
Understanding Data Processing Techniques for LLMs

Huzefa Chawre
•12 min read
- LLM training and enhancement

Large language models (LLMs) have emerged as a pivotal force driving today’s AI-driven digital transformation. From generating creative content to offering advanced data insights, LLMs have transformed the landscape of numerous industries. However, the performance of these language models is hugely reliant on the data quality used to train and fine-tune them.
LLMs require massive amounts of data for pretraining and further processing to adapt them to a specific task or domain. As these models continue to evolve, organizations are looking for ways to optimize data collection and processing for increased efficiency and accuracy. In this blog, we cover various data processing techniques, including data cleaning, and explore potential challenges in detail.
Let’s get started!
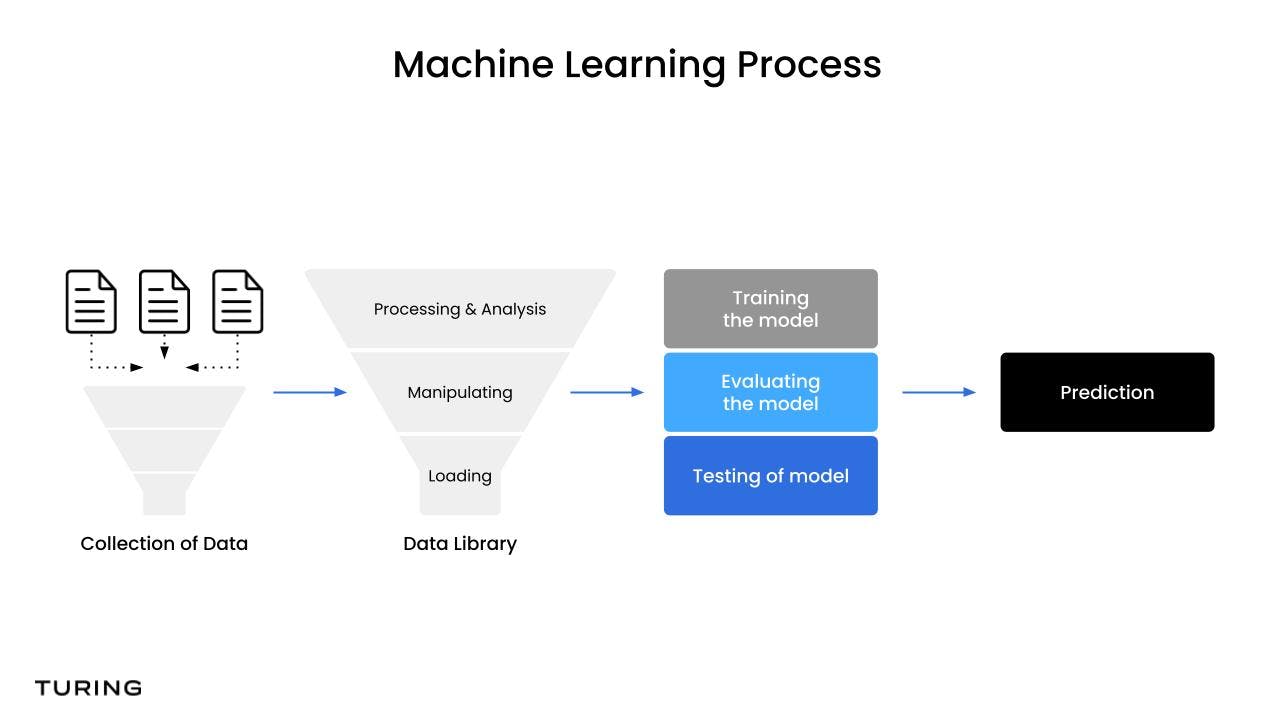
Data processing techniques
For training language models, the first step involves pre-processing the data to ensure consistency and then implementing feature engineering techniques to enhance the model for optimized outcomes.
a. Pre-processing
Data pre-processing involves initial steps to clean and prepare raw text data for machine learning. The goal is to standardize the input data to reduce the complexity that the model needs to handle. Some prominent techniques to pre-process data used in training LLMs are as follows:
1. Data cleaning
Data cleaning is a fundamental aspect of data pre-processing for training LLMs. This technique involves identifying and rectifying inaccuracies, inconsistencies, and irrelevant elements within the raw text data. Common data-cleaning procedures include removing duplicate entries, handling missing or erroneous values, and addressing formatting irregularities.
