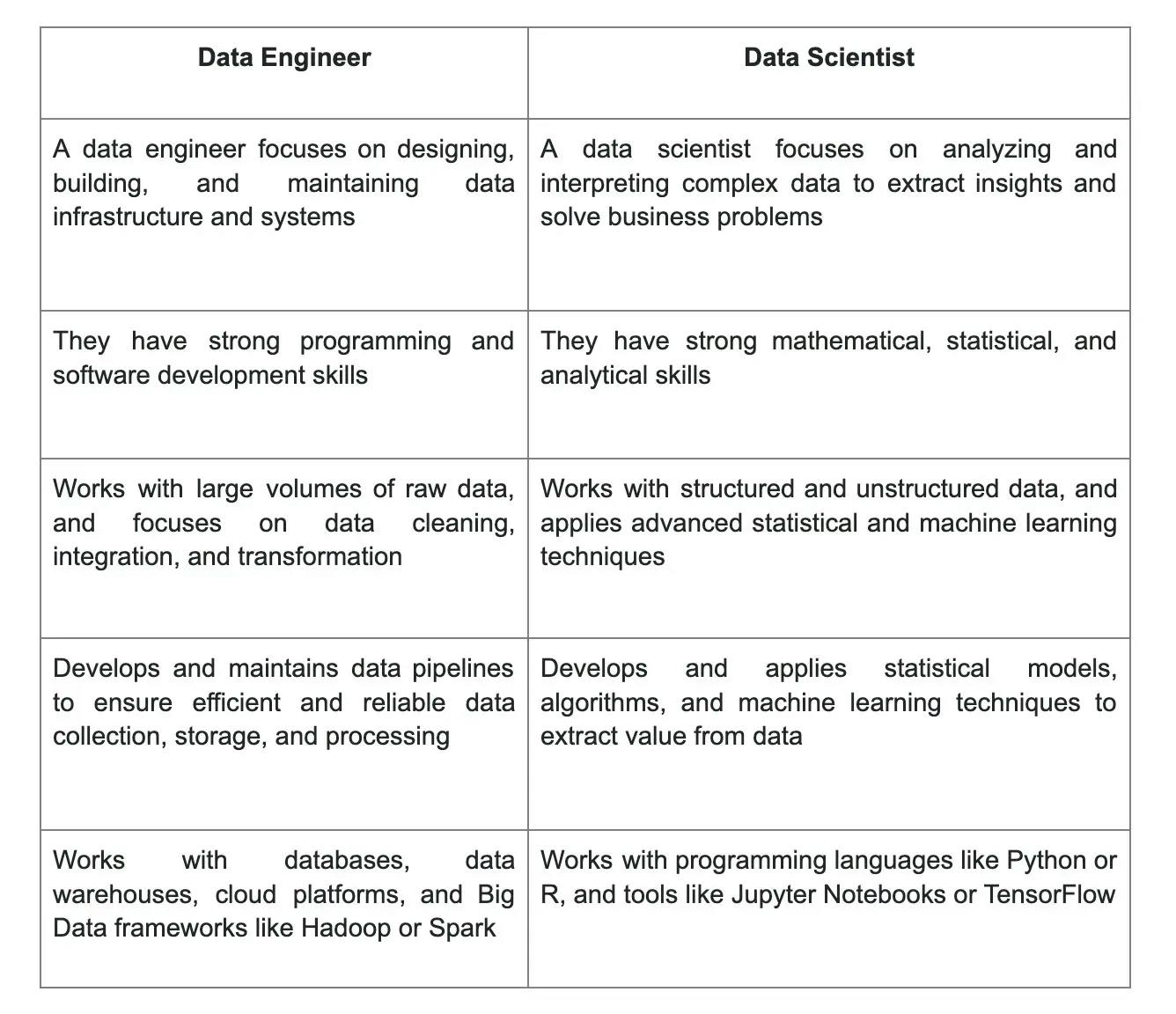
9. How is a data architect different from a data engineer?
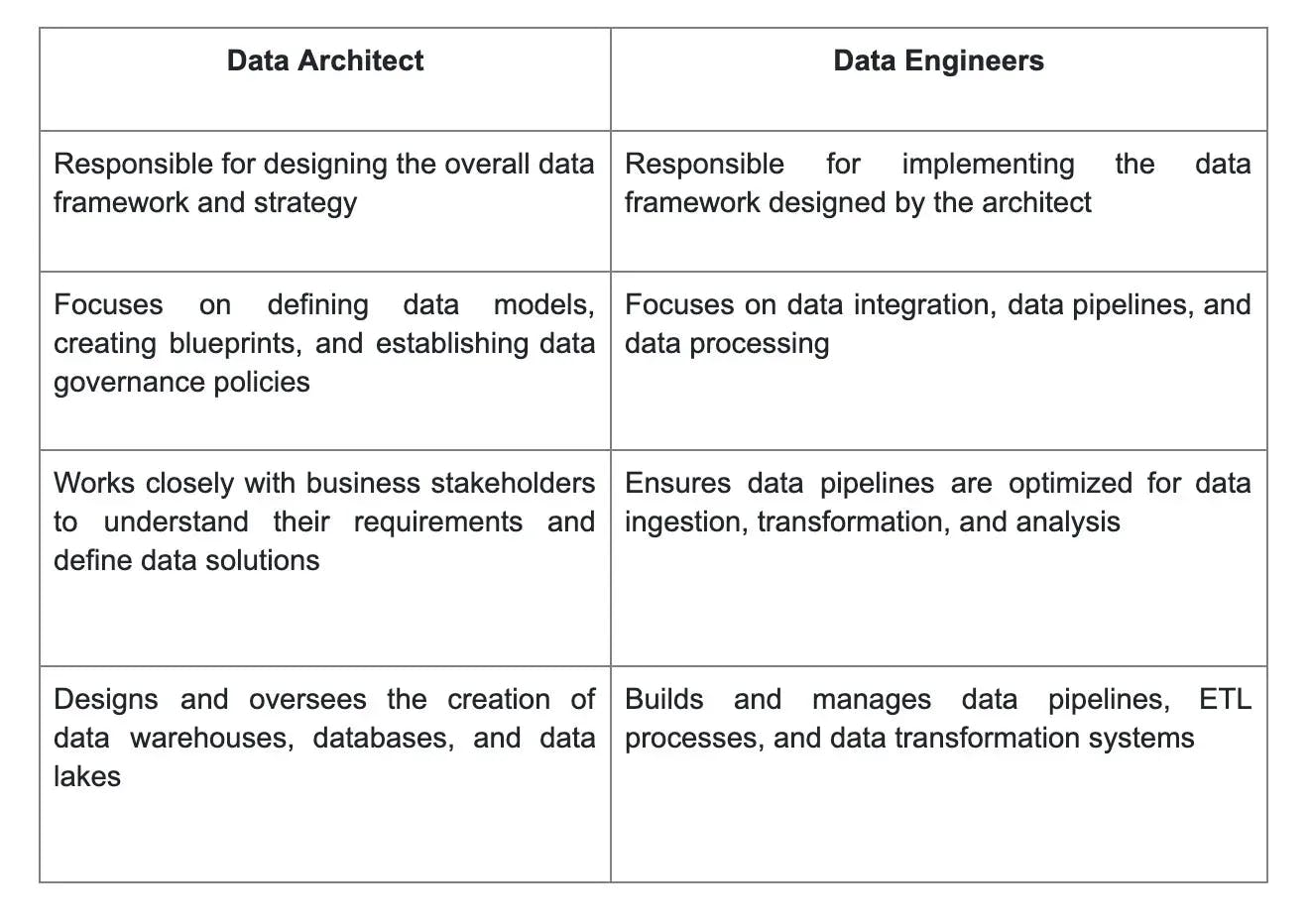
10. Differentiate between structured and unstructured data.
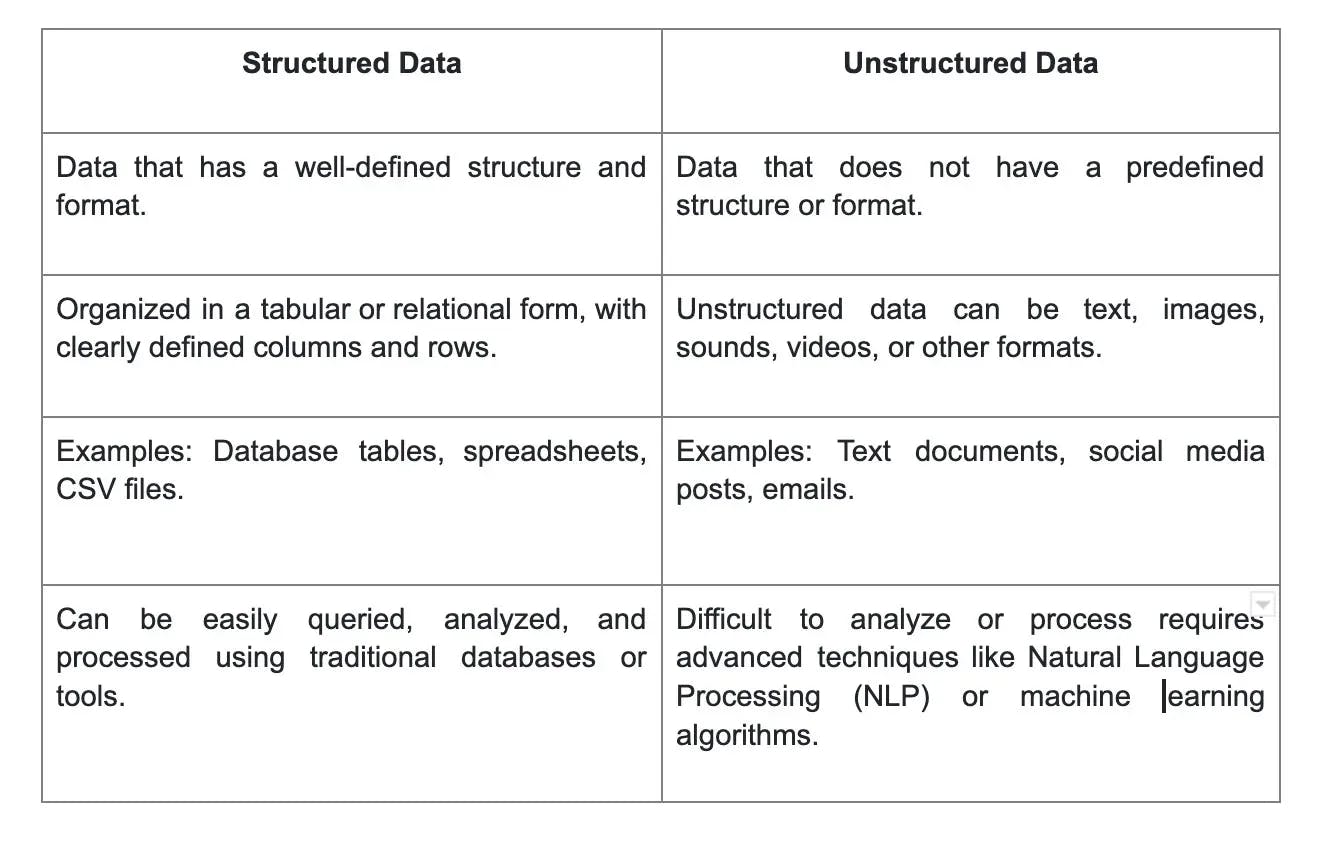
11. How does Network File System (NFS) differ from Hadoop Distributed File System (HDFS)?

12. Talk about the different features of Hadoop.
The different features of Hadoop are as follows:
- Open Source: As an open-source platform, Hadoop offers the ability to rewrite or change the code as per user needs and analytics requirements.
- Scalability: Hadoop offers scalability by supporting adding hardware resources to the new nodes of network computers.
- Data recovery: Because Hadoop keeps duplicate data across multiple computers on the network, it is possible to recover data in case of any faults or failures.
- Data locality: In Hadoop, the data need not be moved for processing. Instead, the computation can take place where the data is, thereby speeding up the process.
13. What is meant by feature selection?
