Understanding the Workflow of MLOps
•8 min read
- Languages, frameworks, tools, and trends

MLOps, an acronym for Machine Learning Operations, is one of the hottest buzzwords in the industry today. Sometimes called ModelOps, it is an engineering discipline that is geared towards unifying machine learning (ML) system development (dev) with machine learning system deployment (ops) to standardize and streamline the continual delivery of high-performing models in production.
This article will take you through the workflow behind MLOps and will discuss the steps that lie within the pipeline of the workflow. At the end of the article, you should be able to understand the generic workflow that lies at the backend of MLOps. And if you are a novice to machine learning, you will get to know the way a predictive model is constructed and utilized.
Why is MLOps used?
Today, data is being created quicker than you can imagine. It’s estimated that by 2025, as much as 463 exabytes of data will be generated around the world every day. This data needs to be housed and at the same time, machine learning operations need to be scaled. This is where MLOps comes in. Currently, the quantity of models deployed for the purpose is fairly small even though humans seek to automate tasks as much as possible. This crunch results in plenty of technical challenges. MLOps seeks to improve the process.
The lifecycle of MLOps includes the software development lifecycle, model creation, continuous integration and delivery, deployment, orchestration, governance, health and diagnostics monitoring, and business metrics analysis.
MLOps workflow
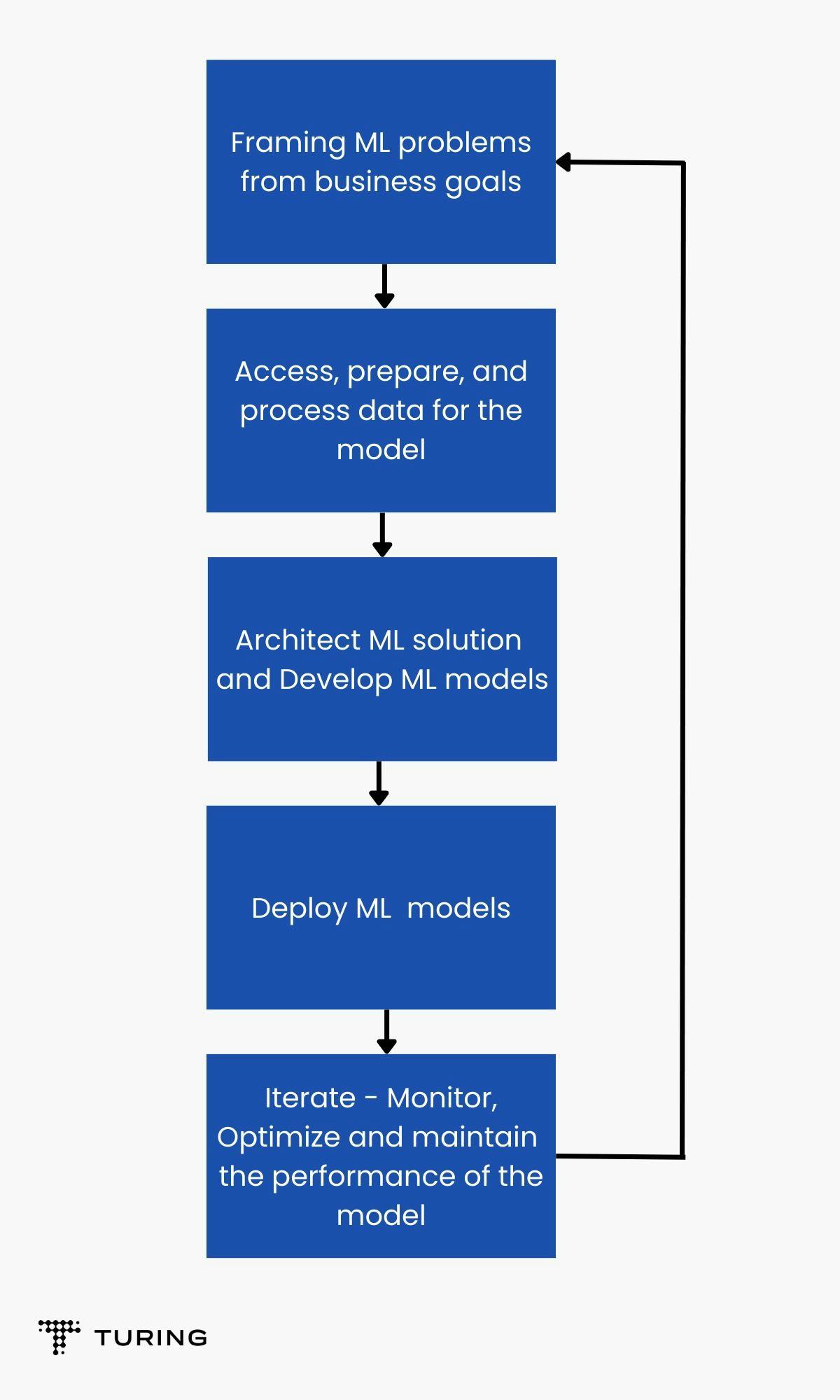
The term “workflow” means a series of activities that are necessary to complete a task. Similarly, in the domain of MLOps, workflow revolves around building solutions involving machine learning on an industrial scale.
