

Kubernetes
Basic Interview Q&A

1. Are you familiar with K8s?
It is another name for Kubernetes, an open-source platform for managing containerized applications. Kubernetes automates the scaling, deployment, and management of containerized applications, allowing them to run consistently across different computing environments.
2. What is Kubernetes and what does it do?
Kubernetes is an open-source container management tool that automates the deployment, scaling, and descaling of containers. It was developed by Google based on their experience of running containerized workloads for over 15 years. Kubernetes has become the standard tool for managing containerized applications and has a large and active community contributing to its development.
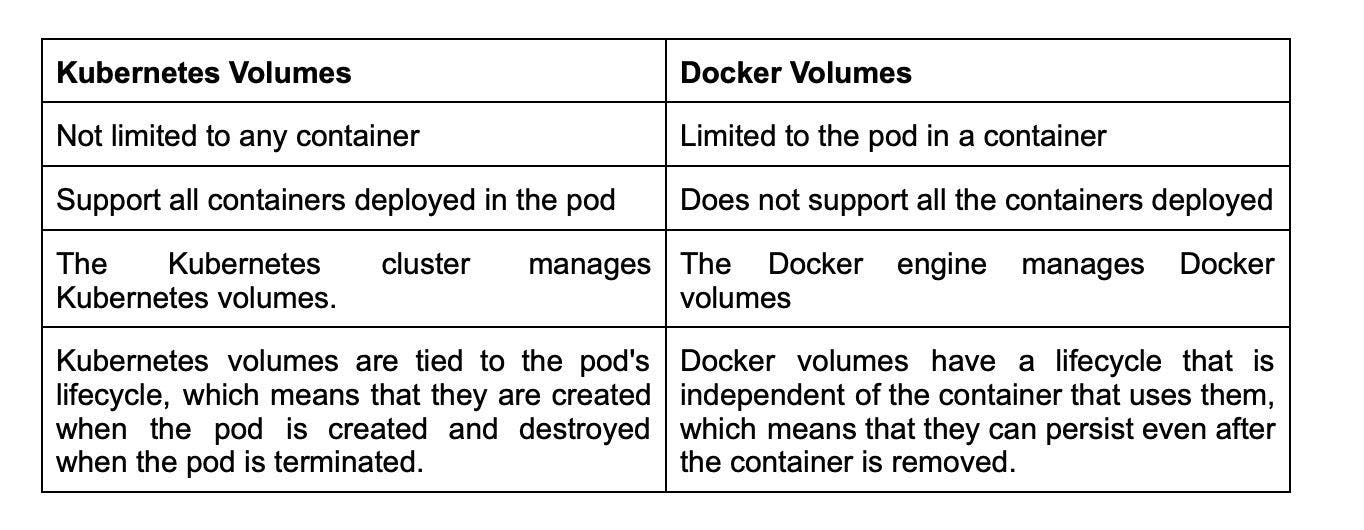
3. How are Kubernetes and Docker linked?
Docker builds containers, which then communicate with each other via Kubernetes. Kubernetes supports multiple container runtimes, including Docker, CRI-O, and others. In simple terms, Kubernetes is analogous to an operating system, and Docker containers are comparable to applications installed on that operating system.
Docker is a containerization platform that allows developers to package and distribute their applications as self-contained units, known as containers. Kubernetes, on the other hand, is a container orchestration platform that automates the deployment, scaling, and management of containerized applications.
The two technologies, Kubernetes and Docker, work together to enable the deployment and management of applications in a distributed environment.
4. Can you explain what container orchestration is?
Container orchestration is a process that involves managing and coordinating the deployment, scaling, and operation of multiple containers that run on a single server or across multiple servers. It automates container provisioning, networking, resource allocation, load balancing, availability, and lifecycle management tasks. Container orchestration tools, such as Kubernetes, Docker Swarm, and Apache Mesos, help ensure that containers work together seamlessly and efficiently to deliver the desired applications or services.
5. Why do we need container orchestration?
Container orchestration is critical to working with containers, allowing organizations to unlock their full benefits. It can be used in any environment where you use containers.
Container orchestration is needed to manage and automate containerized applications' deployment, scaling, and management. It helps to reduce operational overhead, increase efficiency and scalability, and ensure infrastructure availability, thus helping to improve application performance.
6. List the features of Kubernetes.
Some of the features of Kubernetes are:
Automated scheduling: Kubernetes automatically schedules containers to run on the available resources in the cluster.
Self-healing capabilities: Kubernetes automatically replaces failed containers and reschedules them on healthy nodes in the cluster.
Automated rollouts and rollback: Kubernetes is responsible for automating the deployment process, enabling users to roll out new versions of their applications easily and roll them back in case of any issues.
Horizontal scaling and load balancing: Kubernetes automatically scales and distributes traffic across multiple instances of a containerized application.
Configuration management: Kubernetes enables users to define and manage the application configuration settings separately from the application code.
Service discovery & networking: Kubernetes provides a built-in service discovery mechanism to locate and communicate with other services in the cluster.
Security & compliance: Kubernetes provides several security features, including access control to ensure the security of the cluster and compliance with organizational policies.
7. How does Kubernetes help in containerized deployment?
Kubernetes helps in containerized deployment by scaling, loading, balancing, and monitoring containers. You can take advantage of these features by deploying your containerized applications on a Kubernetes cluster. To do this, you create a deployment configuration that instructs Kubernetes on creating and updating instances of your application. Kubernetes manage these instances, which can automatically recover from failures and scale up or down based on demand.
8. What are clusters in Kubernetes?
Clusters in Kubernetes refer to a group of interconnected physical or virtual machines called nodes that work together to efficiently and automatically run containerized applications in a distributed and fault-tolerant manner. Kubernetes clusters allow engineers to orchestrate and monitor containers across multiple physical, virtual, and cloud servers. Kubernetes clusters are designed to be highly available, resilient, and scalable. By using a cluster, engineers can take advantage of the automatic scaling and self-healing capabilities of Kubernetes for optimized application performance.
9. Explain Google Container Engine (Google Kubernetes Engine).
It is a Google-managed implementation of the Kubernetes open-source management platform for clusters and Docker containers. It provides a managed environment for deploying, scaling, and managing your containerized applications using Google infrastructure. It is designed to simplify containerized applications' deployment, management, and scaling in a production environment.
10. What is Heapster?