Feature selection is the process of selecting a subset of relevant features that are useful in predicting the outcome of a given problem.
In other words, it is the process of identifying and selecting only the most important features from a dataset that have the maximum impact on the target variable. This is done to reduce the complexity of the data and make it easier to understand and interpret.
Feature selection is vital in machine learning models to avoid overfitting and to improve the accuracy and generalization of a predictive model. There are various feature selection techniques available, which involve statistical tests and algorithms to evaluate and rank features.
14. What are the Port Numbers for NameNode, Task Tracker, and Job Tracker?
The Port Number for these are as follows:
- The Port Number for NameNode is Port 50070
- The Port Number for Task Tracker is Port 50060
- The Port Number for Job Tracker is Port 50030
15. How can missing values be handled in Big Data?
A missing value can be handled with the following processes:
- Deletion: One option is to simply delete the rows or columns with missing values. However, this can result in significant data loss.
- Imputation: This involves replacing missing values with estimated values. Popular imputation methods include mean, median, and mode imputation.
- Predictive modeling: Machine learning algorithms can be used to predict missing values based on existing data. This approach can provide more accurate imputations.
- Multiple imputation: This technique generates multiple imputed datasets and combines them for analysis. It takes into account the uncertainty associated with missing values.
16. How do you deploy Big Data solutions?
The process for deploying Big Data solutions is as follows:
- Ingestion of data: The first part of the process is to collect and stream data from various sources such as log files, SQL databases, and social media files. The three main challenges of data ingestion are large table ingestion, the capture of change data, and the changes of Schema in the source.