Additionally, text-specific cleaning tasks such as removing special characters, punctuation, and stop words are performed to streamline the textual input. By executing comprehensive data-cleaning processes, the quality and integrity of the training data are significantly improved, laying a robust foundation for the subsequent stages of LLM training.
The prominent data cleaning methods are as follows:
- Handling missing values: Missing values can occur when there is no data for some observations or features in a dataset. These gaps in data can lead to inaccurate predictions or a biased model. Techniques to handle missing values include imputation, where missing values are filled in based on other data points, and deletion, where rows or columns with missing values are removed. The choice of method depends on the nature of the data and the extent of the missing values.
- Noise reduction: Noise in data refers to irrelevant or random information that can distort the true pattern and lead to inaccurate model predictions. Noise can arise from various sources, such as human error, device malfunction, or irrelevant features. Noise-reduction techniques include binning, where data is sorted into bins and then smoothed, and regression, where data points are fitted to a curve or line. These techniques help reduce data variability and improve the model's ability to learn and predict accurately.
- Consistency checks: Consistency checks ensure the data across the dataset adheres to consistent formats, rules, or conventions. Inconsistencies can occur due to various reasons including data entry errors, different data sources, or system glitches. These inconsistencies can lead to misleading results when training models. Consistency checks involve identifying and correcting these discrepancies. Techniques used include cross-field validation, where the consistency of combined fields is checked, and record duplication checks.
- Deduplication: Duplicate data can occur for various reasons including data entry errors, merging of datasets, or system glitches. These duplicates can skew the data distribution and lead to biased model training. Deduplication techniques include record linkage, where similar records are linked together, and exact matching, where identical records are identified. By removing duplicates, the dataset becomes more accurate and representative, improving the performance of the LLM.
2. Parsing
Parsing involves analyzing data syntax to extract meaningful information. This extracted information serves as input for the LLM. Parsing deals with structured data sources like XML, JSON, or HTML. In the context of natural language processing (NLP), parsing refers to identifying the grammatical structure of a sentence or phrase. This can be helpful for tasks like machine translation, text summarization, and sentiment analysis.
Parsing also extracts information from semi-structured or unstructured data sources like email messages, social media posts, or web pages that can be used for tasks like topic modeling, entity recognition, and relation extraction.
3. Normalization
Normalization is a crucial pre-processing technique for standardizing textual data to ensure uniformity and consistency in language usage and minimize complexity for NLP models. This process involves converting text to a common case, typically lowercase, to eliminate variations arising from capitalization.
Normalization also includes standardizing numerical data, dates, and other non-textual elements to render the entire dataset into a coherent and homogeneous format, facilitating more effective training and improved generalization capabilities for LLMs. Normalization helps reduce the vocabulary size and model complexity, which can improve overall performance and accuracy.
4. Tokenization
Tokenization involves breaking down text into smaller units, called tokens, which can be words, subwords, or characters. Tokenization creates a structured and manageable input for the model. By breaking down the text into tokens, the model gains a granular understanding of language usage and syntax that enables it to analyze and generate coherent sequences of words.
Tokenization also facilitates the creation of vocabulary and word embeddings pivotal for the model's language comprehension and generation capabilities. This process forms the basis for text processing for LLMs, laying the groundwork for effective language modeling and natural language understanding.
