
A Comprehensive Guide to Named Entity Recognition (NER)
•8 min read
- Languages, frameworks, tools, and trends

Named entity recognition (NER) is a form of natural language processing (NLP) that involves extracting and identifying essential information from text. The information that is extracted and categorized is called entity. It can be any word or a series of words that consistently refers to the same thing.
This article will explore everything there is to know about Python named entity recognition, NER methods, and their implementation. It will also look at how named entity recognition works.
Understanding named entity recognition categorization
NER essentially extracts and categorizes the detected entity into a predetermined category. The category can be generic like Organization, Person, Location, Time, etc., or a custom category depending on the use case such as Healthcare Terms, Programming Language, etc. For example, an NER model detects “football“ as an entity in a paragraph and classifies it into the category of sports.

In the image above, Berlin and winter are two entities and are arranged into categories of place and time, respectively.
In simpler words, if your task is to find out ‘where’, ‘what’, ‘who’, ‘when’ from a sentence, NER is the solution you should opt for.
Here’s another example using the online tool Named Entity Visualizer. A paragraph about Cristiano Ronaldo has been given as input. Predetermined categories like Person, Date, and Event have also been mentioned.
The output paragraph displays the keywords detected for the specified categories.

How is named entity recognition used?
Named entity recognition algorithms are best suited in any situation where a high-level overview of large text is required. NER lets you have a quick glance and understand the subject or theme of a large chunk of text. It has use cases in many scenarios. Some are listed below:
Customer support
NER helps in reducing response time by categorizing user requests, complaints, and questions filtered by specific keywords.
Healthcare
It helps doctors understand reports quickly by extracting essential information, hence, reducing workloads and improving patient care standards.
Search engines
It improves the speed and relevance of search results by analyzing search queries and other texts.
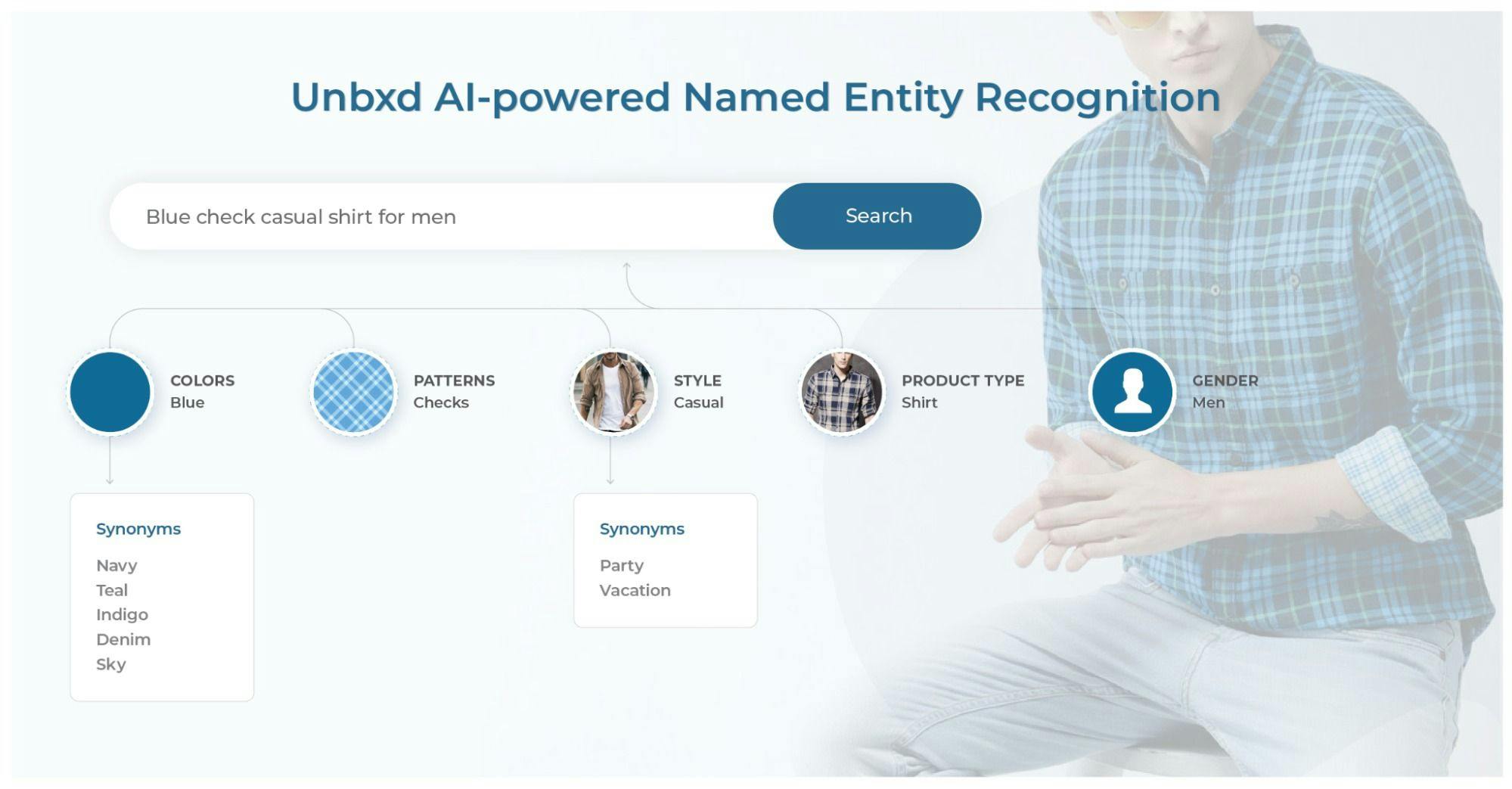
Human resources
It improves internal workflows by categorizing employee complaints and questions and speeds up the hiring process by summarizing applicants’ CVs.
Methods of NER
1. Dictionary-based
