
Tips on Data Manipulation and Wrangling Hacks
•7 min read
- Languages, frameworks, tools, and trends

Did you know? Data scientists spend 70-80% of their time cleaning and organizing data. Precious time that could be used to create new machine learning algorithms. But since structured data is only readable to machines, data must be translated and manipulated to make it clean and mapped to make it useful.
With increased data use and storage, manipulation and wrangling are vital to making data efficient. In this article, we’ll explore data wrangling and manipulation in detail, and provide useful tips and tricks.
Data manipulation
Data manipulation is the processing of data to make it user-friendly for people. The outcome of data manipulation is that the original data can be altered to generate a different set of data that will be stored in the same place.
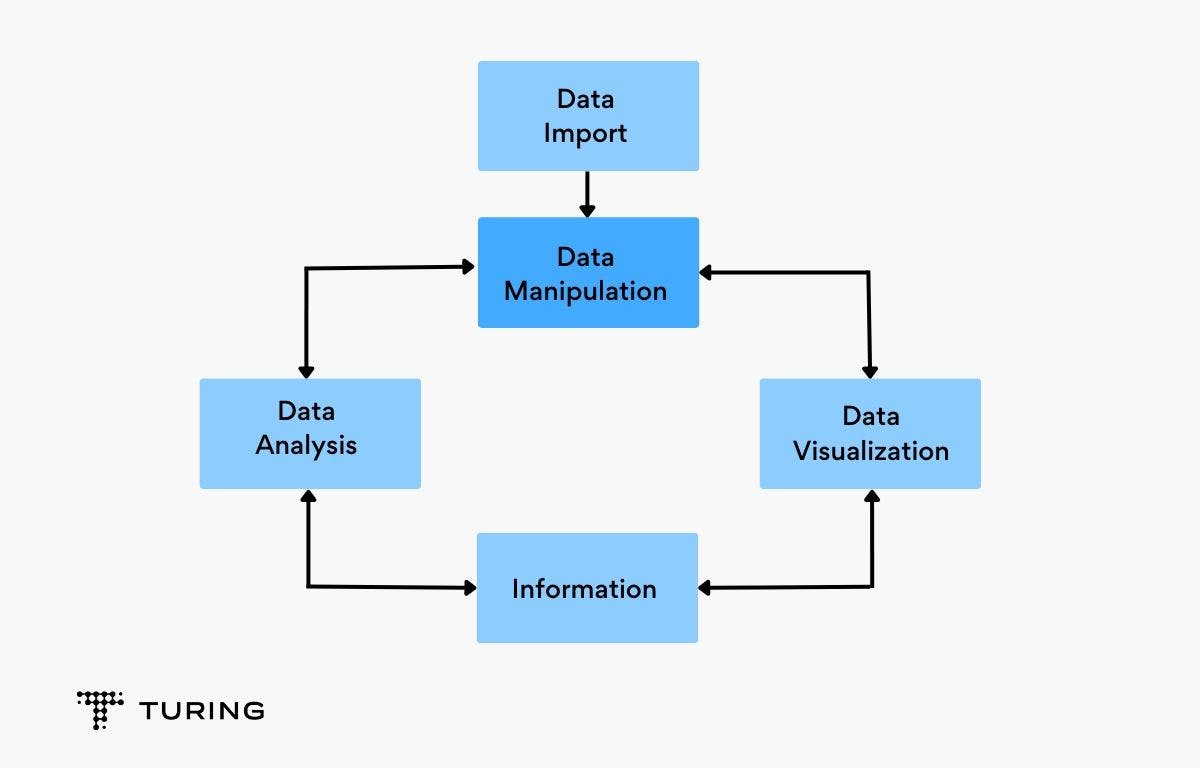
Frequent incorrect data can be changed. However, data manipulation and data change are not the same. The act of reorganizing data is known as data manipulation and the changes to the existing data values or the data itself is data modification.
The options and outcomes of data manipulation vary according to the dataset and intended use.
Data manipulation language (DML) is a programming language that adjusts data by inserting, deleting, and modifying commands in a database to make it clean and easy to map. SQL is a language that helps in communicating with the database. When used for data manipulation, the four functions below can occur:
- Select: The ‘select’ command allows you to pull a selection from the database that you want to use. You can tell the database what to SELECT and FROM which folder.
- Update: The ‘update’ feature lets you change data that is already in the database. You can ask the database to update certain information with the new data that you input. This can be a single record or multiple records.
- Insert: The ‘insert’ function lets you transfer data from one database to another.
- Delete: The ‘delete’ function lets you delete the existing data within a database. Note that you need to tell the database where to delete what files FROM.