5. Stemming and lemmatization
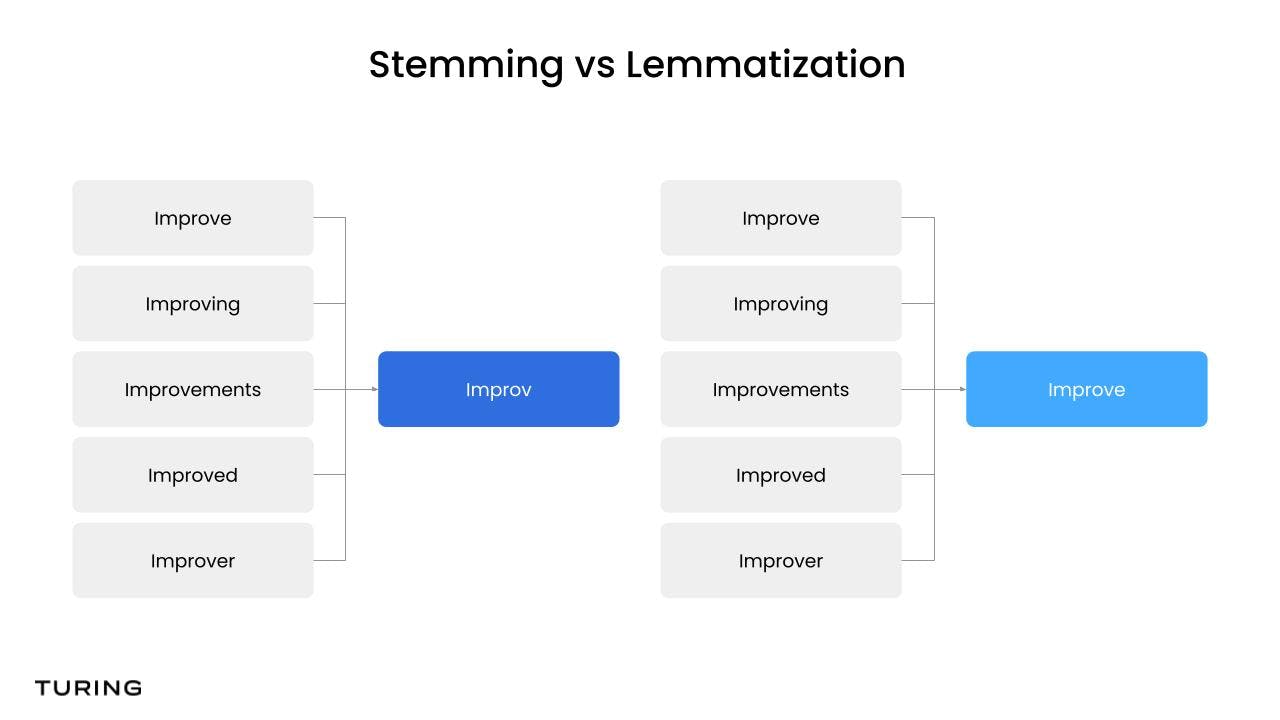
Stemming and lemmatization are crucial pre-processing techniques aimed at reducing words to their base or root form. These processes decrease the vocabulary size the model needs to learn.
Stemming is a rudimentary process involving the removal of suffixes from a word. On the other hand, lemmatization is a more sophisticated process that considers the context and part of speech of a word to accurately reduce it to its base form, known as the lemma. These techniques help simplify the text data to make it easier for the model to understand and learn.
b. Feature engineering
Feature engineering involves creating informative features or representations that make it easier for machine learning models to map the input data to the output. In the context of LLMs, feature engineering often translates to generating embeddings (word or contextual) that efficiently encode semantic and syntactic characteristics of words in a high-dimensional space, allowing the model to better understand and generate language.
Feature engineering is a strategic step for improving model performance by introducing additional knowledge or structure into the input data. While preprocessing prepares the data for analysis, feature engineering enhances data to make it more suitable for machine learning algorithms. The prominent techniques used in feature engineering are as follows:
1. Word embeddings
This feature engineering process involves mapping words or phrases to vectors of real numbers. These vectors represent words in a continuous embedding space where semantically similar words are in proximity to one another. Techniques such as Word2Vec, GloVe, and FastText are known for generating static word embeddings. Each provides a dense, low-dimensional, and learned representation of text data.
By capturing the context and semantic meanings, embeddings enable language models to process words in relation to their usage and association with other words, greatly benefiting tasks like text classification, sentiment analysis, and machine translation.
2. Contextual embeddings
Contextual embeddings are an advanced form of feature engineering that capture the meaning of words based on their context within a sentence, leading to dynamic representations. Unlike traditional word embeddings, which assign a fixed representation to each word, contextual embeddings capture the dynamic contextual nuances of words within a given sentence, as exemplified by models like GPT and BERT.