- Storage of data: The second step is to store or load the data that has been extracted from various sources in HDFS or NoSQL by the HBase. Applications can easily access and process this stored data.
- Processing of data: The next and very important step is to process the data. MapReduce and Spark framework help in analyzing large scale - petabytes and zettabytes of data.
- Visualization and reporting: The last step of the process is perhaps the most important. Once the data has been analyzed, it is critical to present it in a digestible format for people to understand.
17. What are the different Big Data processing techniques?
There are six main types of Big Data processing techniques.
- A/B testing: In this method, a control group of data is compared with several test groups. This helps in identifying what changes or treatments can help improve the objective variable. For example, for an e-commerce site, what kinds of copy, images, and layout might give an impetus to the conversion rates. Big Data analytics can help in this case, however, the data sizes must be big enough to get meaningful differences to effect change.
- Data integration and data fusion: This method involves combining techniques for analyzing and integrating data from multiple sources. This method is helpful as it gives more accurate results and insights when compared to getting insights based on a single data source.
- Data mining: This is a common tool in Big Data analytics. In this method, statistical and machine learning models within database management systems are combined to extract and extrapolate patterns from large data sets.
- Machine learning: Machine learning is an artificial intelligence technique that helps in data analysis. In machine learning, data sets are used for training computer algorithms for producing assumptions and predictions that are hitherto impossible for humans to attain.
- Natural language processing or NLP: NLP is based on computer science, artificial intelligence, and linguistics and uses computer algorithms to understand human language to derive patterns.
- Statistics: One of the oldest methods of processing data, statistical models help in collecting, organizing, and interpreting data from surveys and experiments.
18. What is the purpose of the JPS command in Hadoop?
JPS stands for Java Virtual Machine Process Status. The JPS command helps in checking whether certain daemons are up or not. One can see all processes based on Java using this command. To check all the operating nodes of a host, the JPS command must be run from the root.
19. What is meant by outliers?
Outliers are data points that significantly deviate from the typical pattern or distribution of a data set. These values can be very high or very low compared to other values in the data set.
Outliers can occur due to various reasons such as measurement errors, data entry mistakes, or genuinely unusual or extreme events. These exceptional values have the potential to affect the overall analysis and interpretation of the data.
It is important to identify and handle outliers appropriately, as they can distort statistical measures, impact the accuracy of predictive models, or impact the validity of conclusions drawn from the data.
20. What is meant by logistic regression?
Logistic regression is a statistical technique used to predict the probability of a binary outcome. It is commonly used when the dependent variable is categorical, such as yes/no or true/false.
The goal of logistic regression is to find the best-fitting model that describes the relationship between the independent variables and the probability of the outcome.
Unlike linear regression, logistic regression uses a logistic function to transform the linear equation into a range of 0 to 1, representing the probability of the outcome. This makes it suitable for predicting categorical outcomes and determining the impact of independent variables on the probability of an event occurring.
21. Briefly define the Star Schema.
The Star Schema is a popular data modeling technique used in data warehousing and business intelligence. It is characterized by a central fact table surrounded by dimension tables. The fact table represents the core measures or metrics of the business, while the dimension tables provide context and descriptive attributes.
The Star Schema is called so because the structure resembles a star with the fact table at the center and the dimension tables branching out like rays. This design allows for easy and fast querying and aggregation of data, making it ideal for complex analytical tasks in large datasets.
22. Briefly define the Snowflake Schema.
The Snowflake Schema is a type of data model used in data warehousing that organizes data in a highly normalized manner. It is an extension of the Star Schema, where each dimension table is normalized into multiple dimension tables.
In a Snowflake Schema, the dimension tables are further normalized into sub-dimension tables. This normalization allows for more efficient data storage and provides a clearer representation of the data relationships.
While the Snowflake Schema offers advantages in terms of data integrity and storage optimization, it can also lead to increased complexity in queries due to the need for more joins between tables.
23. What is the difference between the KNN and k-means methods?
KNN is a supervised learning algorithm used for classification or regression tasks. It finds K-nearest data points in the training set to classify or predict the output for a given query point. KNN considers the similarity between data points to make predictions.
On the other hand, k-means is an unsupervised clustering algorithm. It groups data points into K clusters based on their similarity. The similarity is measured by minimizing the sum of squared distances between data points and their cluster centroids.
24. What is the purpose of A/B testing?
A/B testing, also known as split testing, is a method of comparing two versions of a website, mobile application, or marketing campaign to determine which one performs better.
The main purpose of A/B testing is to scientifically evaluate the impact of changes to a product or marketing strategy. By randomly dividing a user base into two or more groups, A/B testing allows businesses to test and optimize various elements of their website or campaign, such as headlines, images, and calls-to-action, to see which version leads to more conversions or sales.
