All You Need to Know About Data Wrangling and Importing CSV in Python
•8 min read
- Languages, frameworks, tools, and trends

Data wrangling, also known as data mungling, is a process that removes the risk of losing valuable insights from refined data. It ensures that data is in a reliable state before it is analyzed. The entire process is focused on cleaning the data and maintaining a specific format before uploading it to a database. It can be a time-consuming process when conducted manually. This article will discuss data wrangling in Python, lay out the steps to write files with Python CSV writer, and much more.
Importance of data wrangling in Python
Data wrangling is implemented by companies and enterprises to guide business decisions, optimize solutions, and solve data-dependent business issues. If data is not refined or is incomplete, the analysis reduces the value of insights that are derived.
Data wrangling steps
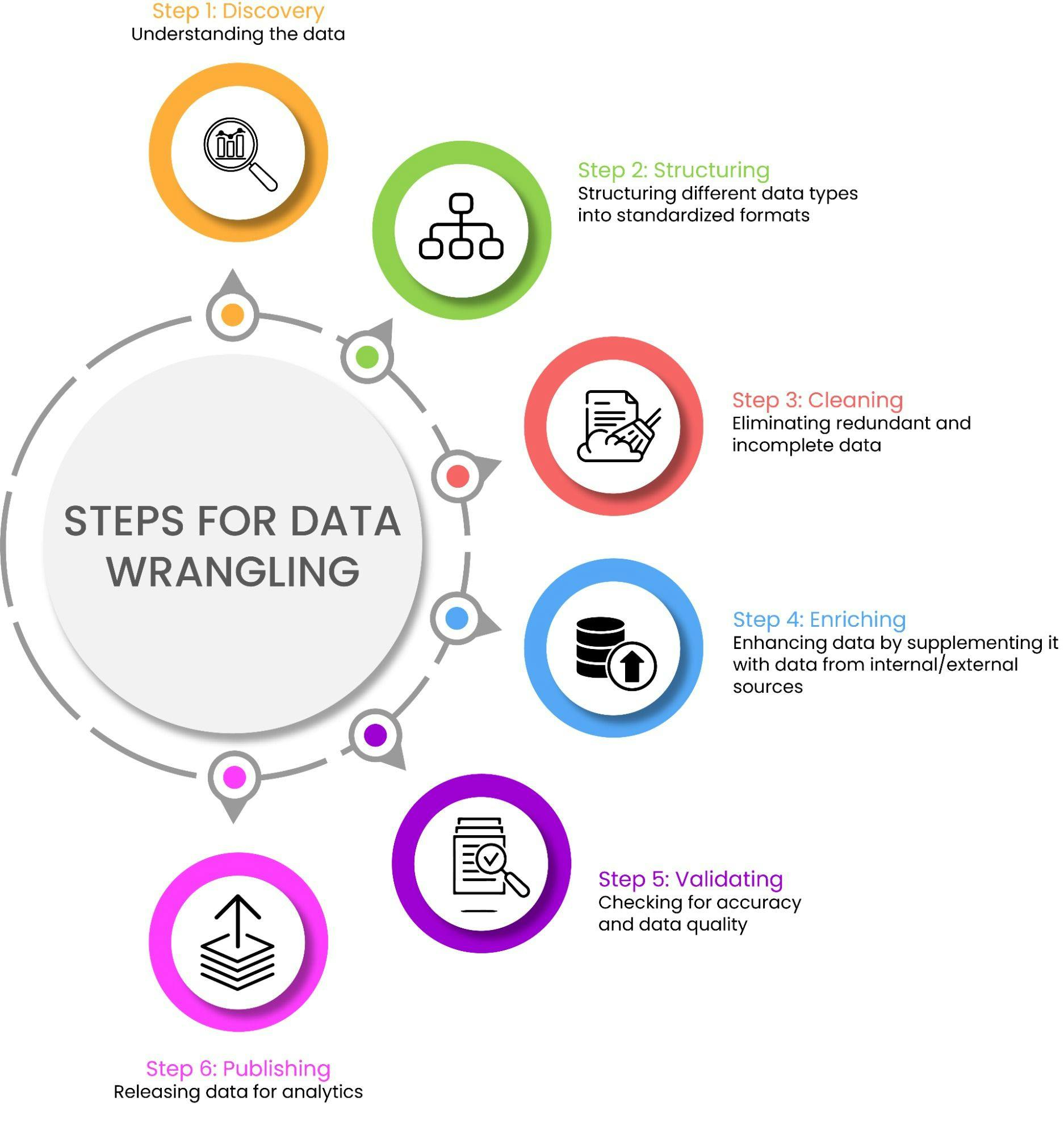
It is impossible to select a single data science skill set that is the most important for business professionals as the insights are only as good as the data that governs them. Thus, it is vital to shape raw data into a usable form. This is where data wrangling helps as it cleans and enriches the data.