This contextual awareness allows them to better represent polysemy (words with multiple meanings) and homonyms (words with the same spelling but different meanings). For instance, the word "bank" can refer to a financial institution or the edge of a river. Traditional word embeddings would struggle to differentiate these meanings, but contextual embeddings would assign different representations to "bank" depending on context. Contextual embeddings enhance the performance of LLMs on a wide range of NLP tasks.
3. Subword embeddings
Subword embedding is a technique for representing words as vectors of subword units. This approach is useful for handling rare or out-of-vocabulary (OOV) words—the words not present in the model's vocabulary. The model can still assign meaningful representations to these unknown words by breaking down words into their constituent subwords.
Common subword embedding techniques are byte pair encoding (BPE) and WordPiece. BPE iteratively merges the most frequent pairs of subwords, while WordPiece segments words into characters and then merges the most frequent character pairs. These techniques effectively capture the morphological structure of words and enhance the model's ability to handle diverse vocabulary. Subword embedding improves the model accuracy by allowing it to capture finer semantic and syntactic relationships between words.
Advanced data processing techniques
Advanced data processing techniques are crucial for training large language models due to the complexity and high dimensionality of the data involved. LLMs deal with vast amounts of unstructured text data, which can contain thousands of features, making the training process computationally intensive and challenging. Advanced data processing techniques used to address these challenges include dimensionality reduction and feature selection. Let’s explore these techniques in brief.
a. Dimensionality reduction
Dimensionality reduction is a powerful data processing technique used to reduce the number of input variables in a dataset while retaining most of the original information. High-dimensional data can be challenging for LLMs as it increases computational complexity and can lead to overfitting.

Some prominent techniques used for dimensionality reduction are principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE). These techniques transform the original high-dimensional data into a lower-dimensional space to make it easier to process and visualize data. This process improves computational efficiency and helps identify patterns and structures within the data, enhancing the performance of LLMs.
b. Feature selection
Feature selection involves selecting the most relevant features for model training. In the context of LLMs, features could be words, phrases, or other text elements. With thousands of potential features in text data, identifying those that contribute most significantly to the model's predictive performance is crucial.
Prominent feature selection techniques include filter, wrapper, and embedded methods. These techniques evaluate each feature’s importance and eliminate those that are irrelevant or redundant. This process not only improves model performance and accuracy but also reduces overfitting and enhances computational efficiency.
Need help choosing the right features for your LLM?
Talk to an LLM ExpertChallenges in data processing
It’s critical to ensure due diligence when dealing with different data cleaning and processing methods to ensure high data quality, consistency, and accuracy. Some prominent challenges in data processing are as follows:
a. Overfitting
Overfitting is a common challenge in data processing, particularly in machine learning. It occurs when a model learns the training data too well and captures not only the underlying patterns but also the noise or outliers. As a result, the model may perform exceptionally well on the training data, but it often performs poorly on unseen data, as it fails to generalize.
Overfitting can be caused by having too many features compared to the number of observations or not using a proper validation strategy during training. Techniques like regularization, early stopping, and data augmentation can be employed to penalize complex models, prevent overtraining, and introduce more diverse data points to combat overfitting.
b. Handling large datasets
Large datasets, often referred to as "Big Data," can be difficult to manage due to their size, complexity, and the need for high computational power and storage. Processing such datasets can be time-consuming and requires advanced data processing techniques and data processing tools. Large datasets can also pose challenges to data privacy and security.
Specialized techniques and tools like distributed computing frameworks (such as Apache Hadoop and Apache Spark) are employed to handle large datasets. These frameworks facilitate parallel processing across multiple machines. Additionally, cloud computing platforms offer scalable storage and compute resources that can accommodate large datasets and enable efficient processing.
c. Dealing with unstructured data
Dealing with unstructured data presents a unique challenge in data processing due to its inherent lack of organization and predefined structure. Unstructured data includes various formats such as text documents, images, audio recordings, and videos.
