How to Train Custom Named Entity Recognition Model Using SpaCy
•10 min read
- Languages, frameworks, tools, and trends
- Skills, interviews, and jobs

Named Entity Recognition (NER) is a subtask that extracts information to locate entities, like person name, medical codes, location, and percentages, mentioned in unstructured data. Suppose you are training the model dataset for searching chemicals by name, you will need to identify all the different chemical name variations present in the dataset. In order to do this, you can use the annotation tools provided by spaCy, such as entity linker. You can use an external tool like ANNIE.
Developers often consider NLP libraries while trying to unlock the compelling and actionable clue from the original raw data. Due to the use of natural language, software terms transcribed in natural language differ considerably from other textual records.
The open-source spaCy library has been downloaded and used by more than two million developers for natural language processing With it, you can create a custom entity recognition model, which is necessary when there are many variations of a specific entity.
This blog post will explain how we build a custom entity recognition model using spaCy.
What is spaCy?
The spaCy software library performs advanced natural language processing using Python and Cython.
Founders of the software company Explosion, Matthew Honnibal and Ines Montani, developed this library. They licensed it under the MIT license. SpaCy is designed for the production environment, unlike the natural language toolkit (NLKT), which is widely used for research.
Several features are included in spaCy's advanced natural language processing (NLP) library for Python and Cython. As far as NLP annotation tools go, spaCy is one of the best. NLP programs are increasingly used for processing and analyzing data.
Large amounts of unstructured textual data get generated, and it is significant to process that data and apply insights. In order to do that, you need to format the data in a form that computers can understand. Natural language processing can help you do that.
With spaCy, you can execute parsing, tagging, NER, lemmatizer, tok2vec, attribute_ruler, and other NLP operations with ready-to-use language-specific pre-trained models. 18 languages are supported, as well as one multi-language pipeline component.
