How to Apply Hadoop in Data Science
•5 min read
- Languages, frameworks, tools, and trends
- Skills, interviews, and jobs

Apache Hadoop is an open-source framework that assists computer networks in solving problems that demand massive computational power and datasets. It is a highly scalable software system developed in a way that accommodates computing processes from a single server to 10,000 machines.
Although Hadoop is coded using Java, it can be used in data science with various other languages like Python, C++, Ruby, Perl, etc.
Origin of Hadoop
The history of Hadoop dates back to 2008 when Yahoo released it as an open-source project. At present, the non-profit Apache Software Foundation (ASF) manages Hadoop, an official community for software programmers and contributors.
Doug Cutting and Mike Cafarella are the brains behind Nutch, an open-source search engine upon which Hadoop is built. They initially wanted to discover a way to return faster web search results using distributed data and calculations over numerous computers so that multitasking could become a reality.
How is Hadoop useful in Data Science?
Scalability of big data
Data is expanding its demand for storage, maintenance, analysis, and interpretation. Database technology is implemented everywhere and is not limited to internet-based products. It’s in finance, banking, transportation, and other conventional industries. Analyzing and deriving sense out of all this information is now a separate industry called data science.
Out of the many frameworks available, Hadoop’s ecosystem is admired for its reliability and scalability. With the massive generation of data, it becomes extremely challenging for database systems to organize growing information.
Hadoop offers a scalable solution and a flawless architecture that enables the storage of massive information without any loss. It accommodates two types of scalability: vertical and horizontal.
Vertical scalability
Vertical scaling comprises combining more resources (such as CPUs) into a single node. It upgrades the hardware potential of the Hadoop system using the vertical method. Another upgrade can be done with the addition of RAM and CPU to improve its strength and durability.
Horizontal scalability
Horizontal scaling weighs on the expansion of the distributed software system by adjoining new nodes or systems. If required, more machines can be added without straining the system, unlike in vertical implementation of capacity. This eradicates downtime and ensures optimum utilization as one scales out. It also supports several machines functioning at the same time.
Computing capacity
Hadoop’s distributed computation enables it to filter and process a huge quantity of data. Using multiple nodes enhances processing efficiency.
Fault tolerance
Hadoop maintains numerous copies of all databases by default. If one node malfunctions during the process, the task is forwarded to other nodes. Distributed computing also never discontinues.
Flexibility
Hadoop intakes information without the necessity of preprocessing. It organizes data - including unstructured data like text, photos, and video - and determines what to do with it afterward.
Cost reduction
Data is stored on commodity hardware. The framework, being open-source, is free.
Commercial applications of Hadoop
- eBay uses Hadoop to generate value from data for search optimization.
- Facebook relies on Hadoop to store copies of internal logs and dimension data sources for reporting, analytics, and machine learning.
- LinkedIn's ‘People You May Know’ feature is operated on Hadoop.
- Opower uses Hadoop to help customers with recommendations, offers, and saving money on their energy costs.
- Orbitz analyzes every activity of visitors’ browsing sessions using Hadoop to maximize hotel search ranking.
- Hadoop is a solution for musical content on Spotify as well as for data collection, reporting, and analysis.
- Twitter’s tweets and log files are stored and processed in Hadoop.
Hadoop: A data scientist’s ally
Hadoop’s primary job is the storage of big data, which is a combination of numerous types of data including structured and unstructured data.
Image source: https://data-flair.training/blogs/big-data-vs-data-science/
Using Hadoop, data scientists can monitor massive amounts of data without hassle. It can also contribute towards career growth by giving data scientists skilled in Hadoop a competitive advantage.
Here are some other applications:
Rapid data exploration
Data scientists spend up to 80% of their time preparing data. With Hadoop’s tools for data exploration, they can avail assistance in identifying complexities in data, which cannot otherwise be perceived directly.
Hadoop also helps store data and excels in dealing with an abundance of it without requiring any prior interpretation.
Data filtration
The only time data scientists utilize complete datasets is when developing a machine learning model or a classifier - and that too, in exceptional instances. They otherwise need to filter data based on marketing and research requirements.
Data scientists may want to examine a record as a whole, but only a few of them are likely to be effective. Data scientists also detect corrupt or faulty data during filtration. A command over Hadoop ensures that they can quickly filter a dataset and solve industry-specific problems.
Data sampling
It’s not possible to build a model straight out of the first 1,000 items from a database. Data is written in a typical format, and the same types of records are grouped. Hence, data scientists first need a complete picture of what the data is about. This is possible with sampling, and Hadoop’s simple interface cuts down the time needed to perform it.
Sampling gives data scientists an idea of the techniques and analysis methods to use for modeling data. The term ‘Sample’ in Hadoop Pig is a useful tool for curbing the number of records.
HDFS is the primary data storage system in Hadoop applications. It is a distributed file system that uses architecture such as NameNode and DataNode to enable high-performance data access across Hadoop clusters. HDFS is an eminent component of the Hadoop ecosystem. It acts as a safe and secure platform for handling large datasets while supporting big data analytics applications.
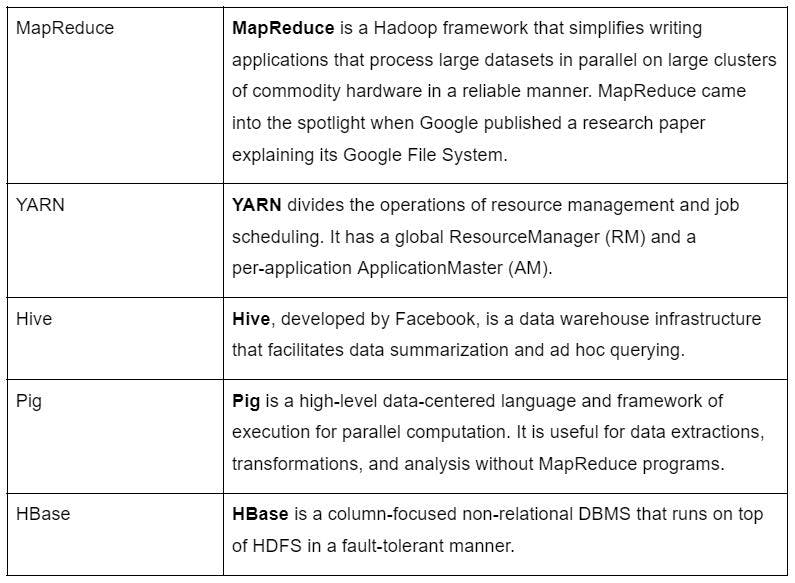
Anatomy of Hadoop
Here are some important components of Hadoop:
It's evident that 80-90% of data is in an unstructured form and is steadily booming. Hadoop plays a vital role in positioning big data tasks in the appropriate systems and reinventing data management structure. Scalable and cost-effective, its systematic architecture reinforces industries to process and manage big data.