This is the simplest NER method. In this approach, a dictionary containing vocabulary is used. Basic string-matching algorithms check whether the entity is present in the given text against the items in the vocabulary. This method is generally not employed because the dictionary that is used is required to be updated and maintained consistently.
2. Rule-based
In this method, a predefined set of rules for information extraction is used which are pattern-based and context-based. Pattern-based rule uses the morphological pattern of the words while context-based uses the context of the word given in the text document.
3. Machine learning-based
This method solves a lot of limitations of the above two methods. It is a statistical-based model that tries to make a feature-based representation of the observed data. It can recognize an existing entity name even with small spelling variations.
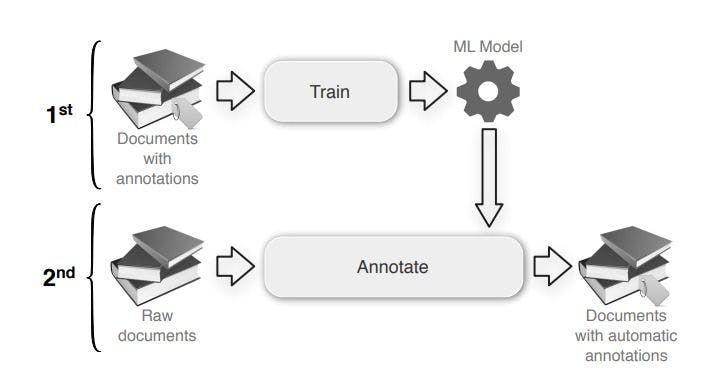
The machine learning-based approach involves two phases for doing NER. The first phase trains the ML model on annotated documents. In the next phase, the trained model is used to annotate the raw documents. The process is similar to a normal ML model pipeline.
4. Deep learning-based
Deep learning NER is more accurate than the ML-based method because it is capable of assembling words, enabling it to understand the semantic and syntactic relationship between various words better. It is also capable of analyzing topic-specific and high-level words automatically.
How named entity recognition works
Humans can easily detect entities belonging to various categories like people, location, money, etc. For computers to do the same, they first need to recognize and then categorize them. NLP and machine learning are used to achieve this.
- NLP: Helps machines understand the rules of language and helps make intelligent systems that can easily derive meaning from text and speech.
- Machine learning: Helps machines learn and improve over time by using various algorithms and training data.
Any NER model has a two-step process: i) detect a named entity and ii) categorize the entity.
i) Detect a named entity
The first step for named entity recognition is detecting an entity or keyword from the given input text. The entity can be a word or a group of words.
ii) Categorize the entity
This step requires the creation of entity categories. Some common categories are:
Person - Cristiano, Sachin, Dhoni
Organization - Google, Microsoft, Visa
Time - 2006, 13:32
Location - India, Lucknow, USA
Percent - 99%
Money - 2 billion dollars
You can also create your own entity categories.
Good training data is essential for a model to categorize detected entities into a relevant predetermined entity. Therefore, it’s vital to train the model correctly on suitable data.
