Random Forest Algorithm - How It Works & Why It’s So Effective
•6 min read
- Languages, frameworks, tools, and trends

Random Forest is a widely used classification and regression algorithm. As classification and regression are the most significant aspects of machine learning, we can say that the Random Forest Algorithm is one of the most important algorithms in machine learning.
The capacity to correctly classify observations is helpful for various business applications, such as predicting whether; a specific user would buy a product or a loan will default or not.
Classification algorithms in data science include logistic regression, support vector machines, naive Bayes classifiers, and decision trees. On the other hand, the random forest classifier is near the top of the classifier hierarchy.
This article will deep dive into how a Random forest classifier works with real-life examples and why the Random Forest is the most effective classification algorithm. Let's start with a basic definition of the Random Forest Algorithm.
What is Random Forest Algorithm?
Random Forest is a famous machine learning algorithm that uses supervised learning methods. You can apply it to both classification and regression problems. It is based on ensemble learning, which integrates multiple classifiers to solve a complex issue and increases the model's performance.
In layman's terms, Random Forest is a classifier that contains several decision trees on various subsets of a given dataset and takes the average to enhance the predicted accuracy of that dataset. Instead of relying on a single decision tree, the random forest collects the result from each tree and expects the final output based on the majority votes of predictions.
Now that you know what Random Forest Classifier is and why it is one of the most used classification algorithms in machine learning, let's dive into a real-life analogy to understand it better.
Real-life analogy
Robert needs help deciding where to spend his one-year vacation, so he asks those who know him best for advice. The first person he seeks out inquires about his former journeys' likes and dislikes. He'll give Robert some suggestions based on the replies.
It is an example of a decision tree algorithm. Robert's friend used Robert's replies to construct rules to help him decide what he should recommend.
Following that, Robert begins to seek more and more of his friends for advice, and they respond by asking him various questions from which they might deduce some recommendations. Finally, Robert selects the most recommended locations for him, as is the case with most random forest algorithms.

Working of Random Forest Algorithm
The Working of the Random Forest Algorithm is quite intuitive. It is implemented in two phases: The first is to combine N decision trees with building the random forest, and the second is to make predictions for each tree created in the first phase.
The following steps can be used to demonstrate the working process:
Step 1: Pick M data points at random from the training set.
Step 2: Create decision trees for your chosen data points (Subsets).
Step 3: Each decision tree will produce a result. Analyze it.
Step 4: For classification and regression, accordingly, the final output is based on Majority Voting or Averaging, accordingly.
The flowchart below will help you understand better:
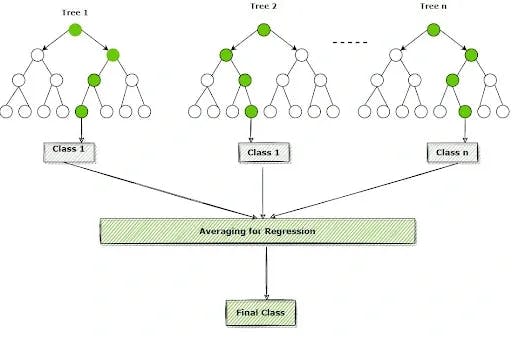
Confused? Don't worry; following real-life example will help you understand how the algorithm works:
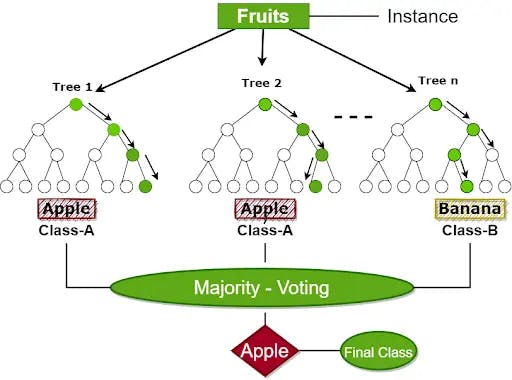
Example - Consider the following scenario: a dataset containing several fruits images. And the Random Forest Classifier is given this dataset. Each decision tree is given a subset of the dataset to work with. During the training phase, each decision tree generates a prediction result. The Random Forest classifier predicts the final decision based on most outcomes when a new data point appears.
Consider the following illustration:
How Random Forest Classifier is different from decision trees
Although a random forest is a collection of decision trees, its behavior differs significantly.
We will differentiate Random Forest from Decision Trees based on 3 Important parameters: Overfitting, Speed, and Process.
- Overfitting - Overfitting is not there as in Decision trees since random forests are formed from subsets of data, and the final output is based on average or majority rating.
- Speed - Random Forest Algorithm is relatively slower than Decision Trees.
- Process - Random forest collects data at random, forms a decision tree, and averages the results. It does not rely on any formulas as in Decision trees.
Essential qualities of Random Forest Algorithm
- Diversity- When creating an individual tree, not all qualities, variables, or features are taken into account; each tree is unique.
- Immune to dimensionality constraint- The feature space is minimized because each tree does not consider all features.
- Parallelization- Each tree is built from scratch using different data and properties. This means we can fully utilize the CPU to create random forests.
- Train-Test split- In a random forest, there is no need to separate the data for train and test because the decision tree will always miss 30% of the data.
- Stability- The result is stable because it is based on majority voting/averaging.
Applications cases of Random Forest Algorithm
The Random Forest Algorithm is most usually applied in the following four sectors:
- Banking: It is mainly used in the banking industry to identify loan risk.
- Medicine: To identify illness trends and risks.
- Land Use: Random Forest Classifier is also used to classify places with similar land-use patterns.
- Market Trends: You can determine market trends using this algorithm.
Advantages of Random Forest Algorithm
- Random Forest Algorithm eliminates overfitting as the result is based on a majority vote or average. Each decision tree formed is independent of the others, demonstrating the parallelization property
- Because the average answers from a vast number of trees are used, it is highly stable
- It preserves diversity by not considering all traits while creating each decision tree, albeit this is not true in all circumstances
- It is not affected by the dimensionality curse. The feature space is minimized because each tree does not consider all properties.
Although Random Forest is one of the most effective algorithms for classification and regression problems, there are some aspects you should be aware of before using it.
- When compared to decision trees, where decisions are determined by following the tree's route, the random forest is much more complex.
- Due to its complexities, training time is longer than for other models. Each decision tree must generate output for the supplied input data whenever it needs to make a prediction.
Summary
We can now conclude that Random Forest is one of the best high-performance strategies widely applied in numerous industries due to its effectiveness. It can handle data very effectively, whether it is binary, continuous, or categorical.
Random forest is difficult to beat in terms of performance. Of course, you can always discover a model that performs better, for example, neural networks. Still, they take longer to construct and can handle a wide range of data types, including binary, category, and numerical.
One of the finest aspects of the Random Forest is that it can accommodate missing values, making it an excellent solution for anyone who wants to create a model quickly and efficiently.
In short, we can conclude Random forest is a fast, simple, dynamic, and durable model with very few limitations.

Author
Mohit Chaudhary
Mohit is an Engineer turned tech blogger. He loves to dive deep into the tech space and has been doing it for the last 3 years now. He calls himself a cinephile and plays badminton in his free time.