A Heapster is a cluster-wide aggregator of data that runs on each node. It is a Kubernetes project that provides a robust monitoring solution for Kubernetes clusters. Heapster is flexible and modular, making it easy to use and customize for different needs. However, Heapster has been deprecated since Kubernetes version 1.11. Its functionality has been replaced by the Kubernetes Metrics Server, which provides a more efficient and scalable way to collect and expose resource utilization data from Kubernetes nodes and pods.
11. What do you know about Minikube?
Minikube is a lightweight implementation of Kubernetes, which creates a VM on your local machine. It is a tool that sets the Kubernetes environment on your laptop or PC, and it addresses a different type of use case than most other distributions, such as Rancher, EKS, and OpenShift. It creates a lightweight, self-contained environment with all the necessary components for running Kubernetes, such as the API server, etcd, and kubelet. This allows developers to experiment with Kubernetes without the need for a full-scale production environment.
12. What do you know about Kubectl?
A Kubetcl is a command-line tool or platform through which you can pass commands to a cluster. Kubectl is the Kubernetes-specific command line tool that lets you communicate and control Kubernetes clusters. With Kubectl, you can deploy applications, inspect and manage cluster resources, view logs, and debug your applications running on Kubernetes. Kubectl can also be used to manage remote and cloud clusters such as GKE.
13. Can you elaborate on the above question?
Kubectl allows you to deploy and manage applications on a Kubernetes cluster, inspect and debug cluster resources, and view logs and metrics, among other things.
Here's a brief overview of what Kubectl can do:
- Create, read, update, and delete Kubernetes resources (pods, services, deployments, etc.)
- Interact with the Kubernetes API server to manage cluster resources
- Monitor the status of resources and diagnose issues
- Manage Kubernetes configurations and secrets
- View logs and metrics for applications running on the cluster
14. What is a node in Kubernetes?
A node is the primary worker machine in the Kubernetes cluster, also known as the minion. It may be a physical or a virtual machine depending on the cluster. It has several components, including a kubelet, container runtime, and Kubernetes components to communicate with the control plane. Nodes can run one or more containers and can be added or removed from the cluster dynamically.
15. List the main components of Kubernetes architecture.
Two main components of Kubernetes architecture are the Master node and the Worker node.
Master node: The master node is the control plane making global decisions inside the cluster. The master node comprises the control plane components responsible for managing and coordinating the cluster. These components are the API server, scheduler, cloud controller manager, and controller manager.
Worker node: The worker node has four very light components, which makes sense because you want to reserve most of the space for your pods. These components are the proxy, the Kubelet, and the container runtime.
16. Can you tell me about kube-proxy?
Kube-proxy can run on every node and perform TCP/UDP packet forwarding across the backend network service. Kube-proxy is an important component of Kubernetes networking that helps ensure reliable and efficient communication between pods and services within the cluster. By routing traffic to the correct destination, kube-proxy helps ensure reliable and efficient communication within the cluster.
17. What is the master node in Kubernetes?
It controls and manages the worker nodes. It makes up the control plane of a cluster and is responsible for scheduling tasks and monitoring the state of the cluster. The master node has several components, such as Kube-APIServer, Kube-Controller-manager, Etcd, and Kube-Scheduler, to help manage worker nodes.
18. Tell me more about the kube-scheduler.
Kube-scheduler distributes and manages the workload on the worker nodes. It uses various policies to select the most suitable node for a pod based on factors such as resource requirements, node capacity, and pod affinity/anti-affinity. The kube-scheduler component is also responsible for binding the selected node to the pod and updating the Kubernetes API server with the updated information.
19. Which node in Kubernetes keeps track of resource utilization?
The node in Kubernetes that keeps track of resource utilization is the kubelet. It runs on each worker node and is responsible for managing the state of the node, including starting and stopping pods, as well as monitoring their resource usage. The Metrics Server collects the relevant resource usage stats from kubelet and generates aggregated metrics via metrics API.
20. What is Kubernetes controller manager?
The Kubernetes controller manager embeds controllers and is responsible for creating a namespace. Here controllers are control loops that watch the state of your cluster, then make or request changes where needed. Every controller tries to move the current cluster state to the desired state.
21. List the different types of controllers in Kubernetes.
Here are some of the types of controllers:
- Node controller
- Replication controller
- Service account and token controller
- Endpoints controller
- Namespace controller
22. What do you know about ETCD?
Pronounced as "ett-see-dee," it is written in Go programming language and used to coordinate distributed work and key-value pairs. It is an open-source distributed key-value store that holds and manages the critical information distributed systems need to keep running. It is built on the Raft consensus algorithm, which ensures datastore consistency across all the nodes.
23. List the different types of services in Kubernetes.