MLOps workflow is often segregated into two basic layers, the upper layer (pipeline) and the lower layer (driver). The subparts of these layers are as follows:
Pipeline includes build, deploy, and monitor while driver includes data, code, artefacts, middleware, and infrastructure.
The pictorial representation below will help you understand it better.
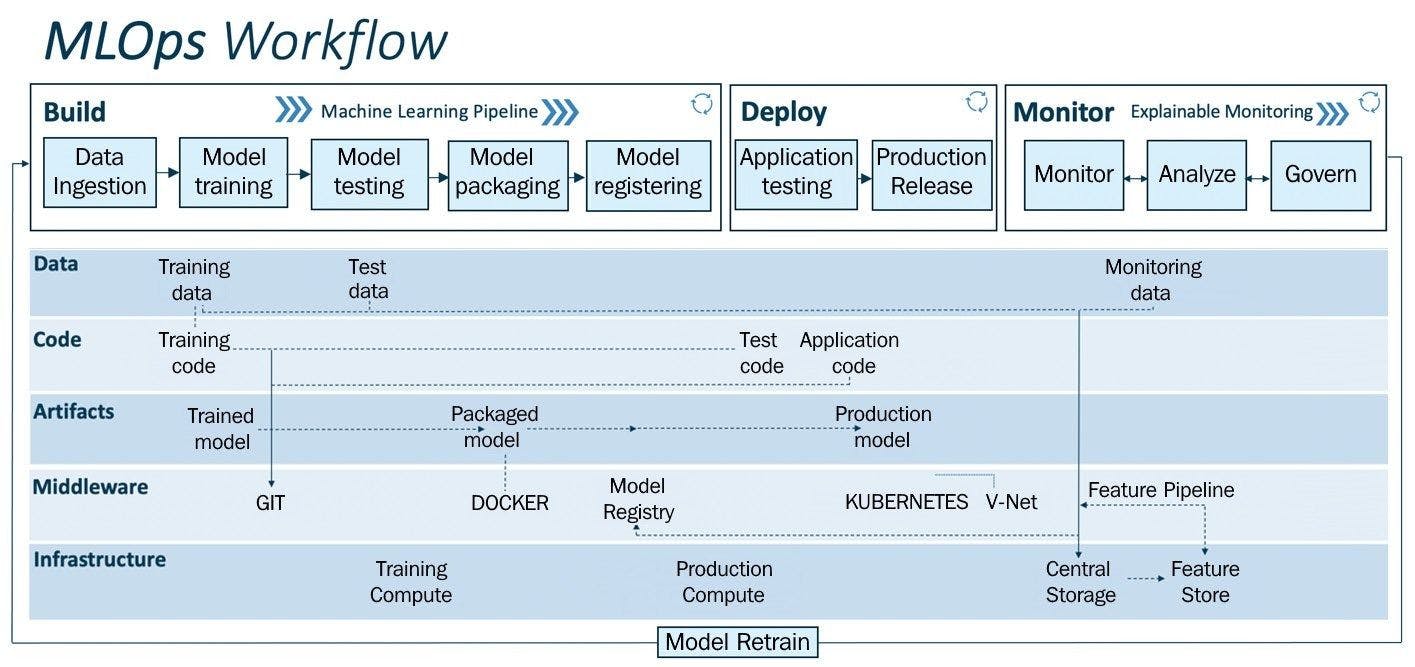
The pipeline is enabled by the drivers that lie below. It is with the assistance of this pipeline that you can easily prototype, test, and validate ML models.
Here is a more detailed explanation of each segment along with use case scenarios.
The pipeline
As stated, the pipeline is the upper layer. It is used in the deployment and monitoring of models.
Build module
This module is used to train and give a version to the ML models. The image below highlights the steps, with the first being data ingestion.
