Apache Spark: Why Is Resilient Distributed Dataset Immutable?
•6 min read
- Languages, frameworks, tools, and trends

Apache Spark is a parallel data processing framework and an open-source unified analytics that is used to process large-scale data. It has various applications in big data and machine learning. It is a data processing framework that deals with data workloads, uses in-memory caching, and optimizes query execution for fast effective analytic result. Apache Spark on local host distributes, MESOS or HDFS stores and distributes data as a resilient distributed dataset RDD.
It is an immutable and fault-tolerant distributed collection of elements that are well partitioned and different operations can be performed on them to form other RDDs.
Generally, immutable objects are easy to parallelize. It is because we can send parts of the objects to the involved parties with no worries of modification in the shared state. It comes out as a big deal since Spark is designed to work on several servers.
We got some insight into resilient distribution dataset in Apache Spark, now let’s address the elephant in the room.
Resilient distributed dataset is immutable! Why?
Immutability property rules out tons of potential problems because of there multiple threads is updated in one go. Apart from being immutable, it is also a deterministic function of their input. It means that you can recreate parts of RDD at any time. To simplify, caching, sharing and replication become a cakewalk with RDD. To list down some significant points and justify this property of resilient distributed dataset or RDD, here’s everything that will eliminate the second thoughts you are giving to it.
1. Design win
Resilient distributed dataset allows you to copy data rather than mutate it in a place. The trade-off is that it eliminates the developer's effort and time invested. It can easily live in memory of a disk, which makes it reasonable to move operations that hit the disk instead of using data in memory. Moreover, adding memory is much easier than adding I/O bandwidth.
2. Elevated security
The immutability of a resilient distributed dataset makes it safer to share data across various processes without any second thoughts. When shared, no other worker can make any modification from their end in RDD.
3. Consistency of data
RDD is the basic unit of parallelism and all the records are partitioned. All these partitions that are logically divided and immutable, help in achieving the consistency of data.
Benefits of the resilient distributed dataset
A resilient distributed dataset is packed with tons of benefits for the developers. They can effortlessly work on the data. Here’s a sneak peek into what’s in it for you.
1. Lazy evaluation
Apache Spark computes the transformations only when the action requires a result for the driver program. Apart from that, all transformations are lazy and do not compute results as and when stated in transformation statements. Moreover, they do keep a track of the transformation tasks with the help of the concept of directed acyclic graphs (DAG).
2. In memory computation
Memory computation is a technique to speed up the total processing time in Spark. The data is kept in RAM instead of filling up the disk drives which helps in reducing the cost of memory. It allows the analysis of large data and pattern detection with the help of methods like a cache () and persist (). Moreover keeping the data in the memory further enhances the performance by an order of magnitudes.
3. Persistence
The frequently used resilient distributed dataset can be stored in memory and retrieved directly from it without going to the disk. This speeds up the execution process and we can perform multiple operations on the same data in minimal time. It is carried out by storing the data explicitly in memory using cache () and persist () functions.