This helps businesses make data-driven decisions and improve their overall performance and ROI.
25. What do you mean by collaborative filtering?
Collaborative filtering is a method used in recommender systems, which analyze large sets of data to make personalized recommendations. It works by finding similarities between users based on their past interactions and preferences.
Instead of relying solely on item characteristics, collaborative filtering considers the opinions and actions of a community of users to make accurate predictions about an individual user's preferences.
By leveraging the collective wisdom of the community, collaborative filtering can provide valuable recommendations for products, movies, music, and more. This approach is widely used in e-commerce platforms and content streaming services to enhance the user experience and drive customer satisfaction.
26. What are some biases that can happen while sampling?
There are several biases that can occur when taking a sample from a population, including selection bias, measurement bias, and response bias. Selection bias is when individuals are chosen for the sample in such a way that it is not truly representative of the population.
Measurement bias occurs when the measurement tool used is inaccurate or doesn't fully capture the variable being studied. Response bias is when participants in the study do not respond truthfully.
For example, when participants give socially desirable answers, rather than their true responses. Addressing and controlling for these biases is essential to obtaining reliable and valid results from samples.
27. What is a distributed cache?
A distributed cache is a type of caching system that allows for the storage of frequently accessed data across a large network of interconnected machines. This is done in order to minimize the amount of data that needs to be retrieved from a centralized database or storage system, which can reduce network lag and improve overall system performance.
Distributed caches are often used in large-scale web applications and distributed systems in order to provide quick access to frequently used data. By distributing data in this way, applications can scale more effectively by balancing the load across multiple machines. Some popular examples of distributed cache systems include Redis, Hazelcast, and Memcached.
28. Explain how Big Data and Hadoop are related to each other.
Big Data and Hadoop are closely related, as Hadoop is a popular technology for processing and analyzing large datasets known as Big Data.
Big Data refers to the enormous amount of structured and unstructured data that organizations collect and analyze to gain insights and make informed decisions. Big Data is characterized by its volume, velocity, and variety.
Hadoop is an open-source framework used to store and process Big Data. It enables distributed processing of large datasets across clusters of computers. Hadoop uses a distributed file system called Hadoop Distributed File System (HDFS) to store data and the MapReduce programming model to process and analyze the data in parallel.
29. Briefly define COSHH.
COSHH, which stands for Control of Substances Hazardous to Health, is a set of regulations that outlines the measures to be taken in order to protect workers from the harmful effects of hazardous substances. These substances can include chemicals, fumes, dust, and other substances that have the potential to cause harm to health.
COSHH regulations require employers to assess the risks posed by hazardous substances, implement control measures to minimize exposure, provide adequate training and information to employees, and monitor and review the effectiveness of these measures.
Overall, the goal of COSHH is to ensure the well-being and safety of workers in environments where hazardous substances are present.
30. Give a brief overview of the major Hadoop components.
- Hadoop Distributed File System (HDFS): A distributed storage system that allows data to be stored across multiple machines in a cluster
- MapReduce: A programming model that allows for parallel processing of large datasets by breaking them into smaller, manageable tasks and distributing them across the cluster.
- YARN: Yet Another Resource Negotiator, which manages resources in the cluster and schedules tasks for efficient execution.
- Hadoop Common: The utilities and libraries shared by other Hadoop components.
- Hadoop Ecosystem: A set of additional tools and frameworks that work with Hadoop, such as Hive, Pig, and Spark.
31. What is the default block size in HDFS, and why is it set to that value? Can it be changed, and if so, how?
The default block size in HDFS is 64 MB. It is set to this value for several reasons:
- Efficiency: Larger block sizes reduce the amount of metadata overhead compared to smaller block sizes. By having larger blocks, HDFS reduces the number of blocks and decreases the storage overhead associated with block metadata storage.
- Reduced network overhead: HDFS is designed to handle large files, including those in the terabyte or petabyte range. With larger block sizes, the number of blocks needed to store a file is reduced, resulting in reduced network overhead when reading or writing large files.
- Continuous data streaming: HDFS is optimized for the processing of large data sets. With larger block sizes, streaming operations can be performed more efficiently as the data can be read or written in larger, contiguous chunks.
Yes, the block size in HDFS can be changed. The block size can be set while creating a file or changing an existing file's block size. It can be specified using the -D option with the dfs.blocksize parameter in the hadoop fs command. For example, to set the block size to 128 MB, you can use the command hadoop fs -D dfs.blocksize=134217728 -put <local_file> <hdfs_path>.
