All You Need to Know About Computer Vision
•7 min read
- Languages, frameworks, tools, and trends

Computer vision is the ability of computers to recognize and extract data/information from objects in images, videos, and real-life events. Unlike humans, computers have a hard time processing visual data. While we can interpret what we perceive depending on our memories and prior experiences, computers cannot. To bridge the gap between what they see and understand, computers employ artificial intelligence (AI), neural networks, deep learning (DL), parallel computing, and machine learning (ML).
This article will explore computer vision technology, the algorithms at play, the types of computer vision techniques, and more.
The functioning of computer vision
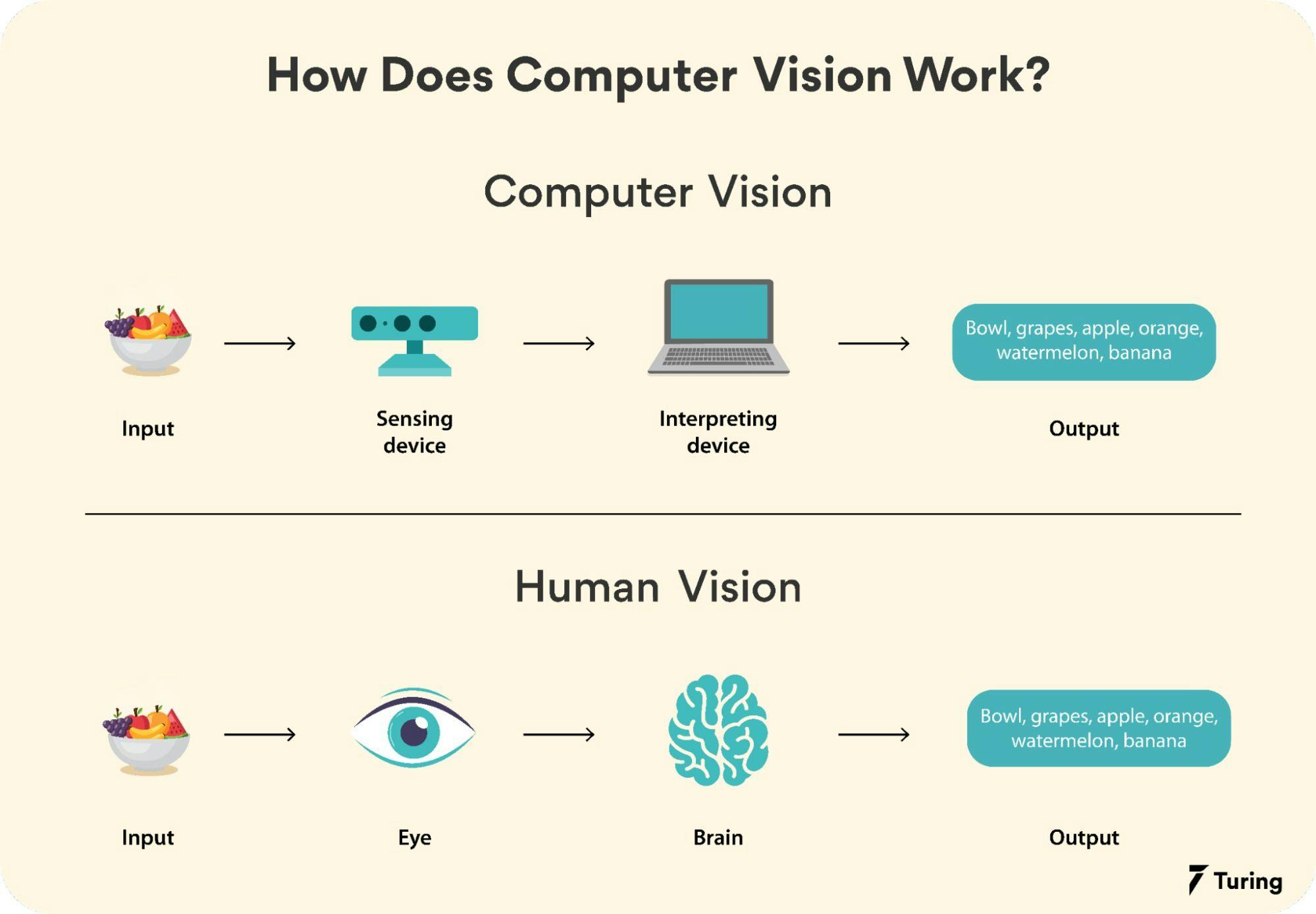
Instead of looking at an entire image like we do, a computer divides it into pixels and uses the RGB values of each pixel to understand if the image contains important features. Computer vision algorithms focus on one pixel blob at a time and use a kernel or filter that contains pixel multiplication values for edge detection of objects. The computer recognizes and distinguishes the image by observing all aspects of it including colors, shadows, and line drawings.
Today, we use convolutional neural networks (CNNs) for modeling and training. CNNs are special neural networks, specifically designed for processing pixel data, used for image recognition and processing. The convolutional layer contains multiple neurons and tensors. These process large datasets by learning to adjust their values to match characteristics that are important for distinguishing different classes. This is done by extensively training the model.
One way to help computers learn pattern recognition is to feed them numerous labeled images so that they can look for patterns in all the elements.
For example, if you feed a million pictures of a ‘lion’ to a computer, they will go through algorithms that analyze the color, shape, distance between shapes, boundaries between objects, etc., so that they become profiles. The computer can then use the experience when fed other unlabeled images to know whether an image shown is that of a lion.
Here’s a real-life scenario for better understanding.
Consider the image below to store the number ‘8’ in the form of an image.

