How to Create a Python-Based Neural Network From Scratch
•5 min read
- Languages, frameworks, tools, and trends
- Skills, interviews, and jobs

Neural networks are analogous to the human brain. This is the comparison generally made to help someone new in the field wrap their head around the concepts of machine learning and artificial neural networks. A more sophisticated approach is to define these networks as a mathematical function, simply because under the hood, it's just layers and layers of mathematical and statistical calculations.
In this article, we will build an artificial neural network from scratch using Python.
Why build a neural network from scratch with Python?
Today's programmers have numerous libraries and frameworks that make their jobs easier by providing simple and reusable functions and methods. However, having a genuine understanding of how things actually work and how a neural network operates using various mathematical equations and functions is a skill on its own.
By learning the fundamentals of creating a neural network from scratch using libraries like NumPy, Pandas, and a few others - without the help of any machine learning frameworks like TensorFlow, Keras, Sklearn, etc. - you will gain a deeper understanding and appreciation of neural networks.
Steps to build a neural network from scratch using Python
Using the Iris species dataset
For this tutorial, we will use the popular Iris species dataset that can be found on Kaggle. Our data has six columns:
- Id: Indexing
- SepalLengthCm: Length of the sepals in centimeters
- SepalWidthCm: Width of the sepals in centimeters
- PetalLengthCm: Length of the petal in centimeters
- PetalWidthCm: Width of the petals in centimeters
- Species: Species name.
Importing libraries
Next, we’ll use Pandas to load and shuffle the dataset. A random shuffle like this helps make the data more homogenous and is a good practice to prevent overfitting in the future.
Let’s see our data:
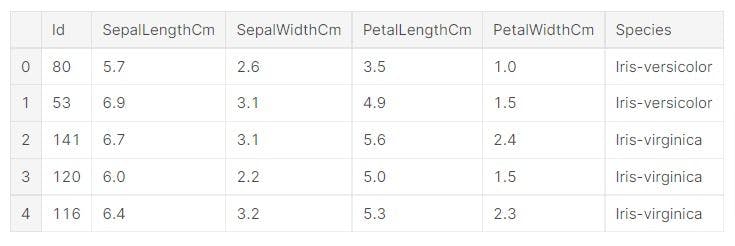
Next, we switch from pandas DataFrame to a numpy Array so that the data can be easily fed into our custom neural network.

Since the ‘Species’ column is categorical, we have to change it to one-hot encoded. As we’re still in the data preprocessing stage, it is easier to use the ‘OneHotEncoder’ from the sklearn.preprocessing library.