4. Location stickiness
Placement reference means any information about the location of RDD. RDDs are capable enough to define their placement reference in order to compute partitions. The DAGScheduler places the partition in a way that the task is closest to the data. This ultimately speeds up the computation.
5. Partitioning
The resilient distributed datasets are a collection of massive volumes of data items that cannot fit into a single node. It is due to this reason that they need to be partitioned across multiple nodes.
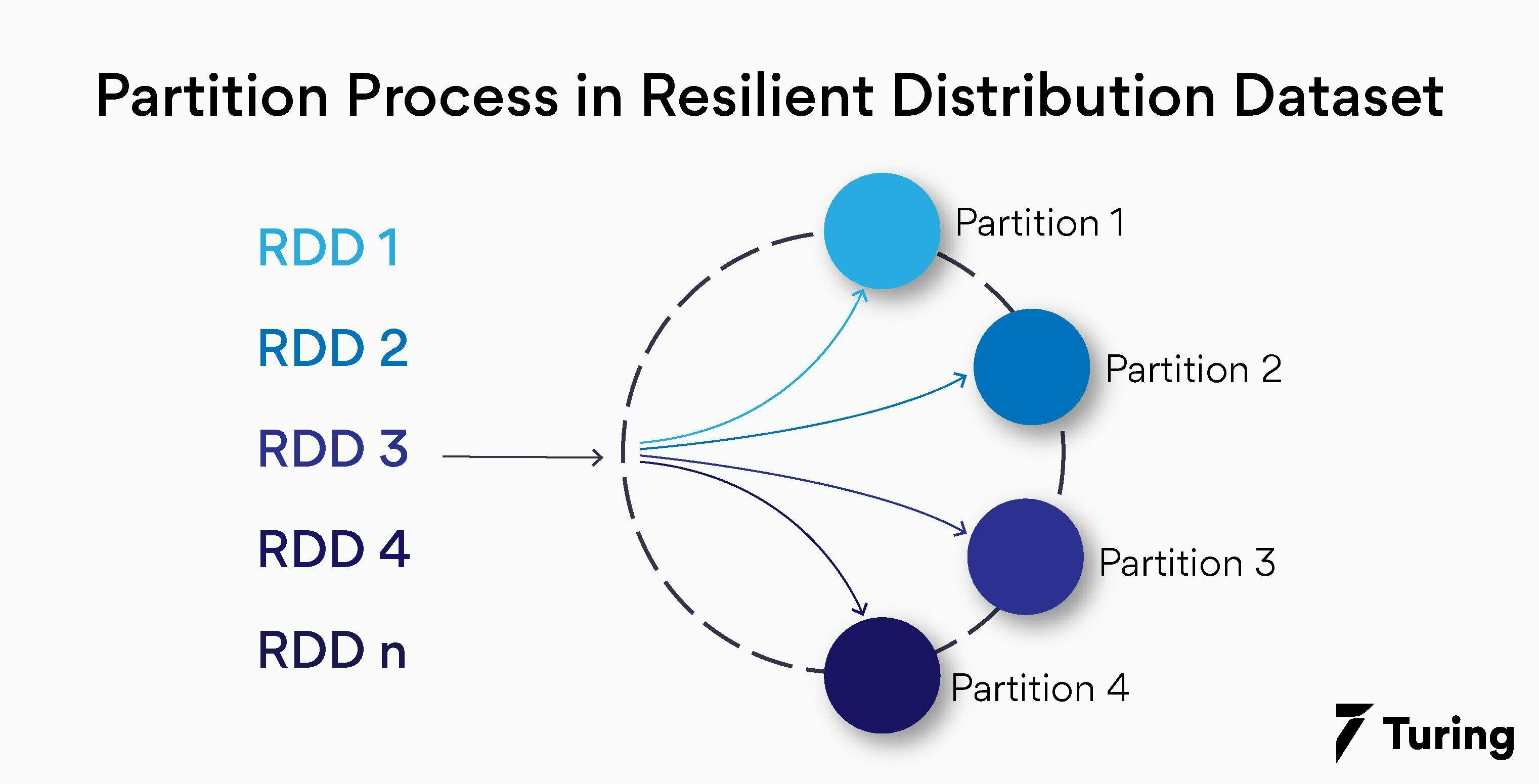
This partitioning of RDDs is automatically done via Spark and distributed across different nodes. Some of the points worth remembering for partitioning are listed below.
- The number of barriers should be chosen efficiently and are configurable in Spark.
- The partitions in Spark do not span to multiple machines.
- Every node contains one or more partitions in a Spark cluster.
- Parallelism can be increased in the system by elevating the number of executors on the cluster.
6. Coarse-grained operations
This means that operations are applied to all the elements present in the RDD. For instance, if a data set has a map, a group, and a filter then the operation will be performed on all the elements that are present in that partition.
7. Fault tolerance
RDDs can track any data lineage information to rebuild the lost data automatically on failure. If you wish to achieve fault tolerance for your generated RDD, replicate the data among various spark executors in worker nodes in the cluster.
When to use resilient distributed datasets?
There are some top reasons for which you should prioritise using RDD. Catch a glance at them below.
- When you want to have control over your dataset and want a low-level transformations.
- When you are dealing with unstructured data, for instance, streams of text or media streams.
- You are open to letting go of some optimization and performance benefits for structured and semi-structured data available with dataframes and datasets.
- If you don't care about imposing a schema while accessing or processing data attributes by name or column such as columnar format.
- If you wish to manipulate your data with functional programming domains rather than domain-specific expressions.
In every case mentioned above, RDD should be your first choice to hop over for your dataset.
The resilient distributed dataset is simple and a crucial concept in Apache Spark. It is a basic data structure that comes in handy for executing the MapReduce operations quickly and efficiently in Spark. Now that we have discussed the reasons behind RDD to be immutable, here’s a summary for a recap.
- You can enhance the computation process by caching RDD.
- Immutable data comes with a safe sharing advantage across different threads and processes.
- You can easily recreate the resilient distributed dataset.
So, move ahead and leverage these process to make the most your data.
FAQs
1. What is the significance of resilient distributed datasets in Spark?
Ans: The important functionality of in-memory process computation makes resilient distributed dataset a significant part of Apache Spark. Moreover, it enhances the performance, maintains consistency and induces fault tolerance property to the dataset.
2. What makes RDD in Spark maintain fault-tolerance?
Ans: It is with a lineage that RDD in Spark achieves its fault tolerance property. So, when you lose any partition of RDD because of failure, lineage helps in rebuilding that lost partition.
3. Why is RDD resilient in nature?
Ans: We call RDD resilient because of its property of fault tolerance and immutability. Moreover, it supports in memory processing computation and shares data 10 to 100 times faster than disk and network.