Guide to Achieving Privacy in Data Mining Using Normalization
•7 min read
- Skills, interviews, and jobs

Data mining is defined as the process of extracting data from the many databases that exist. They store such massive amounts of data that extracting useful information is not easy using normal operations in a database management system (DBMS). Enter data mining which begins with data normalization to maintain the privacy of data. Since data can include sensitive information like medical records, criminal records, financial records of organizations and so on, the possibility of leaks is always a concern. This article will explore how to achieve privacy in data mining through data normalization techniques.
Types of normalization techniques
Data normalization is a scaling technique that allows one to find a new range from an existing range. It is a preprocessing stage for prediction or forecasting purposes. There are several normalization techniques such as min-max, Z-score, and decimal scaling.
Min-max normalization
Min-max normalization in data mining is a method that allows linear transformation on the original range of data. It can specifically fit the data in a predefined boundary. To map a value v of an attribute A from range [minA,maxA] to a new range [new_minA,new_ maxA], the computation is:
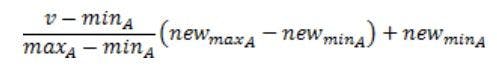
where v’ is the new value in the required range.
The merit of the min-max normalization technique is that it preserves the relationships among the original data values. It transforms original data to privacy-maintained data, maintaining the inter-relative distance among the data.
The procedure to apply min-max normalization is:
Step 1: Data owner extracts data from the databases
Step 2: Data owner identifies sensitive information in the dataset
Step 3: Sensitive data is altered using the min-max normalization process. The sanitized data is returned to the data miner.
Z-score normalization
Z-score normalization is a technique that gives the normalized values of data from original unstructured data using statistical methods like mean and standard deviation. It is expressed as follows:
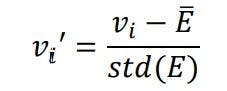
where
- vi’ is a Z-score normalized one value
- vi is the value of the row E of ith column
- std(E) is given by:
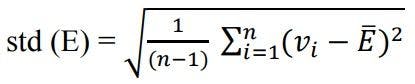
Decimal scaling normalization
This technique provides the data within the range of -1 to 1. The mathematical formula used for the conversion is:

Data privacy vs security
There’s a clear distinction between data privacy and security.
- Security has three fundamentals that include confidentiality, integrity, and availability. It can be defined as a facility to control unauthorized access to confidential information, its modification, and loss.
- Privacy can be termed as the right of an individual to control disclosure of his/her personal information, which is mostly achieved through policies and procedures.
Privacy preserving in data mining (PPDM)
Privacy preserving in data mining (PPDM) is a new field of research in the data mining process that aims to extract useful knowledge from large amounts of data without exposing sensitive data to third parties. There are several PPDM methods as discussed below:
- Data hiding techniques: Here, the input data is altered and trimmed in such a way that the sensitive data isn’t exposed to third parties. This is a useful technique as no data is removed and, hence, the integrity of the data is preserved.
- Knowledge hiding techniques: In these techniques, the sensitive information is removed, further reducing the leak of sensitive data which can otherwise be used to derive confidential information.
- Hybrid technique: While data hiding and knowledge hiding techniques possess advantages and disadvantages, the hybrid technique utilizes the merits of both.
Data hiding techniques
In data hiding, sensitive raw input data is modified, blocked, or trimmed out from the original database so that users of the data will not be able to compromise another person’s privacy. The following flowchart summarizes the different techniques involved in data hiding:
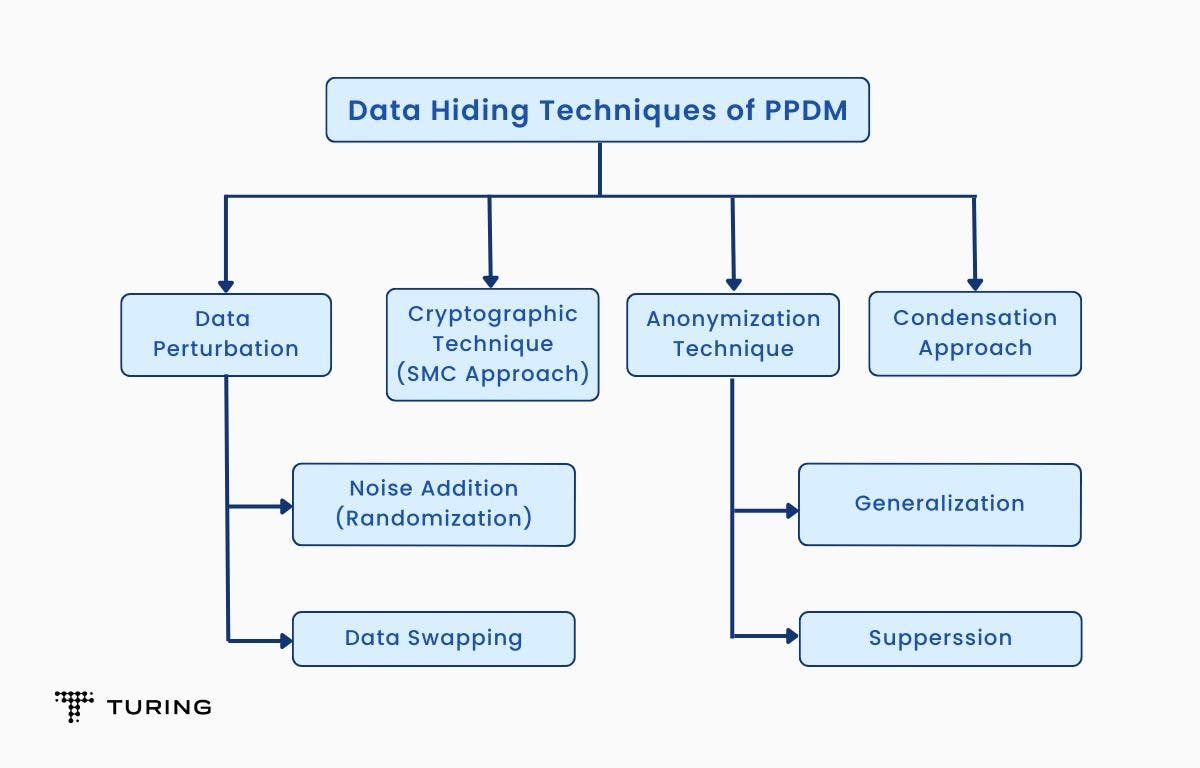
A) Data perturbation: Here, the raw data is modified such that users of the data can’t hamper privacy. This is usually achieved through numerous techniques like adding noise to the data, swapping, etc. It’s important to note that the quality of the data is maintained after its release.