It’s now time for the test/train/validation split. We’ll again use sklearn for this.
Architecture of a deep neural network
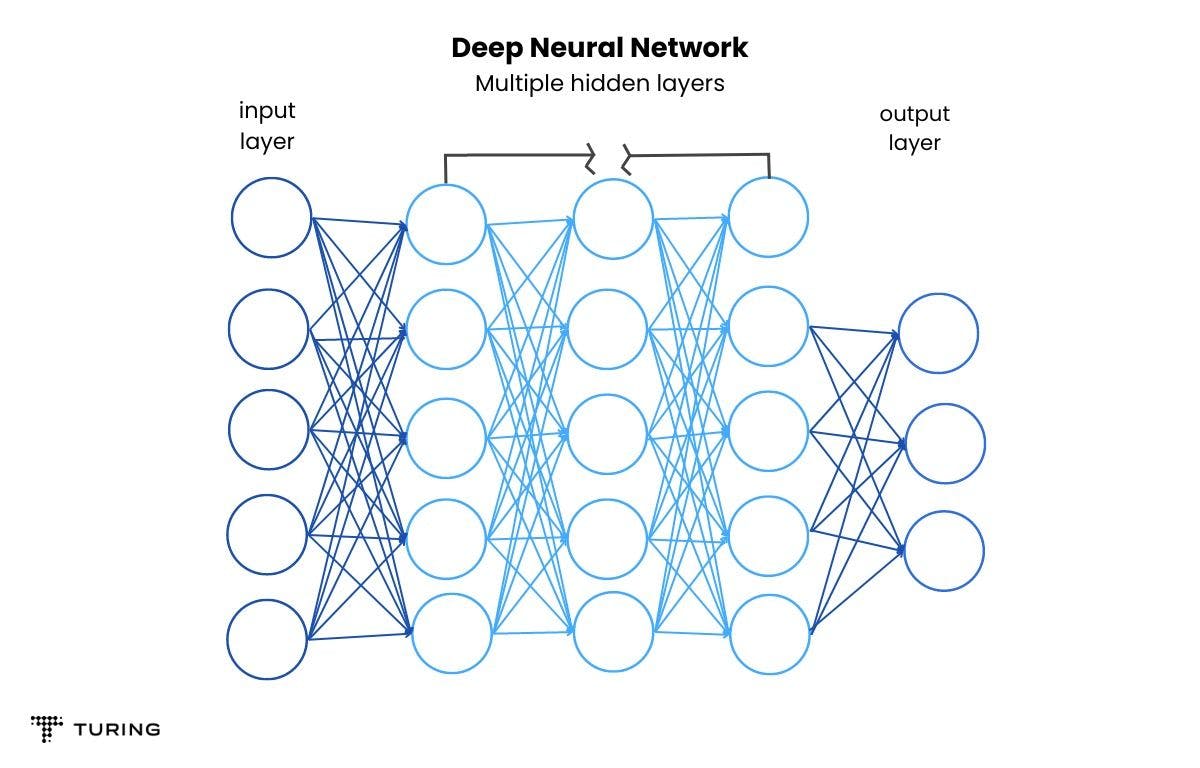
A neural network consists of:
- An input layer
- Single or multiple hidden layers
- An output layer
- Weights and biases to rank the features by importance
- An activation function, e.g., Sigmoid.
Let’s code the neural network class:
Where
- X_train, Y_train: The train set
- X_val, Y_val: Validation set (optional)
- epochs: Number of cycles (default = 10)
- nodes: An integer list of number of nodes in every layer
- lr: learning rate α (default = 0.15).
The function InitializeWeight is used to randomly initialize the weights of the nodes in the inclusive range of -1 and 1. For the implementation, we use numpy for random value generation:
These weights will be later updated using the famous backpropagation algorithm. For this to work, we need forward propagation where all the inputs are multiplied and added with their respective weights and biases.
Using forward propagation
- Every layer gets inputs from its previous layer, except the first layer of the neural network.
- The input values are then multiplied with their corresponding weights. Bias is added and passed through an activation function.
- The process is repeated across all layers. The output of the final layer is the prediction of our neural network.
Using backpropagation
Since we randomly initialize the weights at the beginning of the learning process, the output after the first run may be off course from the actual answer. The backpropagation algorithm is used to combat this by calculating the error from the final layer and updating the weights in the neural network accordingly.
Here’s the Python code:
All the different sections of our neural network are now built. The sample data is first sent through the network by forwarding pass. At the end of the layer, the errors are calculated and back-propagated to update the weights of the layers accordingly.
Here’s the Python implementation:
Using sigmoid activation function
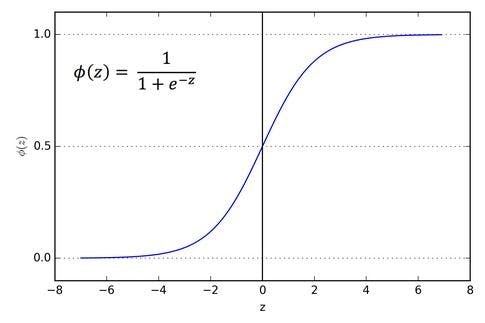
For our network, we’ll use a sigmoid activation function. The dot product of each layer is passed through an activation function which determines the final output of that layer. Sigmoid has a range of (0,1). It is mainly used in models where we require a prediction of probability (hence, the range 0 to 1). Since our model has to ‘guess’ the species of the flower, the sigmoid function is the best bet.
Prediction class
The final output from our network will be of the form [ i, j, k ], corresponding to the three classes where i, j, k are real numbers in the range [0,1]. The higher the value, the higher the chances of it being the correct class. Our job is to set the highest value at 1 and the rest at 0, where 1 denotes the predicted class.
Here’s the Python code :
Network evaluation
Finally, we evaluate the predictions of our neural network by taking in the predicted class and comparing it against the actual class to give us the accuracy in percentage.
Many types of evaluation metrics are available, but for the scope of this article, we will use a simple percentage measure.
Deploying our neural network
Our neural network is complete! Let's run it and check the results.
Output:

Now, it’s time to find our network’s accuracy:

Thus, we have successfully created a Python-based neural network from scratch without using any of the machine learning libraries. Practice this tutorial until you get the hang of building your own neural network.
FAQs
1. Can a neural network handle categorical data?
Ans: Yes, a neural network can handle categorical variables as easily as numeric ones. The trick is to change the categorical values into numeric form like we did use one-hot encoding to represent the three iris species into three distinct classes.
2. How does a neural network predict?
Ans: A neural network leverages weights and biases along with ‘backward propagation’ of the error to learn and predict more accurate outcomes.
3. What are neural networks used for?
Ans: Neural networks are the fundamental building blocks of deep learning architectures. Some of its applications are face recognition, stock price prediction, healthcare, weather forecasting, self-driving cars, etc.