What is Named Entity Recognition (NER)?
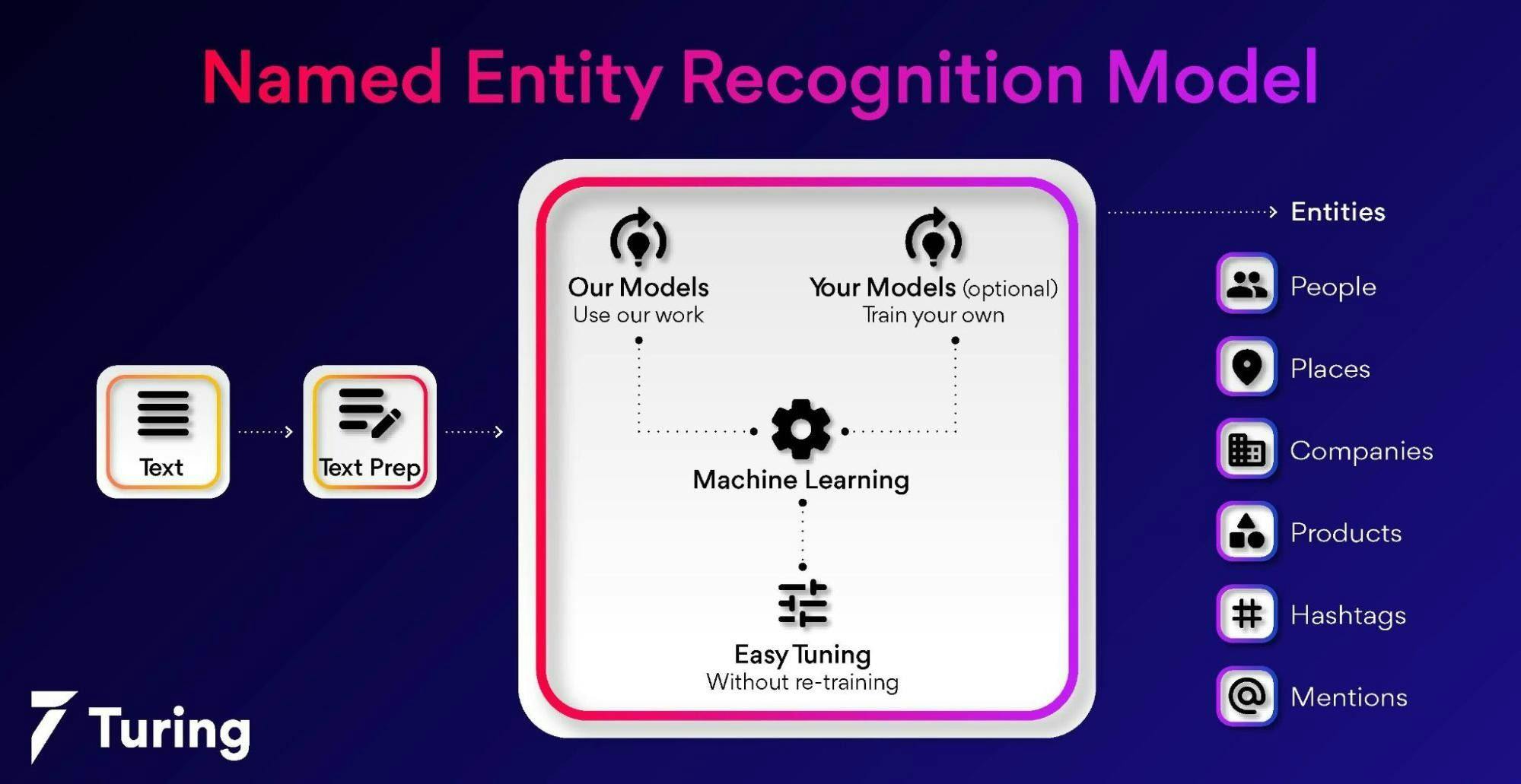
The information extraction process (IE) involves identifying and categorizing specific entities in a document.
A ‘Named Entity Recognition model’, i.e.NER or NERC is also called identification of entities, chunking of entities, or entity extraction. Natural language processing (NLP) and machine learning (ML) are fields where artificial intelligence (AI) uses NER.
In simple words, a named entity in text data is an object that exists in reality. Examples of objects could include any person, place, or thing that can be represented as a proper name in the text data.
Information retrieval starts with named entity recognition. The information retrieval process uses unstructured raw text documents to retrieve essential and valuable information. The named entity recognition program locates and categorizes the named entities obtainable in the unstructured text according to preset categories, such as the name of a person, organization, quantity, monetary value, percentage, and code.
The spaCy system assigns labels to the adjacent span of tokens. It does this by using a breakneck statistical entity recognition method. The core of every entity recognition system consists of two steps:
- Entity detection and entity recognition.
- Categorizing the entities accordingly.
The NER begins by identifying the token or series of tokens that constitute an entity. Finding entities' starting and ending indices via inside-outside-beginning chunking is a common method. Creating entity categories is the next step. There are many different categories of entities, but here are several common ones:
- Person
- Organization
- Location
- Time
- Measurements or Quantities
- String patterns like emails, phone numbers, or IP addresses
There are some systems that use a rule-based approach to recognizing entities, however, most modern systems rely on machine learning/deep learning. As a result of its human origin, text data is inherently ambiguous. The word 'Boston', for instance, can refer both to a location and a person.
Types of NER models
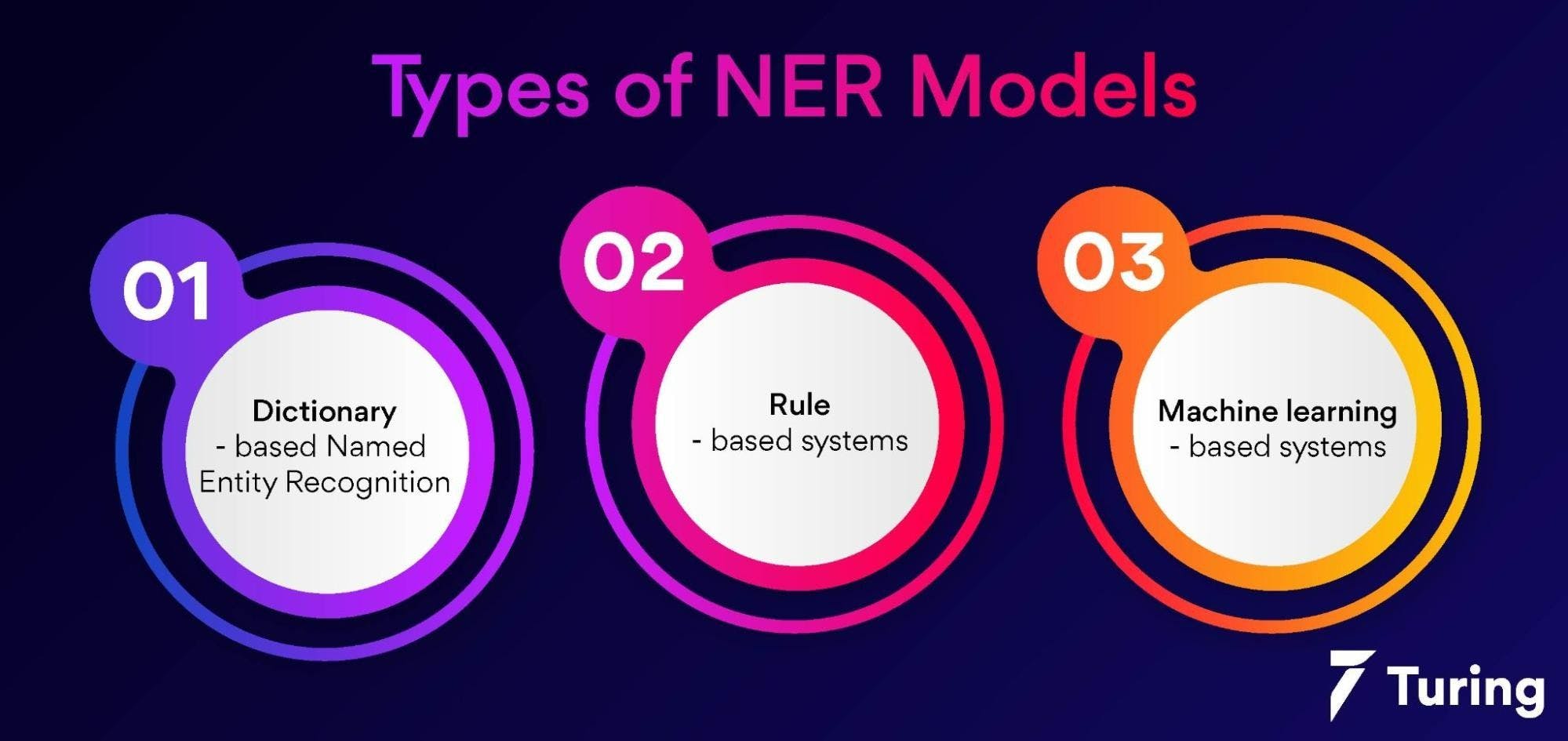
1. Dictionary-based named entity recognition
This is the process of recognizing objects in natural language texts. The term named entity is a phrase describing a class of items. A dictionary-based NER framework is presented here.