Image source: Analytics Vidhya
If we zoom in to the image close enough, we will see that it looks something like this:

It’s evident that the image above is represented by different blocks. These blocks are called pixels. Note that we represent any image’s dimension as X * Y. This means that the image has a total of X*Y pixels.
The computer does not store the image as we see it, but does so in the form shown below:
![]()
Image source: mozanunal
As you can see, each block or pixel is specified by a particular value. The values denote the intensity of each pixel. A number closer to zero represents a darker shade and a higher number represents the opposite.
Things get a bit complex with colored images as we have to represent the values in RGB format, i.e., each pixel is represented by three different values. For example, if the image dimension is 1612, we would need a total of 1612*3 values in order to represent the RGB values. Any algorithmic model has to iterate over each of these pixels many times to get trained successfully. We would need thousands of images to efficiently train a model for a particular case.
The growth of computer vision
Prior to the introduction of deep learning, the operations that computer vision could perform were so limited that they required a lot of human assistance and interference. For example, if we wanted to perform facial recognition, we had to follow these steps:
- Store the data: Manage a database that would contain all the faces of the subjects that we wanted to track.
- Image annotation: Store the key features of the images such as the distance between the lip and the nose, facial width, facial length, length of the eyes, etc., all of which are unique for every person.
- Apply findings to a new set of images: Repeat image annotation for a set of new images and compare the unique features.
Today, machine learning allows us to recognize and address computer vision problems.
Developers no longer have to manually code each and every rule into their vision apps. They have compact programs called “features” that can identify particular patterns in images. They employ support vector machines (SVM) or linear regression to categorize images and find objects using an applied mathematics learning method like k-means or logistic regression.
The advent of deep learning has given a completely different approach to machine learning. Neural networks, a universal operation that may resolve any drawback expressible through examples, are the foundation. They can extract common patterns between instances after being given multiple labeled samples of carefully chosen data. This equation helps them categorize future pieces of information.
For instance, developing or choosing a preconstructed algorithmic rule and training it with instances of the faces of the people it should recognize is what is required to create a face recognition application using DL. The neural network can recognize faces given enough examples - and there are plenty - without further guidelines or measurements.
Applications of computer vision

Deep learning is used in the majority of modern computer vision applications including facial recognition, self-driving vehicles, and cancer diagnosis, to name a few.
Facial recognition
As discussed, computer vision is extensively used in facial recognition systems, thanks to its ability to find patterns in elements in the data. It then makes recommendations or takes action based on the data.
Self-driving vehicles
Computer vision enables autonomous vehicles to gain a sense of their surroundings by creating 3D maps out of real-time images. Cameras capture video from different angles around a car and feed it to computer vision software. It processes it to identify the extremities of roads, browse traffic signs, and discover alternative cars, objects, and pedestrians. The car can then steer its approach on streets and highways, avoid obstacles, and drive its passengers to their destination.
Healthcare
Computer vision has been used in a variety of healthcare applications to help healthcare professionals make better decisions related to patient care. Medical imaging or medical imaging analysis is one such procedure. It creates visualizations of specific organs or tissues to enable a more accurate diagnosis.
Augmented reality (AR)
Computer vision is implemented in augmented reality to extend imagery and sound to real-world environments. It detects real-life objects through the lens of, say, a smartphone, and performs computational operations. Among other things, we can use AR to measure the height of a table merely by using a smartphone’s camera.
Super-resolution imaging (SR)
SR is a technique that enhances the resolution of images. It is achieved with the help of four methods or algorithms: enhanced deep super-resolution network (EDSR), efficient sub-pixel convolutional neural network (ESPCNN), fast super-resolution convolutional neural network (FSRCNN), and Laplacian pyramid super-resolution network (LapSRN). These pre-trained models can easily be downloaded and used.
In super-resolution imaging, the model interprets numerous low-quality images differently, leading to the treatment of all the images as having unique information. Once the variations between the photographs are analyzed, the model produces a stream of images of significantly higher quality.
Optical character recognition (OCR)
OCR extracts text from images, scanned documents, and image-only PDFs. It identifies letters and puts them into words and sentences. The text is read using various contouring and thresholding techniques. Libraries like OpenCV are commonly used.
OCR technology is widely used to digitize text, scan passports for automatic check-in, evaluate customer data, etc.
Techniques of computer vision
Computer vision comprises various techniques such as semantic segmentation, localization, object detection, instance segmentation, etc. They can be applied to calculate the speed of an object in a video, create a 3D model of a particular scenario that has been inputted, and remove noise from an image, such as excessive blurring.
Semantic segmentation
Semantic segmentation groups pixels together and classifies and labels them. This helps determine if a particular pixel belongs to a particular object class. For example, it is used to identify if that pixel is from an image of a cat or a dog. It identifies the image label (in this case, either a cat or a dog).
Localization
In localization, an image is given a label that corresponds to the parent object. The object is located and a bounding box is drawn around it. This acts as a point of reference for object detection.
Object detection
Object detection is a method to find occurrences of real-world objects such as faces, bikes, and buildings in images and videos. Learning algorithms are used to identify the instances of the objects.
Instance segmentation
Instance segmentation detects and identifies instances from the above processes, and gives a particular label to the pixels. It is often used in the real world, such as in self-driving cars, smart farming, and medical imaging.
In this article, we discussed how computer vision works, the techniques used, the applications, and more. While there have been remarkable advances in this field over the years, challenges remain such as data quality, hardware limitations, optimizing deep learning models, etc. However, the demand for computer vision, the ongoing research, and evolving technologies will continue to improve it in the years to come.

Author
Turing Staff