Implementation of NER
Using spaCy
NER can be implemented easily using spaCy, an open-source NLP library. It’s used for various tasks and has built-in methods for NER. It also has a fast statistical entity recognition system. Generally, the spaCy model performs well for all types of text data but it can be fine-tuned for specific business needs.
Let’s have a look at the code:
Import spaCy:
spaCy pipelines for NER
spaCy has three main English pipelines that are optimized for CPU to perform NER.
a. En_core_web_sm
b. En_core_web_md
c. En_core_web_lg
These models are listed in ascending order according to their size where sm, md, lg denote small, medium, and large models, respectively.
Let’s try it with a small model. Download and load the model ‘en_core_web_sm’.
Below is the input text about WHO.
doc="The World Health Organization (WHO)[1] is a specialized agency of the United Nations responsible for international public health.[2] The WHO Constitution states its main objective as 'the attainment by all peoples of the highest possible level of health'.[3] Headquartered in Geneva, Switzerland, it has six regional offices and 150 field offices worldwide. The WHO was established on 7 April 1948.[4][5] The first meeting of the World Health Assembly (WHA), the agency's governing body, took place on 24 July of that year. The WHO incorporated the assets, personnel, and duties of the League of Nations' Health Organization and the Office International d'Hygiène Publique, including the International Classification of Diseases (ICD).[6] Its work began in earnest in 1951 after a significant infusion of financial and technical resources.[7]"
Call the function with the above text as input.
Output:
These are the extracted named entities from the input text of WHO.
You can check what type a particular named entity is with the method below:
spaCy also provides an interesting visual to see named entities directly in the text.

Stanford NER tagger
NER can also be implemented using Stanford NER tagger, which is considered one of the standard tools to use. There are three main types of models for identifying named entities:
- The three-class model that helps recognize organizations, persons, and locations.
- The four-class model that recognizes persons, organizations, locations, and miscellaneous entities.
- The seven-class model that helps recognize persons, organizations, locations, money, time, percentages, and dates.
Let’s try the four-class model:
1. Download StanfordNER zip file
2. Load the model
3. Test the model
doc="The World Health Organization (WHO) is a specialized agency of the United Nations responsible for international public health. Headquartered in Geneva, Switzerland, it has six regional offices and 150 field offices worldwide. The WHO was established on 7 April 1948. The first meeting of the World Health Assembly, the agency's governing body, took place on 24 July of that year. The WHO incorporated the assets, personnel, and duties of the League of Nations' Health Organization and the Office International d'Hygiène Publique, including the International Classification of Diseases (ICD).
st_4class.tag(doc.split())
We now know what named entity recognition is as well as its workings, implementation, and its various methods. Try implementing NER for your own use case to get a first-hand look at how it functions.
FAQs
Q. How do you evaluate a named entity recognition in Python?
Named entity recognition is usually approached as a sequence labeling problem. Its model can easily be evaluated through traditional classification metrics such as precision, recall, F-score, etc. However, while these metrics are fine for quick comparison, they don’t tell much about the models you prepare, such as whether entities are good or not, whether sentence length is proper or not, etc.
To tackle this, you can opt for other methods such as dividing the data into buckets of entities-based attributes like entity length, entity density, sentence length, and label consistency, and then evaluating the model on each of these buckets separately. With this method, it becomes quite easy to locate the poor performing factors in a model.
Q. How do you do a named entity recognition?
There are various steps involved for doing named entity recognition. The first is to acquire and process the data. You can either go with already labeled data or build one from scratch based on the use case. The second step is to prepare the input and fine-tune the model. Some things should be taken care of in this step such as sensitivity, special characters and spacing of words, etc. This will help improve accuracy and make the model more generic for other datasets. Next, pick any algorithm like BERT or spaCy, which is an open-source NLP library for advanced NLP tasks. Try these algorithms and evaluate what works best for your model.
Q. What are the named entity recognition applications?
NER is widely used in various NLP tasks. These include:
- Efficient search algorithms
- Content recommendations
- Customer support
- Healthcare
- Summarizing resumes
- Content classification for news channels.
Q. How does named entity recognition work?
Named entity recognition primarily uses NLP and machine learning. With NLP, an NER model studies the structure and rules of language and tries to form intelligent systems that are capable of deriving meaning from text and speech. Meanwhile, machine learning algorithms help an NER model to learn and improve over time. Using these two technologies, the model detects a word or string of words as an entity and classifies it into a category it belongs to.