This tool uses dictionaries that are freely accessible on the Web. A dictionary consists of phrases that describe the names of entities.
It mainly has two steps:
(1) Detecting candidates based on dictionaries, and
(2) Filtering out false positives using a part-of-speech tagger.
In order to improve the precision and recall of NER, additional filters using word-form-based evidence can be applied. An efficient prefix-tree data structure is used for dictionary lookup. Machine learning techniques are used in most of the existing approaches to NER.
In simple words, a dictionary is used to store vocabulary. A simple string matching algorithm is used to check whether the entity occurs in the text to the vocabulary items. The dictionary used for the system needs to be updated and maintained, but this method comes with limitations.
2. Rule-based systems
A NERC system usually consists of both a lexicon and grammar. A lexicon consists of named entities that are categorized based on semantic classes. NEs that are not included in the lexicon are identified and classified using the grammar to determine their final classification in ambiguous cases.
NERC systems have to validate both the lexicon and the grammar with large corpora in order to identify and categorize NEs correctly. It will enable them to test their efficacy and robustness.
As a result of this process, the performance of the developed system is not ensured to remain constant over time. The introduction of newly developed NEs or the change in the meaning of existing ones is likely to increase the system's error rate considerably over time.
You will not only be able to find the phrases and words you want with spaCy's rule-based matcher engine. You can also view tokens and their relationships within a document, not just regular expressions. By analyzing and merging spans into a single token, or adding entries to named entities using doc.ents function, it is easy to access and analyze the surrounding tokens.
By using this method, the extraction of information gets done according to predetermined rules. The most common standards are
a. Pattern-based rules: In a pattern-based rule, the words in the document get arranged according to a morphological pattern.
b. Context-based rules: This establishes rules according to what the word means or what the context is in the document.