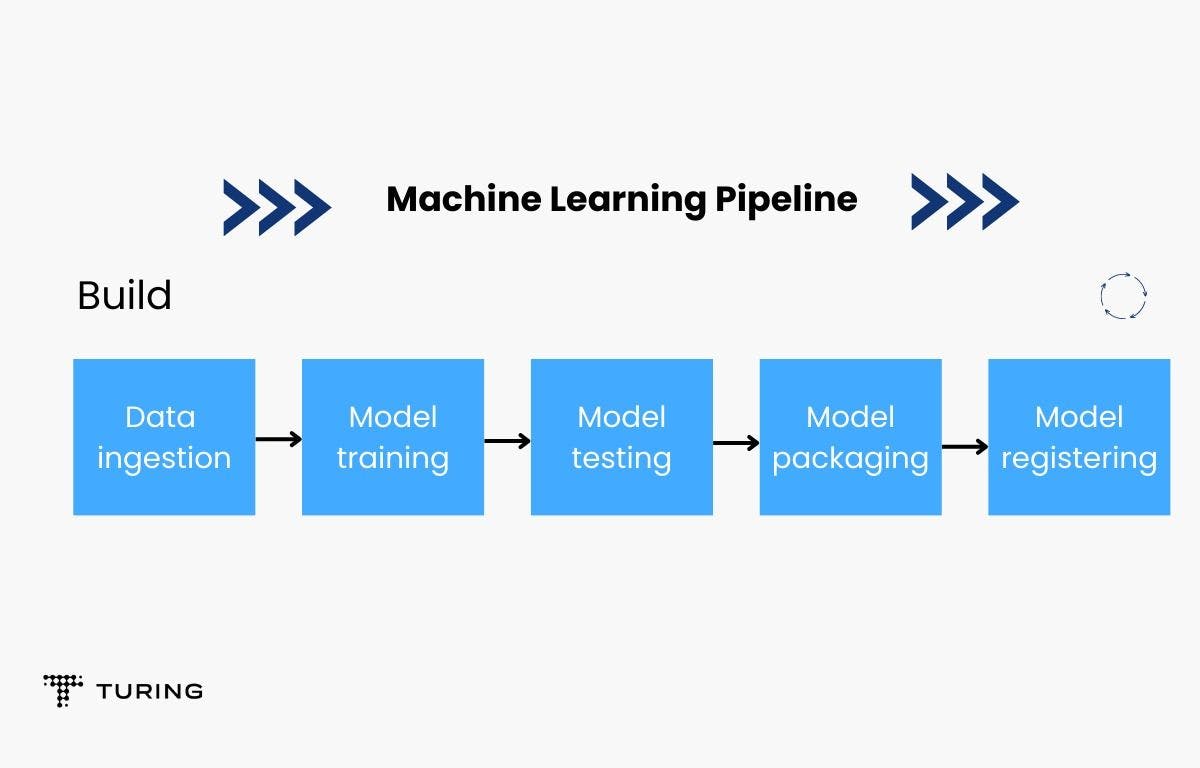
Use case: Consider the situation where an image processing service in a CCTV camera on a highway must be deployed.
Data ingestion (Data Ops)
The first stage in the MLOps life cycle encompasses all elements of data from data sources (such as data lake and data warehouse), from the creation of a data intake pipeline to data acquisition from diverse sources. A data lake could be a central repository that stores all kinds of structured and unstructured data on a very large scale.
The ingestion process is then followed by data verification and validation, which has validation logic. The pipeline connected to the information sources performs ETL operations – Extract, Transform, Load. Once the information is collected, it is split into training and testing sets.
Use case: In this case, the data will be numerous images of the various vehicles that cross the highway. The data will be segregated into training and testing datasets.
