
The emergence of large language models (LLMs) has dramatically reshaped countless industries—perhaps none more rapidly than education. Traditional paradigms of teaching, learning, and knowledge access are being redefined at breakneck speed. The pace of innovation is unprecedented, and the stakes—shaping the future of human learning—are exceptionally high.
But building effective AI systems for education is no ordinary task. Unlike narrow, single-purpose applications, educational needs are broad and diverse. Depending on the user’s goals, the AI may need to ask Socratic questions to guide conceptual understanding, engage in deep reasoning to craft meaningful explanations, retrieve up-to-date information from the web, or use specialized tools—like a code interpreter to help a user extract insights from data. A single, monolithic model can’t meet all these demands. We need a diverse set of AI agents, each equipped with the right instructions, reasoning strategies, and toolsets tailored to different educational contexts.
To support this, AI labs developing these agents must stay closely aligned with real-world user needs. It’s not enough to optimize models in isolation—researchers need a platform where they can evaluate their latest systems with actual users, gather feedback at scale, and iterate rapidly to keep pace with the evolving landscape of learning.
This is where EDU Arena comes in—a platform purpose-built to connect advanced AI development with the real needs of learners and educators.
What is EDU Arena?
EDU Arena is a platform for building, deploying, and evaluating AI agents purpose-built for education. At its core, EDU Arena serves two complementary goals:
- Giving users access to AI agents tailored for a wide range of learning tasks, and
- Enabling AI researchers and labs to test, iterate, and improve their models through structured, real-world feedback.
EDU Arena isn’t just another AI product—it’s an evolving bridge between AI innovation and educational impact. By bringing users and builders together on the same platform, EDU Arena fosters a shared space for experimentation, feedback, and rapid iteration. As the future of education continues to shift, EDU Arena ensures that AI doesn’t just keep up—it helps lead the way.