3. Machine learning-based systems
Machine learning methods detect entities by using statistical modeling. In this case, text features are used to represent the document. Despite slight spelling variations, the model can recognize entity types and overcome some of the drawbacks of the first two approaches.
The ML-based systems detect entity names using statistical models. A feature-based model represents data based on the features present. This approach eliminates many limitations of dictionary-based and rule-based approaches by being able to recognize an existing entity's name even if its spelling has been slightly changed.
In terms of NER, developers use a machine learning-based solution. During the first phase, the ML model is trained on the annotated documents. The amount of time it will take to train the model will depend on the complexity of the model. The next phase involves annotating raw documents using the trained model.
SpaCy for NER
The spaCy Python library improves NLP through advanced natural language processing. Applications that handle and comprehend large amounts of text can be developed with this software, which was designed specifically for production use.
Organizing information or recognizing natural language can be done using this technique, or it can be used as a preprocessing Zstep for deep learning. In addition to tokenization, parts-of-speech tagging, text classification, and named entity recognition, spaCy also offer several other features.
SpaCy is very easy to use for NER tasks. Although we typically need to customize the data we use to fit our business requirements, the model performs well regardless of what type of text we provide.
In spaCy, a sophisticated NER system in Python is provided that assigns labels to contiguous groups of tokens. This model provides a default method for recognizing a wide range of names and numbers, such as person, organization, language, event, etc.
SpaCy gives us the variety of selections to add more entities by training the model to include newer examples. NER can also be modified with arbitrary classes if necessary.
The following four pre-trained spaCy models are available with the MIT license for the English language:
1. en_core_web_sm(12 mb)
2. en_core_web_md(43 mb)
3. en_core_web_lg(741 mb)
4. en_core_web_trf(438 mb)
Getting started with NER
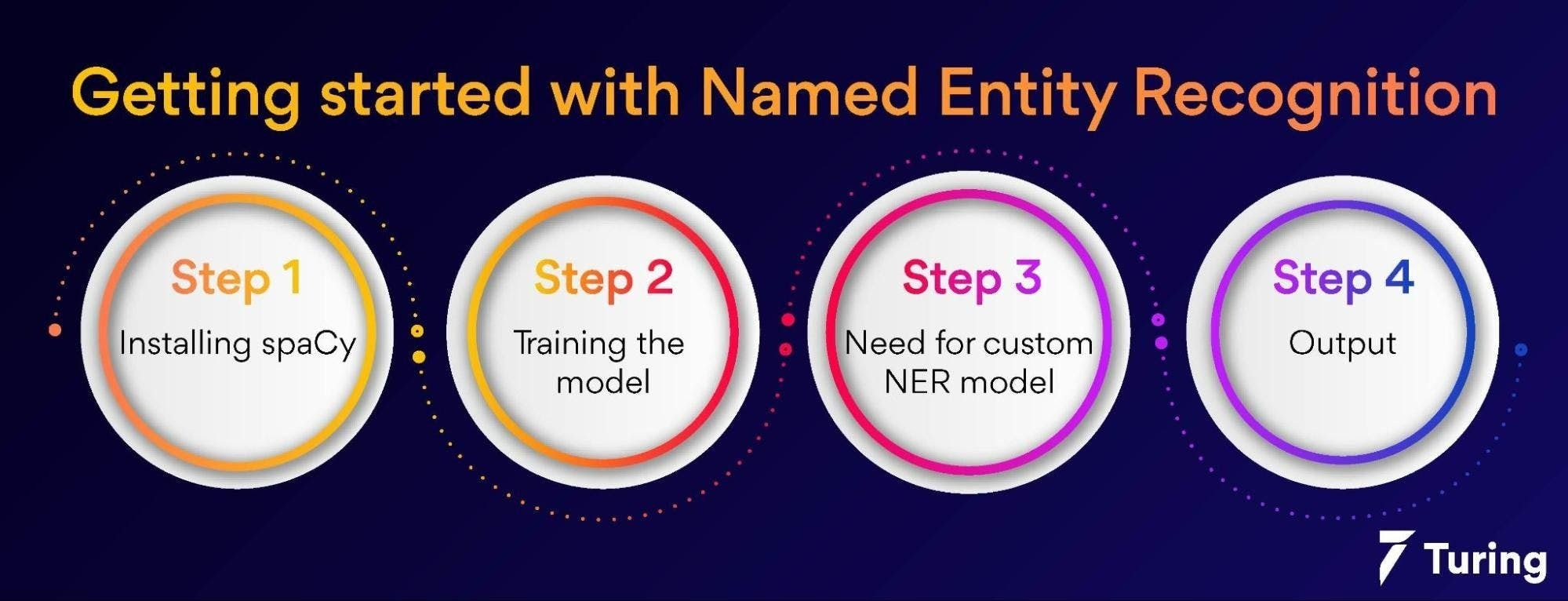
Step 1: Installing spaCy
The Python package manager pip can be used to install spaCy. To avoid using system-wide packages, you can use a virtual environment.