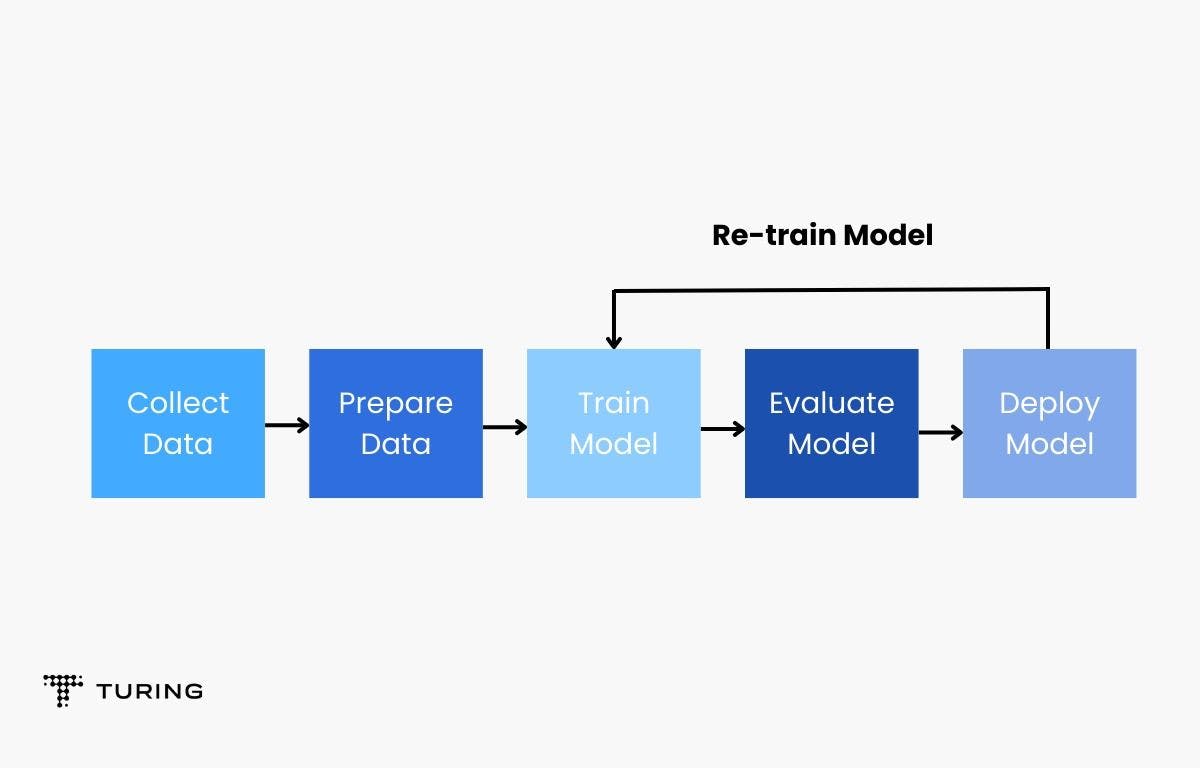
Model training
The next stage is to train the machine learning model to make predictive decisions in the latter part of the project. Modular codes will be run to perform all the traditional model training. Data preprocessing, cleaning, and feature engineering are included in this step. This process may require hyperparameter tuning to be performed, which can be done manually. Automatic solutions, eg. grid search is preferred.
A trained model is obtained after this step.
Use case: As the goal was to prepare an ML model that would categorize vehicles, a CNN (convolution neural network) is used for image classification. The result is a trained CNN model that is able to broadly classify different types of vehicles.
Trained model testing
Now that the model is trained and prepared, it’s performance will be evaluated on the premise of its predictive outcomes on the test data. The outputs will be within the kind of a metric score.
Use case: The test and training data have already been categorized. Now, the test data must be used against the model that was originally trained on the training data. The model’s performance can be evaluated using the precision scores. Once you are satisfied with the performance of the trained model, it is on to the next step.
Model packaging
The next step after evaluation is encapsulation using Docket so that it can be moved to the production stage. This will make the application independent of dependencies. Docker works by binding the entire application into runnable components along with the code itself, including the OS, libraries, and dependencies required to run the code.
Use case: The CNN model for the classification of vehicles in highways was encapsulated in a container in this step. It is now ready to undergo further processes.
Model registration
Once the model is containerized in the above step, it will be registered and stored in the model registry. A registered model is made up of one or more files that put the model together, represent it, and run it.
Now that the entire ML pipeline has been executed, the model is trained and ready to be deployed for the production environment.
Use case: The model is now registered. It is readily available for deployment into the vehicle classification using a security camera - project.
To summarize, the workflow that lies under MLOps mainly includes the upper layer called pipeline and the lower layer called the driver. The various stages that are involved in deploying a full-fledged ML app are data ingestion, which includes all the necessary action that is taken to modify the dataset before training the model to use it; model training, which includes the process where the ML model is trained using the training dataset; and model testing, where the trained model’s performance is tested using the test dataset and the performance scores are returned.
Deploy module
The deploy module empowers operationalizing the ML models created within the build module. Here, the model execution and behavior are tested in a production or production-like (test) environment to guarantee the vigor and adaptability of the model for production utilization.