32. What methods does Reducer use in Hadoop?
The Reducer is a crucial component in the Hadoop framework for Big Data processing and analysis. Once data has been mapped out by the MapReduce system, the Reducer processes and aggregates data to produce the final result.
The primary method used by the Reducer is the Shuffle and Sort process, which involves grouping and sorting intermediate key-value pairs based on the key. This process ensures that all values with the same key end up in the same Reducer for aggregation.
The Reducer then applies a user-defined reduce function to data and reduces each group of intermediate values to a smaller set of summary records. By applying different reduce functions, the Reducer can generate a variety of results beyond mere counts or sums of grouped data.
33. What are the various design schemas in data modeling?
- Relational Schema: This schema organizes data into tables with defined relationships between them, using primary and foreign keys.
- Dimensional Schema: This schema is used in data warehousing and organizes data into fact tables (measures) and dimension tables (attributes).
- Star Schema: A type of dimensional schema, the star schema consists of one central fact table connected to multiple dimension tables.
- Snowflake Schema: This schema extends the star schema by normalizing dimension tables, resulting in a more normalized structure.
- Graph Schema: This schema represents data as nodes and relationships between them, ideal for representing complex interconnectivity.
34. What are the components that the Hive data model has to offer?
- Tables: Hive allows you to define structured tables that store data in a tabular format.
- Databases: You can organize tables into separate databases to manage and categorize your data effectively.
- Partitions: Hive enables you to divide large tables into smaller partitions based on certain criteria, improving query performance.
- Buckets: You can further optimize data storage and querying by dividing partitions into smaller units called buckets.
- Views: Hive allows you to create virtual tables known as views, which provide subsets of data for easier analysis.
- Metadata: Hive stores metadata about tables, databases, and other objects to facilitate data management and discovery.
35. Differentiate between *args and **kwargs.
*args is a special syntax in Python used to pass a variable number of non-keyworded arguments to a function. The *args parameter allows you to pass any number of arguments to a function. Inside the function, these arguments are treated as a tuple.
Similar to *args, **kwargs is a special syntax used to pass a variable number of keyword arguments to a function. The **kwargs parameter allows you to pass any number of keyword arguments to a function. Inside the function, these arguments are treated as a dictionary, where the keys are the keyword names and the values are the corresponding values passed.
36. What is the difference between “is” and “==”?
In Python, "is" tests for object identity while "==" tests for object equality.
"is" checks if two objects refer to the same memory location, which means they must be the same object. On the other hand, "==" checks if two objects are equal, but they don't necessarily have to be the same object.

37. How is memory managed in Python?
In Python, memory management is handled automatically by the Python interpreter. It uses a technique called "reference counting" to keep track of objects and determine when they are no longer needed. When an object's reference count drops to zero, the memory allocated is freed.
In addition to reference counting, Python also uses a garbage collector to handle circular references through reference counting. The garbage collector periodically checks for and collects unused objects to reclaim memory.
This automated memory management system eliminates the need for manual memory management, making Python a convenient language to work with.
38. What is a decorator?
A decorator is a design pattern in Python that allows you to add new functionality to an existing class or function. It provides a way to modify the behavior of the object without changing its implementation.
In Python, decorators are implemented using the "@" symbol followed by the name of the decorator function. Decorators can be applied to functions, methods, or classes to enhance their features or modify their behavior.
They are commonly used for tasks such as logging, timing, caching, and validation. Decorators help in keeping the code modular and reusable by separating the concern of additional functionality from the main logic.
39. Are lookups faster with dictionaries or lists in Python?
When it comes to lookups, dictionaries are typically faster than lists in Python. The reason behind this is dictionaries use a hash table implementation, which allows for constant time lookups (O(1)).
On the other hand, lists use indexing to access elements, which requires iterating through the list until the desired element is found. This results in linear time complexity (O(n)).
So, if you need to perform frequent lookups, it is more efficient to use dictionaries. However, if the order of elements is important or you need to perform operations like sorting, lists are a better choice.
40. How can you return the binary of an integer?
One way to return the binary of an integer is to use the built-in bin() function in Python. This function takes an integer as an argument and returns a string representation of that integer in binary format.
For example, bin(5) would return '0b101', which represents the binary value of 5. If you want to remove the '0b' prefix from the returned string, you can simply slice the string like this: bin(5)[2:]. This would return '101', which is the binary representation of 5.
Overall, using the bin() function is a simple and efficient way to convert integers to binary format in Python.
41. How can you remove duplicates from a list in Python?
- Convert the list to a set: set_list = set(my_list)
- Convert the set back to a list: new_list = list(set_list)
This method works because sets cannot contain duplicate elements. By converting the list to a set, all duplicates are automatically removed. Now, new_list will contain the list without any duplicates.