After successful installation you can now download the language model using the following command.
Step 2: Training The Model
You can start the training once you have completed the first step.
Initially, import the necessary package required for the custom creation process.
Also, we need to download pre-trained statistical models that support certain languages. SpaCy provides four such models for the English language as we already mentioned above. We can also start from scratch by downloading a blank model. Here we will see how to download one model.
Now check if it has NER
You will get the following result once you run the command for checking NER availability.
In case your model does not have NER, you can add it using the nlp.add_pipe() method.
Step 3: Need for custom NER model
SpaCy has an in-built pipeline NER for named recognition. Though it performs well, it’s not always completely accurate for your text. Sometimes, a word can be categorized as a person or an organization depending upon the context. Also, sometimes the category you want may not be available in the built-in spaCy library.
Step 4: Output
As you can see in the output, the code given above worked perfectly by giving annotations like India as GPE, Wednesday as Date, Jacinda Ardern as Person.
With the increasing demand for NLP (Natural Language Processing) based applications, it is essential to develop a good understanding of how NER works and how you can train a model and use it effectively.
In this blog, we discussed the process engaged while training a custom-named entity recognition model using spaCy. We tried to include as much detail as possible so that new users can get started with the training without difficulty.
You can train your own NER models effortlessly and integrate them with these NLP libraries. Hopefully, you will find these tasks as exciting as we do.
FAQ
1. How do I add custom entities to spaCy?
You can use spaCy's EntityRuler() class to create your own named entities if spaCy's built-in named entities aren't enough. In a spaCy pipeline, you can create your own entities by calling entityRuler().
The entityRuler() creates an instance which is passed to the current pipeline, NLP. Once you have this instance, you may call add_patterns(), passing a dictionary of the text pattern you wish to label with an entity. You can add a pattern to the NLP pipeline by calling add_pipe().
2. Which is better, NLTK or spaCy?
SpaCy is always better than NLTK and here is how.
- A plethora of algorithms is provided by NLTK, which is a boon for researchers, but a bane for developers. However, spaCy maintains a toolkit of the best algorithms and updates them as state-of-the-art improvements.
- With NLTK, you can work with several languages, whereas with spaCy, you can work with statistics for seven languages (English, German, Spanish, French, Portuguese, Italian, and Dutch). Multi-language named entities are also supported.
- SpaCy supports word vectors, but NLTK does not. Since spaCy uses the newest and best algorithms, it generally performs better than NLTK.
3. What is Doc ents in spaCy?
The named entities in a document are stored in this doc ents property. This property returns named entity span objects if the entity recognizer has been applied.
Docs are sequences of Token objects. Sentences can be accessed and named entities can be exported as NumPy arrays, and lossless serialization to binary string formats is supported. There is an array of TokenC structs in the Doc object. The Token and Span Python objects are just views of the array, they do not own the data.
4. What model does spaCy use for NER?
SpaCy's NER model uses word embeddings, which is a multilayer CNN With SpaCy, you can assign labels to groups of contiguous tokens using a highly efficient statistical system for NER in Python.
This model identifies a broad range of objects by name or numerically, including people, organizations, languages, events, and so on. The NER model in spaCy comes with these default entities as well as the freedom to add arbitrary classes by updating the model with a new set of examples, after training.
5. How accurate is spaCy?
With spaCy v3.0, you will be able to get all the benefits of its transformer-based pipelines which bring its accuracy right up to date. With multi-task learning, you can use any pre-trained transformer to train your own pipeline and even share it between multiple components. Thanks to spaCy's transformer support, you have access to thousands of pre-trained models you can use with PyTorch or HuggingFace.