Data manipulation tips
Here are some essential data manipulation tips for Excel to help you get the most out of your data:
- Functions and formulas: All the essential math functions can be used in data manipulation. You only have to write the functions into the cell and then add, multiply, subtract, or divide to find desired results.
- Filter and sort: With large datasets, being able to filter and sort information is a big help. You can do this with the Sort & Filter feature and analyze data bit by bit.
- Merge, create, combine, and separate columns: When organizing data, you can merge, create, combine, or separate columns according to your requirements.
- Autofill: To save time, you can run an equation across multiple cells by using drag and drop to auto-fill in all the cells.
- Remove duplicates: Duplicates in data can compromise quality. To avoid this, you can use the Remove Duplicates function and maintain the integrity of the data.
Data wrangling
Data wrangling is the process of cleaning and unifying complex datasets for easy access and analysis. This process includes converting and mapping data manually from one form to another. It also allows more convenient user consumption and organizing options.
The most common example of data wrangling is cleaning source data into a primary stage table and getting it transformed into data for a pipeline in a warehouse environment. This function takes place when preparing the data for a dashboard or other visualization options.
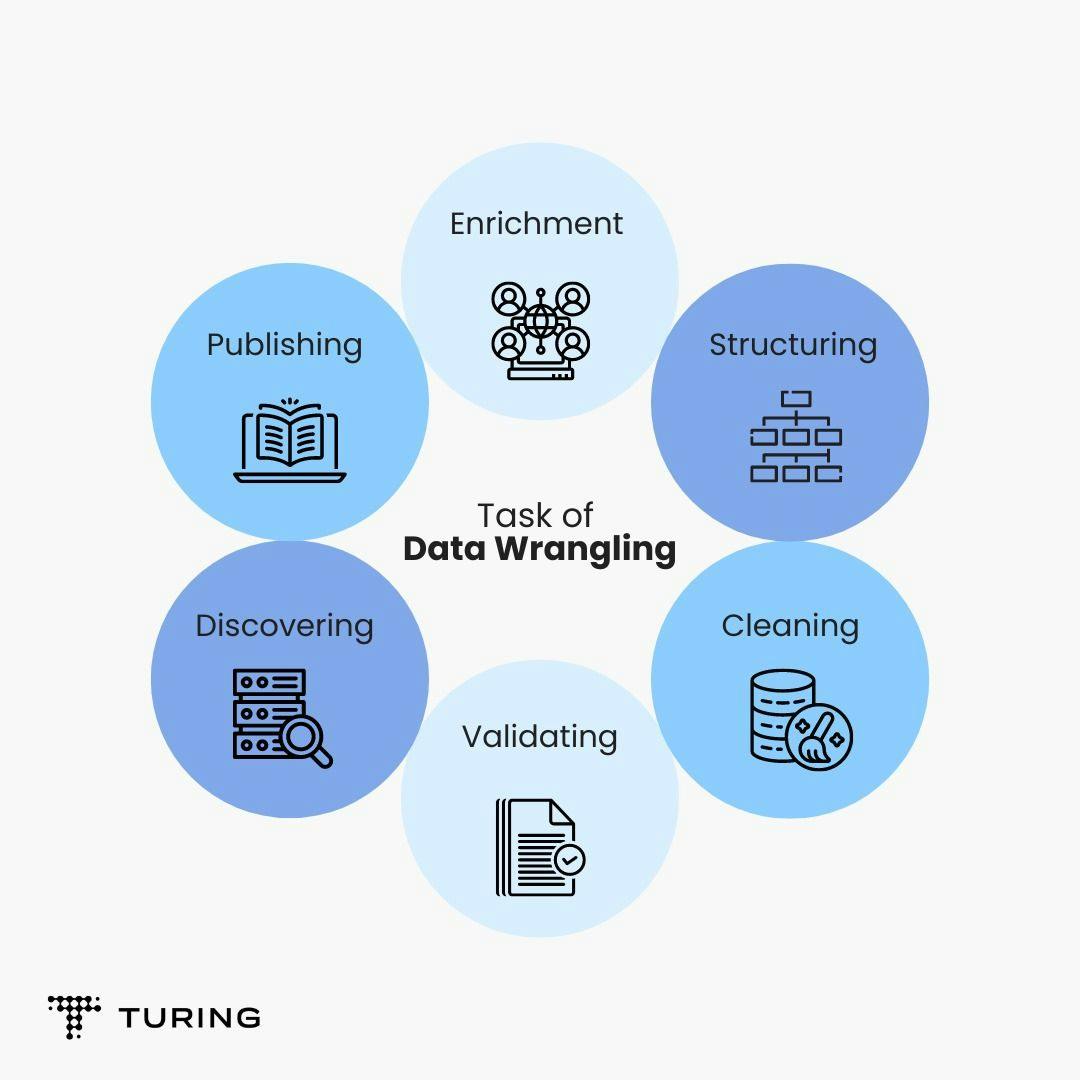
Data wrangling is performed to:
- Reveal a "deeper intelligence" by gathering data from multiple sources.