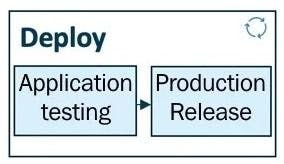
The above figure is a pictorial demonstration of the deploy pipeline. It consists mainly of two components: testing and release.
Testing
Testing is critical to validate the durability and performance of an ML model before deploying it for production. There’s an application testing step where all of the trained models are thoroughly evaluated for resilience and performance in a test environment, which is similar to a production environment. All the models are deployed in the test environment (pre-production) during the application testing phase.
In the test environment, the machine learning model is deployed as an API or streaming service to deployment targets such as Kubernetes clusters, container instances, scalable virtual machines or edge devices, depending on the need and use case. After this, predictions are made for the deployed model using test data. During this time, model inference is done in batches or periodically to check the model's robustness and performance.
The model’s performance is then reviewed and if it satisfies standards, it moves to the next stage - production.
Release
The models that were tested before are now deployed in the production stage to provide practical value.
Use case: The model is used as an API to a CCTV (installed by the highway) that is connected to a remote computer. The model performs an inference from the video feed from the CCTV to classify the vehicles on the highway in real-time.
Monitor module
The monitor and deploy modules go hand-in-hand. The monitor phase monitors and analyzes the ML application that has been deployed. The performance can be checked using predefined metrics. Think of it as comparing the results predicted by the model with the actual vehicle.
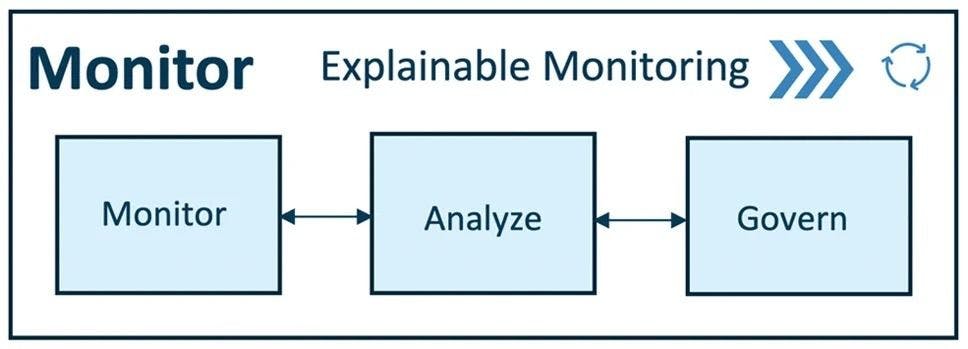
The model is also analyzed using a predefined explainability framework. It can be governed using actions on the basis of the model’s quality assurance control.
Monitoring
Data integrity, model drift, and application performance are all monitored by this module. Telemetry data may be used to track an application's performance. It shows how a production system's device performance has changed over time. The performance, health, and durability of the production system can be monitored using telemetry data from accelerometers, gyroscopes, humidity, magnetometers, pressure, and temperature.
Analyzing
In order to guarantee optimal performance and governance in connection to business choices or effects, it’s vital to monitor the performance of ML models deployed in production systems. Model explainability methodologies are applied in real-time to analyze the model’s essential characteristics such as fairness, trust, bias, transparency and error analysis, with the goal of increasing the model's commercial relevance.
Governing
The installed application is monitored and analyzed to ensure optimal performance for the company or the purpose of the ML system. Warnings and actions can be produced to regulate the system after monitoring and evaluating the production data.
When model performance deteriorates - low accuracy, high bias, and so on - below a predefined threshold, the product owner or quality assurance expert is notified. A trigger is set off to retrain and deploy an alternate model.
Compliance with local and international laws and standards is a vital part of governance. Here, model explainability and transparency are crucial. Model auditing and reporting are used to give production models with end-to-end traceability and explainability.
Use case: The model’s performance is monitored and analyzed where it was deployed, i.e., a CCTV connected to a computer. If the model gives a precision score of 40% in classifying vehicles, an alert is raised and the model is again trained for better robustness and accuracy in its predictions.
To summarize, the workflow of MLOps mainly includes the upper layer called pipeline and the lower layer called the driver. The various stages that are involved in deploying a full-fledged ML app are data ingestion, which includes all the necessary action that is taken to modify the dataset before training the model to use it; model training, which includes the process where the ML model is trained using the training dataset; model testing, where the trained model’s performance is tested using the test dataset and the performance scores are returned; and release, monitoring and analyzing - all of which are performed to ensure that the model returns accurate results.