Processing such data requires advanced techniques such as NLP for text, image recognition algorithms for visuals, and machine learning models capable of handling complexity and variability. As unstructured data becomes increasingly prevalent, developing robust methods for processing and extracting information from these sources is crucial for various applications, including machine learning.
Best practices for data processing

When processing the training data for LLMs, adhering to established best practices can significantly enhance the efficiency and accuracy of your results. These practices provide guidelines on handling data effectively to ensure its integrity and usability in subsequent analyses.
They also help mitigate common challenges, ensuring a smoother and more productive data processing journey. Best practices for data processing are as follows:
a. Rigorous data hygiene
Rigorous data hygiene is essential for training LLMs. This practice involves thorough data cleaning to remove inconsistencies, errors, or irrelevant information that could negatively impact the model's performance. You should establish standard operating procedures for cleaning and validating data.
Good data hygiene practices ensure that the LLMs are trained on reliable and high-quality data, leading to more accurate and robust models that contribute to the overall effectiveness of various applications.
b. Systematic approach to bias
Bias in data can lead to unfair, unrepresentative, or misleading outcomes in your language models. This includes explicit biases, such as discriminatory language, and implicit biases, such as underrepresentation of certain groups or perspectives.
You can systematically identify and mitigate biases through careful data curation, diverse dataset selection, and rigorous evaluation of model outputs for potential biases. By addressing bias, you ensure that your language models are fairer and more representative of the diverse contexts in which they will be used.
c. Continuous monitoring and feedback loops
Setting up systems to continuously monitor data quality and incorporate feedback for iterative improvement is essential for maintaining the relevance and reliability of language models. Organizations can proactively identify data drift, model degradation, or emerging biases by establishing robust monitoring mechanisms and feedback loops.
These systems enable timely intervention to rectify issues and enhance the overall performance of LLMs. This iterative approach, where insights from model outputs and user feedback are systematically integrated back into the data processing pipeline, ensures LLMs remain accurate and aligned.
d. Cross-functional collaboration
Cross-functional collaboration involves creating an environment where data engineers, machine learning engineers, and domain experts work together to ensure data quality and effective model training. Data engineers can provide expertise on data collection and cleaning, machine learning engineers can guide on feature extraction and model training, and domain experts can provide valuable insights into the data and the problem at hand.
This collaborative approach can lead to a more comprehensive understanding of the data, more effective data processing strategies, and ultimately, more robust and accurate language models.
e. Training and upskilling initiatives
Training and upskilling initiatives ensure data processing teams are equipped with the latest tools, techniques, and domain knowledge necessary for handling training data for LLMs. Regular workshops, seminars, and courses can be organized to keep the team updated on the latest developments in the domain.
Also, implementing a culture of continuous learning encourages team members to seek knowledge and improve their skills. This approach enhances a team's ability to handle complex data processing tasks effectively, leading to better quality data and more accurate LLMs.
Wrapping up
The data used to train and fine-tune an LLM defines how the model performs in real-world applications. It is critical to have a structured mechanism for data cleaning and processing to achieve an optimal output. LLM training is a comprehensive operation requiring skilled management of various data processing techniques and handling of multiple tech stacks, processes, tools, and platforms.
At Turing, we have significant experience in training and fine-tuning LLMs for various business applications. Our domain expertise in LLM training combined with our global engineering talent help clients build robust LLMs powered by highly relevant and synthesized datasets. Additionally, our emphasis on data safety, compliance, and best practices ensures risk mitigation while delivering excellent ROI for your project. Learn more on how our LLM services can help your business.
Talk to an expert today!
Struggling with inconsistent LLM performance? Start with better data
Poor preprocessing and low-quality inputs limit your model’s potential. Turing’s experts help you build robust, scalable LLMs through clean, reliable data pipelines and expert fine-tuning.
Train with Human DataAuthor
Huzefa Chawre
Technical content writer at Turing specializing in large-scale data quality operations, and model evaluation systems for generative AI. He has contributed to multimodal projects for frontier AI labs, leading initiatives across quality assurance, tooling optimization, and scalable data workflows.
Share this post

AGI Advance Newsletter
Weekly updates on frontier benchmarks, evals, fine-tuning, and agentic workflows read by top labs and AI practitioners.
Subscribe Now