- Quickly provide accurate, actionable data to business analysts.
- Reduce the time spent collecting and organizing data.
- Enable data scientists to focus on analyzing data, rather than wrangling.
- Drive better decision-making.
Data wrangling tips
Here are some handy tips on data wrangling:
- Profile data for gaps: Data obtained from multiple sources often have gaps/inconsistencies that affect the overall quality and output. To address this, begin the data wrangling process by profiling the data.
- To drop or not drop - Nulls: Classify missing values into category-wise columns. It’s not enough to infer from a particular category; you should also make an educated guess about the right path for the value.
- Instituting daily conditional checks: One part of the pipeline loads the data into intermediate stage tables to produce quality checks. Some checks are automatic and others are custom. You can verify them based on the output of the process. The actual load of the data wrangling process can then be determined based on the verified value.
- Clean data: When you retain more granular data in an initial pass, you have enough information to perform analytics and start machine learning. It’s important to have product usage data at each level to roll out information about customers on an account level.
- Map roles in your pipeline: When you have different people working on the same data, cross-functional collaboration can be tricky - especially when each person works on different tools and has different skill sets. As you compose your strategy, find out who owns which roles in the pipeline to avoid confusion.
- Automate audit: When considering automating audit, you will have to work on monitoring projects for rights violations and track who invested in what product. Once data is cleaned, match what you know with the new information. You can then change the existing measures and try a different approach if needed.
- Let your model decide what to do with outliers: Outliers can have bad consequences for models, even if they are legitimate. When you incorporate a function that smoothens historical data in a dataset at one part of the workflow, you may not want to apply it to the pipeline.
- Scale-up: Use MapReduce if you aren’t able to scale your box for loading the data into the memory.
- Creating modules: Create different modules and share them with various people who are part of the project. If a problem occurs, you will only have to go through a single module to find it.
- Embrace the nuance of encoding: Issues with encoding occur in the latter stage of the processing pipeline when data is put into a working model. Once you have categorized values, it will help you find the different things you can do with them. You can create indicators for each category and ordinal value.
- Remember the Black Box: Understanding where a process has gone wrong is tough when you don’t have documentation. Avoid making things complex by processing secretly and having formatted documentation.
Data science hacks
Here are some top hacks for data science.
1. Select data type using Pandas
Separating continuous and categorized values for data analysis can be taxing as it consumes time and energy. The ‘If’ condition can take a lot of the grunt work out of the process.
2. Make use of Pandas Melt
The ‘Melt’ function in Pandas helps bring data frames into a clean and organized form. It provides functions to unpivot a data frame to a long format. With pd.melt(), you can use one or more columns as identifiers. You can also use ‘Unmelt the data’ with the help of the pivot() function.
3. Extract email with RegEx
Use the RegEx command to extract the email IDs of customers quickly and efficiently.
4. Read data with a glob
You will often be required to read data from different sources. Glob will help you find all the paths that match a specific pattern, according to the rules of the Unix shell script.
5. Resize images
When building image classification using data science, all the images must be of the same size. However, they may be of different shapes since data is usually from different sources. Convert them into the same shape and resize them for better usage.
6. Remove emojis from text
Preprocessing is the key to improving performance. Make sure you do it to remove unnecessary values like emojis.
7. Split work into modules
Making mistakes is part of the life cycle of data manipulation. However, you can split your tasks into different modules and work accordingly to minimize error and get more accurate results.
8. Apply Pandas operations in Parallel
The traditional Pandas library is slow, especially when data is large. Parallel is an efficient tool to parallelize Pandas operations as it helps save time.
9. Split data frames using the str.split() function
Use the str.split() function to apply string functions to the Pandas data frame. You can split the names into different data frames.
10. Use image augmentation
Although training deep learning models requires huge volumes of data, acquiring such massive data itself has challenges. Rather than spending all your time collecting data, use image augmentation methods.
Data comes in different forms and with so much of it being generated each day, cleaning and organizing it can greatly help organizations make better decisions. Data manipulation and wrangling can help achieve this goal by allowing decision-makers to easily access data and use it to their advantage.