The exact tasks required in data wrangling depend on the type of transformations implemented to make a dataset usable. Below are the steps involved:
Step 1: Discovery
The first step involves discovering what type of information is contained in a data source and deciding if it has some value. Discovery is a small process in the entire data analysis operation and is a good way to explore the data. It is an opportunity to understand the data in-depth. Wrangling divides the data according to consistency and quality.
Step 2: Structuring
Standardizing the data format for the different data types makes it usable for various processes. Raw data does not have structure as, in most cases, it comes in different formats and there is no predefined structure. It needs to be restructured so data analysts can use the same for further analysis.
Step 3: Cleaning
Cleaning eliminates redundant and incomplete data that could skew the entire data analysis process. In this phase, high-quality analysis takes place. Data containing Null Values is changed either to an empty string or zero. This is followed by standardizing the format to clean the data to a higher quality. The goal is to get pure data that is ready for the final analysis.
Step 4: Enriching
Enriching entails deciding if there is enough data or if we need to seek out additional interior or third-party sources. Here, the data is transformed into a new kind of data, going from being cleaned to its formatted version. The ideal way to achieve this is to upscale, downsample, and, finally, predict the data.
Step 5: Validating
Validating deals with conducting tests to expose data quality and consistency issues. Data quality rules are used to evaluate the quality of datasets. Both consistency and quality are verified once data is processed. These parameters help establish a strong base upon which to tackle security issues. The tests are conducted along with multiple dimensions that adhere to the constraints of the syntax.
Step 6: Publishing
Publishing is all about making wrangled data available to stakeholders in downstream projects. It is the last step of the data wrangling process. The final form of the data is matched to its format which is then used for analytics.
Aspects of data wrangling in Python
Data wrangling in Python deals with the following:
Data exploration
This involves visualization of data. Here, the data is analyzed and understood.
Dealing with missing values
It is common to have missing values when analyzing large datasets. Replacing the missing values with either NaN values or by mean or mode takes care of the problem.
Reshaping data
The data is modified from the pre-existing form to a usable format according to requirements.
Filtering data
Unwanted data in rows and columns is filtered and removed. Filtering data compresses it, saves memory, and generates a dataset.
Analysis
After converting data into a dataset, it is analyzed for data visualization, model training, etc.
Now that we’ve learned about data wrangling and why it’s important, let’s take an example to understand it better.
Code fragment:
Output:
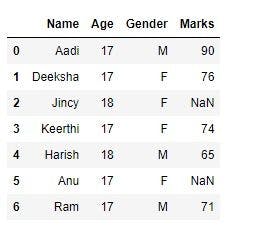
In the above example, data wrangling is performed in a tabular format.
We now move on to CSV in Python.
What is a CSV file?
A CSV file is created by programs that handle large amounts of data. It is a convenient way to export data from spreadsheets and databases. It is easy to create and work with. Any language that supports text files and string manipulation can work easily with CSV files.
But what exactly is a CSV file and how does it work?
A CSV file is a type of plain text that uses specific structuring to arrange tabular data. As it is just a plain text file, it only has text data or ASCII characters. The name of the CSV file defines its structure. Normally, it uses a different and specific data value.
The CSV format is the most common format for importing and exporting datasets and spreadsheets. There is a small difference between the data produced and consumed by various applications and software. The CSV module enables classes to read and write tabular data in CSV format. This allows developers to write the data in Excel format.
How will you load a CSV file in Python?
You can read a CSV file by using the ‘reader’ object. The CSV file opens as a plain text file with Python’s built-in ‘open()’ function. The function returns a file object which then gets passed to the reader.
Here’s an example of an employee_birthday.text file:
name,department,birthday month
Jay,Marketing,May
Svetlana,Recruitment,March
Here is the code to read the above file:
Code:
Here is the output of the above code:
Column names are name, department, birthday month
Jay works in the Content department, and was born in May.
Svetlana works in the Recruitment department, and was born in March.
Processed 3 lines.
You can see that dictionary keys have entered the picture. Where did they come from? The very first line of the CSV file contains the keys that can build the dictionary. You need to specify them by setting an optional parameter to the list containing the field names.
Optional reader parameters
The ‘reader’ object can handle multiple formats of CSV files by specifying additional parameters. They are discussed below:
- The ‘delimiter’ specifies the number of characters to be used for each field. By default, the delimiter is the comma symbol (,).
- The ‘quotechar’ parameter specifies the number of characters used around the fields that contain the delimiter character. By default, the quotechar is a double quote (“).
- The ‘escapechar’ parameter specifies the number of characters used to escape the delimiter if the quotes are not used. By default, it is a no escape character.
Here’s an example to understand how these parameters work.