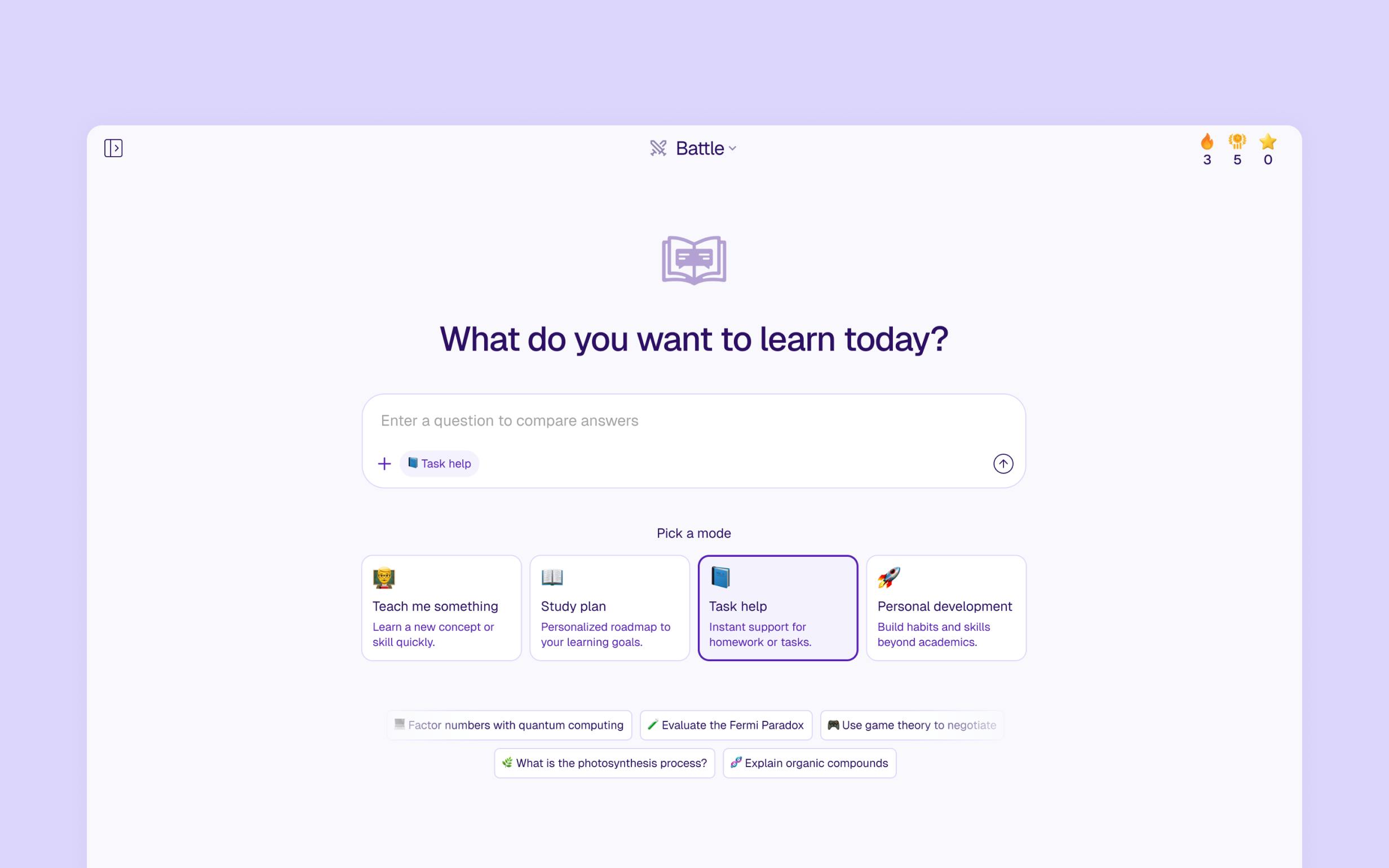
A playground for learners
For learners, EDU Arena offers a growing ecosystem of specialized AI agents called “Tutors,” each designed to support a wide range of educational needs. Whether it’s mastering challenging concepts in math or biology, preparing for an upcoming exam, getting help with homework, analyzing code, visualizing data, or synthesizing academic literature—these Tutors are built to assist across disciplines and learning levels.
Unlike generic chatbots, EDU Arena Tutors are guided by educational intent. They incorporate subject-specific reasoning strategies and are often equipped with powerful tools like web search, image generation, or code interpreters to more effectively address the user’s goal. And we’re just getting started: in the near future, EDU Arena will allow users to create and customize their own Tutors—tailored to their unique learning needs or teaching styles.
To encourage high-quality educational interactions, EDU Arena features an intelligent, point-based gamification system. Users earn points for submitting well-crafted, challenging questions, voting on which model performed better, and providing detailed feedback. These points contribute to global user leaderboards, where participants are ranked based on their contributions. To further boost engagement, we’ll soon launch subject-specific and geo-specific leaderboards, allowing users to see how they rank within particular domains or regions. This system not only fosters meaningful participation, but also generates high-quality signals that fuel more accurate and nuanced model evaluation.
A testbed for AI labs
For AI labs, EDU Arena serves as a real-world testbed for deploying and evaluating their latest models. Labs can use the platform to observe how their models perform across a diverse range of users, subjects, and learning tasks.
EDU Arena goes far beyond traditional side-by-side model comparison platforms—pioneered by projects like Chatbot Arena. While such platforms provide large-scale benchmarking, they typically treat all user input equally and rely solely on simple preference votes. EDU Arena reimagines how AI models for education should be evaluated—by combining user expertise modeling with structured, high-quality feedback at scale.
1. Expertise-aware evaluation
All users on EDU Arena are verified and authenticated, enabling us to build dynamic profiles that reflect each user's expertise across different topics. As users engage with the platform—submitting questions, voting on model outputs, and providing feedback—EDU Arena continuously assesses their domain knowledge, consistency, and engagement quality.
We take into account multiple factors, including:
- The quality and subject coverage of the questions they ask
- The reliability and consistency of their votes
- The depth and clarity of their written feedback
- Their language proficiency and regional context
This profiling enables differentiated weighting: evaluations from users with demonstrated subject-matter expertise or relevant background are given greater influence. The result is more trustworthy, fine-grained model scoring—grounded in context, not just crowd consensus.
Furthermore, EDU Arena allows AI labs to run targeted evaluations—filtering results by user profile, subject, region, or educational level—to better understand how their models perform within specific learner segments or deployment contexts.
2. High-quality feedback at scale
EDU Arena pairs this expertise modeling with a robust point-based engagement system that incentivizes users to go beyond simple votes. Users are rewarded for:
- Asking high-quality, challenging educational questions
- Comparing model outputs with rubric-based evaluations
- Providing detailed written feedback explaining their choices
This rich stream of input powers EDU Arena’s real-time post-processing pipeline, which transforms raw user interactions into actionable insights. The pipeline:
- Classifies prompts by subject area, difficulty, and educational level
- Assesses prompt quality
- Evaluates model responses using a combination of structured rubrics, written feedback, and user preferences
- Detects cases where a model fails to understand the query—surfacing blind spots, reasoning gaps, and domain-specific weaknesses
This infrastructure enables AI labs to gain granular, diagnostic insights into model performance—not just whether a model succeeds or fails, but why, and in what context.
To further support the research community, EDU Arena publicly shares key insights in two primary ways. First, through leaderboards that are calculated using Bradley-Terry Elo scores, derived from user votes. These leaderboards offer a dynamic and trustworthy view of how different models perform across a variety of educational tasks. Second, we publish in-depth case studies that highlight emerging trends in agent behavior, surface common failure patterns, and provide detailed analyses of model performance across different subjects and skill levels. Together, these public results empower researchers, builders, and educators to track progress, pinpoint weaknesses, and collaboratively shape the next generation of educational AI systems.
Key results
To date, EDU Arena has successfully engaged over 48,444 users, who have collectively contributed more than 99,127 votes—with approximately 81,000 of those including rubric-based or written feedback. This has resulted in a rich and reliable dataset for assessing and improving state-of-the-art (SOTA) AI models in education.
As illustrated in the following charts, about 62% of all questions asked on EDU Arena are at the high school level, while fewer than 25% target undergraduate or graduate-level content. Subject-wise, around 60% of the questions come from physics, mathematics, and chemistry, with another 15% focused on coding-related topics.
User feedback also provides insight into model strengths and weaknesses. Based on vote justifications, 32% of users cited correctness as the main reason behind their choice—highlighting the varying capabilities of models in accurately solving domain-specific problems. Meanwhile, 54% of responses referenced clarity or completeness, reflecting the importance of explanation quality. Interestingly, 12% of votes were influenced by formatting, suggesting that formatting differences among leading AI models are relatively minimal.
Educational level