In noise addition, the owner of the data adds a random number (referred to as noise) to input data. This random number is usually drawn from a normal distribution with zero mean and a small standard deviation which maintains the statistics of the original data.
Data mining reconstructs the original dataset’s distribution by using distribution of the noise added to the original data and noisy data.
This is illustrated below:
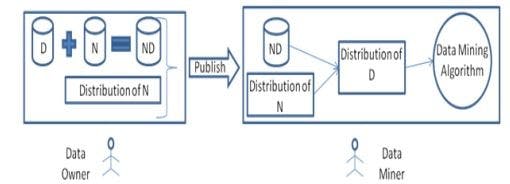
In case of data swapping, records with similar attributes are interchanged with higher probability. This makes the task of re-identification very complex and, hence, the privacy of data is ensured.
B) Cryptographic technique: This method ensures privacy by using cryptographic and secure multiparty computation (SMC) techniques. In SMC, parties hold their own private data and cooperate in computation to get the final result, ensuring that no participant involved in computation is shown more information other than his/her input data and final output.
C) Anonymization technique: This technique involves the removal of sensitive or identifying information from input data such that the identity of the person is not revealed. This is usually achieved by the k-anonymization approach. A table is said to be k-anonymized if each row is not distinguishable from the other k-1 rows by looking at a set of attributes.
D) Condensation approach: This technique helps to preserve data covariance. The original data is first partitioned into multiple groups of predefined sizes. Statistical information (e.g., mean and covariance) for each of the groups is maintained. The information is used for creating anonymized data that has similar statistical characteristics to the original dataset. The anonymized data obtained is then released for data mining applications.
Knowledge hiding techniques
In knowledge hiding techniques, the extracted data is filtered so that all the sensitive information is removed. Knowledge hiding comprises the following types:
1. Association rule hiding: This involves modifying data so that certain sensitive rules disappear without affecting the data and non-sensitive rules. Association rule mining algorithms retrieve only those rules that have support and confidence higher than the user-specified minimum support and confidence threshold during the scan of the database transaction. Hence, support and confidence of the sensitive rule is decreased below the threshold so that they are not retrieved.
2. Query auditing: This technique involves examining the queries that were made in the past by an individual. It determines whether answers to these queries from the database could ascertain confidential information forbidden by the disclosure policies.
Hybrid technique
The hybrid technique is a combination of randomization and generalization techniques applied to raw data. Randomization is first applied on the raw data and, thereafter, generalization is applied on the randomized data. The technique has proven to be more accurate than knowledge hiding and data hiding techniques as there is no information loss. Hence, original data can be reconstructed from the modified data.
Privacy is vital in data mining tasks. At the same time, it is more challenging to protect privacy when computation tasks are being carried out. Finding an optimized solution that minimizes computational overheads and balances information loss is still a topic of research. Currently, there is no ideal approach that provides the best solutions under different scenarios.
FAQs
1. How do you normalize data mining?
Ans: Normalizing data mining involves three basic steps:
- Calculate the range i.e. max(x) - min(x) .
- Subtract the minimum from the value V
- Divide the result from step 2 by range obtained in step 1.
2. What are the data normalization methods?
Ans: There are several methods but normalization in data mining is done using two main techniques: min-max normalization and z-score normalization.
3. What are the three stages of normalization?
Ans: The three stages are first normal form, second normal form, and third normal form. In first normal form, the columns of the data should have atomic as well as unique values. In second normal form, the data should be in first normal form and should have partial dependency. In third normal form, the data shouldn’t have transitive dependency.
4. What is data normalization with an example?
Ans: Data normalization is a scaling technique that allows one to find a new range from an existing range so that users can utilize it for further queries and analysis. For example, to normalize the data (1000,2000,3000,9000) using min-max normalization by setting min:0 and max:1, the records are transformed to (0, 0.125,0.25,1).