CSV file
name,address,date joined
Jay,1132 Anywhere Lane Hoboken NJ, 07030,May 26
Svetlana,1234 Smith Lane Hoboken, NJ 07030,March 14
The CSV file above has three fields:
- Name
- Address
- Date of joining
These fields are delimited by commas. However, there is an issue with the data for the address field as it also contains a comma for the zip code.
Considering the above example, there are different ways to tackle the issues associated with data.
Using a different delimiter
This solution allows you to use the comma in the data safely. Apart from this, you can use the optional parameter to specify the new delimiter.
Using quotes to wrap the data
The significance of the delimiter is lost when mentioned inside quotes. To avoid this, you can specify the character used for quoting with the quotechar optional parameter.
Escaping delimiter characters in the data
The escape characters work just like format strings and nullify the interpretation of the characters being used. When using an escape character, you need to specify the escapechar parameter.
Writing files with Python CSV writer
You can also write files with Python CSV writer using the ‘.write_row()’ and the ‘writer’ object.
Here, the ‘quotechar’ optional character tells the user which character can be used to quote the fields when writing.
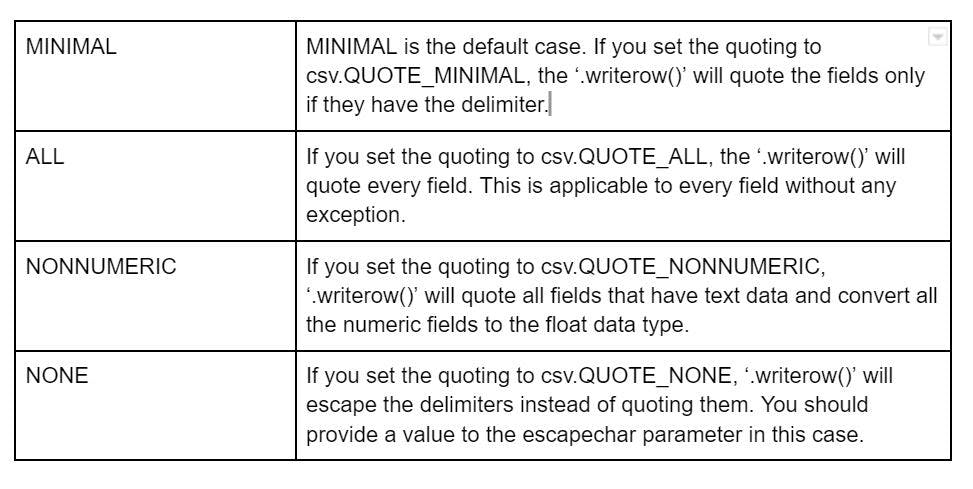
There are four modes that can be used to set the quote format:
- Minimal
- All
- NonNumeric
- None
Here’s a brief look at the modes:
We have learned how important data wrangling is as well as its potential to transform the entire data analysis and related processes. As data science deals with filtering raw data to optimize it for the best results, you should always perform data wrangling before filtering and processing it for analysis.
FAQs
1. What is an example of data wrangling?
Data Wrangling can be an automated process. Here are a few examples of Data Wrangling:
- Removing or deleting the data that is unwanted or is unnecessary to the project that you are working on.
- Identifying the observation in the data and enriching it for further analysis.
- Identifying the gaps in modifying the empty rows and columns in spreadsheets.
- Blending various data sources into a single data set for further analysis.
2. Is data wrangling the same as data cleaning?
No. Data Wrangling and Data Cleaning are not the same. Data cleaning deals with removing the raw data from the data set. On the other hand, Data Wrangling deals with filtering the data format by enriching the raw data into a more usable form.
3. What is csv file handling in Python?
A CSV file stores the tabular data in a plain text format (text and numbers) wherein every line of the file is a data record. Every record consists of one or more fields that are separated using commas.
There are multiple ways to handle a CSV file in Python including Pandas library or the CSV module.
CSV Module:
The CSV module is one of the dominant modules in Python that offers classes to perform reading and writing the tabular information.
Pandas Library:
Pandas Library is a powerful open-source library that offers powerful data structures and analysis tools to handle CSV files in Python.
4. What is the function of data wrangling?
The main function of the Data Wrangling is to convert the raw data into a compatible format for the end-system and improve its usability. Its goal is to assure usefulness of data and data quality. This technique helps to streamline and automate the data-flow within a user interface.
5. What is data wrangling vs ETL?
Data Wrangling technique handles the complex data whereas, Extract, Transform, Load (ETL) handles the data that is well-structured. This well-structured data comes from different sources including databases and operational systems. The Extract, Transform and Load are the database functions combined into one single tool to fetch the data from one database and put it in another. ETL function is used when an enterprise wants to discontinue or terminate a particular data storage solution and moves it to a new storage.