Here are some of the services in Kubernetes:
Cluster IP: This is the default service type in Kubernetes, and it exposes the service on a cluster-internal IP. This means that only the services inside the cluster can access it.
Node Port: This type of service exposes the service on a static port on each node in the cluster. This makes the service accessible from outside the cluster.
Load balancer: This type of service provisions an external load balancer in the cloud infrastructure and directs traffic to the Kubernetes service. This allows you to expose your service to the internet.
External name: This type of service maps the service to an external DNS name. This allows you to reference external services by name from within your cluster.
24. Tell me about load balancers in Kubernetes.
In Kubernetes, a load balancer is a component that distributes incoming network traffic across multiple instances of an application running in a cluster. The load balancer sends connections to one server in the pool based on an algorithm to determine the next server and sends new connections to the next server, which is available. This algorithm is ideal where virtual machines incur costs, such as in hosted environments. Some of the strategies used for load balancing are Round robin, Session infinity, and IP hashing.
25. What is Ingress network?
An Ingress network is a set of protocols that acts as an entry point for external traffic into the Kubernetes cluster and manages access to services within the cluster. An Ingress network is traffic whose source lies in the public internet or an external network and is sent to the destined node in the private network. It is used to manage user access for the services within the Kubernetes cluster.
26. What is the role of the Ingress network?
The Ingress network manages external access to services in the cluster. Specifically, it enables the load balancing of traffic, termination of SSL/TLS, and virtual hosting for HTTP and HTTPS routes exposed from outside the cluster to services within it. The Ingress network helps streamline communication between the applications and external clients by providing a single entry point for incoming traffic.
27. Explain the cloud controller manager.
The cloud controller manager lets you link the cluster to the cloud provider’s API. Cloud-controller manager allows cloud vendors to evolve independently from the core Kubernetes code by abstracting the provider-specific code. It abstracts provider-specific code and functionality, which allows cloud vendors to develop and maintain their code independently from the core Kubernetes code.
Using the CCM, cloud-specific operations such as creating and managing load balancers, block storage volumes, and cloud-specific networking resources can be performed seamlessly within a Kubernetes cluster. This allows users to take advantage of the benefits of both Kubernetes and the cloud provider while minimizing the potential for compatibility issues.
28. What are the different types of cloud controller managers?
Here are some of the types of cloud controller managers:
Node controller: Responsible for managing the lifecycle of nodes in the cluster, such as creating, updating, and deleting nodes
Route controller: Manages ingress and egress traffic for services running in the Kubernetes cluster
Volume controller: Responsible for managing the lifecycle of volumes in the cluster, such as creating, attaching, and detaching volumes.
Service controller: Manages the lifecycle of Kubernetes services, such as creating, updating, and deleting services.
29. Do you know what container resource monitoring is?
Container resource monitoring is the process of constantly collecting metrics. Also, it tracks the health of containerized applications to improve their health and performance and ensure they are operating smoothly. Container resource monitoring has become popular because it provides robust capabilities to track potential failures.
30. What is the init container?
An init container is a type of container in Kubernetes that runs before the main application containers in a pod. The purpose of an init container is to perform initialization tasks or setup procedures that are not present in the application container images. Examples of tasks that an init container might perform include downloading configuration files, setting up a network connection, or initializing a database schema.



Wrapping up
The above-mentioned Kubernetes technical interview questions will help the candidates improve their interview preparation. It will also help recruiters weigh the candidate's skills appropriately.
With good coverage across basic, medium, and advanced-level Kubernetes interview questions and answers, we have tried to cover the most popular questions. If you are a developer, try the Turing test and grab the chance to work with the top U.S. companies from the comfort of your home. And, if you are a recruiter and want to skip the lengthy interview process, Turing can help you source, vet, match, and manage the world's best Kubernetes developers remotely.
Hire Silicon Valley-caliber Kubernetes developers at half the cost
Turing helps companies match with top quality remote JavaScript developers from across the world in a matter of days. Scale your engineering team with pre-vetted JavaScript developers at the push of a buttton.
Tired of interviewing candidates to find the best developers?
Hire top vetted developers within 4 days.





Leading enterprises, startups, and more have trusted Turing

Check out more interview questions
Hire remote developers
Tell us the skills you need and we'll find the best developer for you in days, not weeks.