Subject

Feedback category

Leaderboards and model analysis
EDU Arena features multiple leaderboards that rank state-of-the-art (SOTA) language models based on user feedback across diverse evaluation dimensions. These leaderboards highlight overall performance, effectiveness on graduate-level topics, and proficiency in multimodal reasoning. Currently, EDU Arena supports 26 models from leading AI labs—including OpenAI, Google DeepMind (Gemini), and Anthropic—available through both direct query and side-by-side comparison modes. However, only the top nine SOTA models are included in battle mode and considered for official rankings. We are actively expanding coverage by integrating additional SOTA models from other vendors to enhance the user experience and enable more comprehensive cross-model comparisons. These insights help AI labs identify key strengths and areas for improvement, supporting the continuous refinement of models for educational applications. Selected results are presented below.
Models ranking based on Elo scores

We evaluate the relative performance of SOTA LLMs using Elo ratings derived from pairwise comparisons. This method offers a clear view of overall model performance while highlighting subtle differences among various models.
The Elo leaderboard (shown in the figure above) ranks Gemini-2.5-Pro and Gemini-2.5-Flash as the top-performing models, consistently outperforming other models across evaluations. Their high scores combined with narrow confidence intervals (represented by short horizontal lines) indicate robust and reliable performance. Claude-Opus-4 ranks third, followed closely by GPT-4.1 and Claude-Sonnet-4, forming a competitive tier of high-performing AI models. In contrast, O4-mini and O3 rank lowest, reflecting consistent underperformance in direct comparisons.
Models head-to-head win rate comparison heatmap

This heatmap illustrates head-to-head performance between different AI models. Instead of showing raw win rates, it highlights relative dominance in pairwise comparisons. Red cells indicate the model listed in the row consistently outperforms the column model, while blue cells represent the opposite. This antisymmetric visualization clearly captures the dynamics of "who beats whom". This heatmap reveals clear dominance patterns: Gemini models frequently outperform others (rows dominated by red), while O3 and O3-Pro consistently underperform (rows dominated by blue, columns dominated by red). Claude-family models display competitive interactions among themselves but struggle notably against the leading Gemini models.
Break it mode

We are launching a program inviting researchers, postgraduate students, and subject matter experts (SMEs) to submit challenging, graduate-level questions designed to expose the current limitations of state-of-the-art (SOTA) AI models. Through Break-It Mode on EDU Arena, contributors can submit their questions, test them directly against leading AI models, and donate correct answers for expert review. Questions should demand deep domain reasoning, avoid ambiguity, and yield concise, verifiable answers that current models cannot solve—even after multiple attempts. Submissions go through a rigorous multi-stage evaluation: an initial AI-assisted assessment, followed by review by SMEs, and finally, academic vetting by a panel of professors. Accepted questions help push the boundaries of AI capabilities, and contributors whose questions are validated and stump the models may receive recognition and cash rewards. If you have expertise in a technical or academic field and want to challenge AI, click here to contribute.
Ready to explore how EDU Arena can support your lab’s evaluation goals?
Talk to an expert to define your use case, run targeted experiments, or co-develop model evaluation pipelines grounded in real learner impact.
Have the model—but not the right data?
Turing provides human-generated, proprietary datasets and world-class tuning support to get your LLM enterprise-ready.