42. What is the difference between append and extend in Python?
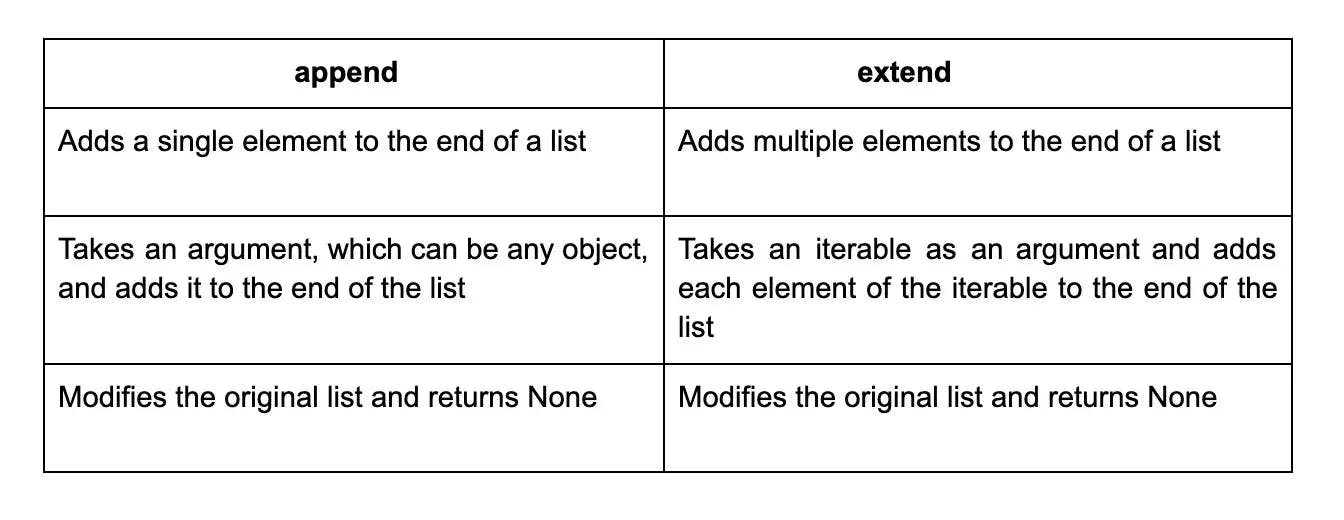
43. When do you use pass, continue, and break?
- Pass is a placeholder statement used when you don't want to take any action within a block of code. It is often used as a placeholder for future implementation.
- Continue is used in loops to skip the remaining statements in the current iteration and move on to the next iteration. It is typically used to skip certain conditions or to filter elements from a list.
- Break is also used in loops, but it completely exits the loop, regardless of any remaining iterations. It is commonly used to terminate a loop based on a specific condition.
Understanding when to use pass, continue, and break will help you control the flow of your Python programs effectively.
44. How can you check if a given string contains only letters and numbers?
To check if a given string contains only letters and numbers, you can use regular expressions. Regular expressions allow you to perform pattern matching within strings.
In this case, you can use the match function and the regular expression /^[a-zA-Z0-9]+$/ to check if the string contains only letters (both uppercase and lowercase) and numbers. If the match function returns a match, then the string contains only letters and numbers. If it returns null, then the string contains other characters.
45. Mention some advantages of using NumPy arrays over Python lists.
NumPy is a Python package that is widely used for scientific computing. One of its distinct features is the use of arrays for data storage and manipulation instead of Python's built-in lists. NumPy arrays have several advantages over Python lists.
Firstly, they are optimized for efficiency and can handle large datasets much faster than lists. They also have a fixed size and hence, take up less memory compared to lists. NumPy arrays also allow for broadcasting, which allows for element-wise operations that can save time and lead to more concise code.
Furthermore, NumPy arrays also have a wide range of mathematical functions and operations that can be performed on them.
46. In Pandas, how can you create a dataframe from a list?
In Pandas, one can create a dataframe from a list by using the pd.DataFrame function. This function allows you to specify a list as the data source for the dataframe, as well as define the column names and index labels for the dataframe.
To do this, create a nested list containing the data values of the dataframe, and pass them into the pd.DataFrame function. Additionally, you can use the columns parameter to specify the column names and the index parameter to specify the index labels.
Overall, using the pd.DataFrame function on a list is a quick and easy way to generate a basic dataframe in Pandas.
47. In Pandas, how can you find the median value in a column “Age” from a dataframe “employees”?
To find the median value of a column "Age" in a pandas dataframe named "employees", you can use the "median()" method. Here is an example code snippet to achieve this:

This code selects the "Age" column from the dataframe using the indexing operator and then applies the "median()" method to calculate the median value. The result is stored in a variable called "median_age" and then printed using the "print()" function.
48. In Pandas, how can you rename a column?
To rename a column in Pandas, you can use the rename method. This method allows you to rename a single column or multiple columns in the data frame.
To rename a single column, you first need to select the column using its original name. You can then call the rename method and pass in a dictionary with the new column name as the key and the original column name as the value.
49. How can you identify missing values in a data frame?
- Using .isnull() function: This function returns a boolean mask indicating which cells have missing values.
- Using .info() method: This provides a summary of the data frame including the count of non-null values for each column.
- Using .describe() method: This displays descriptive statistics of the data frame including the count of non-null values.
- Using .fillna() method: This can be used to replace missing values with a specified value.
50. What is SciPy?
SciPy is a popular scientific computing library for Python that provides a wide range of functionalities. It is built on top of NumPy, another popular library for numerical computations in Python.
SciPy offers modules for optimization, integration, linear algebra, statistics, signal and image processing, and more. It is an essential tool for scientific research, engineering, and data analysis. With its extensive library of functions and algorithms, SciPy makes it easier to perform complex mathematical operations and solve scientific problems efficiently.
Whether you're working on data analysis, machine learning, or simulation, SciPy is a powerful tool that can greatly enhance your Python programming experience.
51. Given a 5x5 matrix in NumPy, how will you inverse the matrix?
- Import the NumPy library: import numpy as np.
- Create a 5x5 matrix, matrix, using NumPy: matrix = np.array([[...],[...],[...],[...],[...]]).
- Calculate the inverse of the matrix: inverse_matrix = np.linalg.inv(matrix).
- The inverse_matrix variable will now hold the inverse of the original matrix. Remember, for the linalg.inv() function to work, the matrix needs to be square and have a non-zero determinant.
52. What is an ndarray in NumPy?
An ndarray (short for "n-dimensional array") is a fundamental data structure in NumPy, which is a powerful numerical computing library for Python. It consists of elements of a single data type arranged in a grid with any number of dimensions.
Numpy ndarray is a homogeneous collection of multidimensional items of the same type, where each item is indexed by a tuple of positive integers. The ndarray provides a fast and memory-efficient way to handle large volumes of numerical data, such as matrices and arrays, and supports a range of mathematical operations and manipulations.
The ndarray has become a cornerstone of scientific computing and is a key tool for data scientists, researchers, and developers.
53. Using NumPy, create a 2-D array of random integers between 0 and 500 with 4 rows and 7 columns.
Sure, here's a quick code snippet that uses NumPy library in Python to generate a 2-D array of random integers between 0 and 500 with 4 rows and 7 columns:

This code imports NumPy module as np, then uses the np.random function to generate a 2-D array of random integers between 0 to 500. The size parameter specifies the shape of the array, which is set to (4, 7) for 4 rows and 7 columns. The output is displayed using the print function.
54. Find all the indices in an array of NumPy where the value is greater than 5.
To find all the indices in an array of NumPy where the value is greater than 5, you can use the np.where() function. This function returns a tuple of arrays, one for each dimension of the input array, containing the indices where the condition is true. Here's an example:

This will output (array([2, 4, 6, 7, 8]),), which means that the values greater than 5 are located at indices 2, 4, 6, 7, and 8 in the original array.


Wrapping up
If you want to ensure that you do well in your Big Data interview, the above set will help you with the technical part of your Big Data engineer interview. However, your Big Data engineer interview will have technical and soft skills questions too.
Companies and recruiters want to conduct Big Data engineer interviews to get good Big Data engineers. Asking soft skills questions helps recruiters determine whether you will be an asset to the team or not. Thus, while preparing for your Big Data engineer interview, focus on preparing both technical and soft skills questions. Practicing with a friend or colleague can often help in preparing for soft skills questions.
If you think you have the skills to make through Big Data engineer interview at top US MNCs, head over to Turing.com to apply. If you are a recruiter building a team of excellent Big Data engineers, choose from the planetary pool of Big Data engineers at Turing.
Hire Silicon Valley-caliber Big Data developers at half the cost
Turing helps companies match with top quality remote JavaScript developers from across the world in a matter of days. Scale your engineering team with pre-vetted JavaScript developers at the push of a buttton.
Tired of interviewing candidates to find the best developers?
Hire top vetted developers within 4 days.





Leading enterprises, startups, and more have trusted Turing

Check out more interview questions
Hire remote developers
Tell us the skills you need and we'll find the best developer for you in days, not weeks.