
Data Mesh and It’s Distributed Data Architecture: A Complete Guide
•5 min read
- Languages, frameworks, tools, and trends

Data generation has grown exponentially in the last few years. You can think of it in terms of the three V’s: data volume, variety, and velocity. Alongside this growth in data, there is a sharp growth in business use, performance, and expectations to get more valuable insights from the data collected.
Data analysis has been done pretty much the same way for decades all over the world. In this new age where many businesses need real-time analysis, certain issues and cracks can be seen in the old paradigm. Transforming a business requires new and elegant solutions, and with ITs current data challenges, it is necessary to create a new, simpler, and faster-operating model than the existing data lakes and warehouses. This is where data mesh comes in.
Data Mesh 101
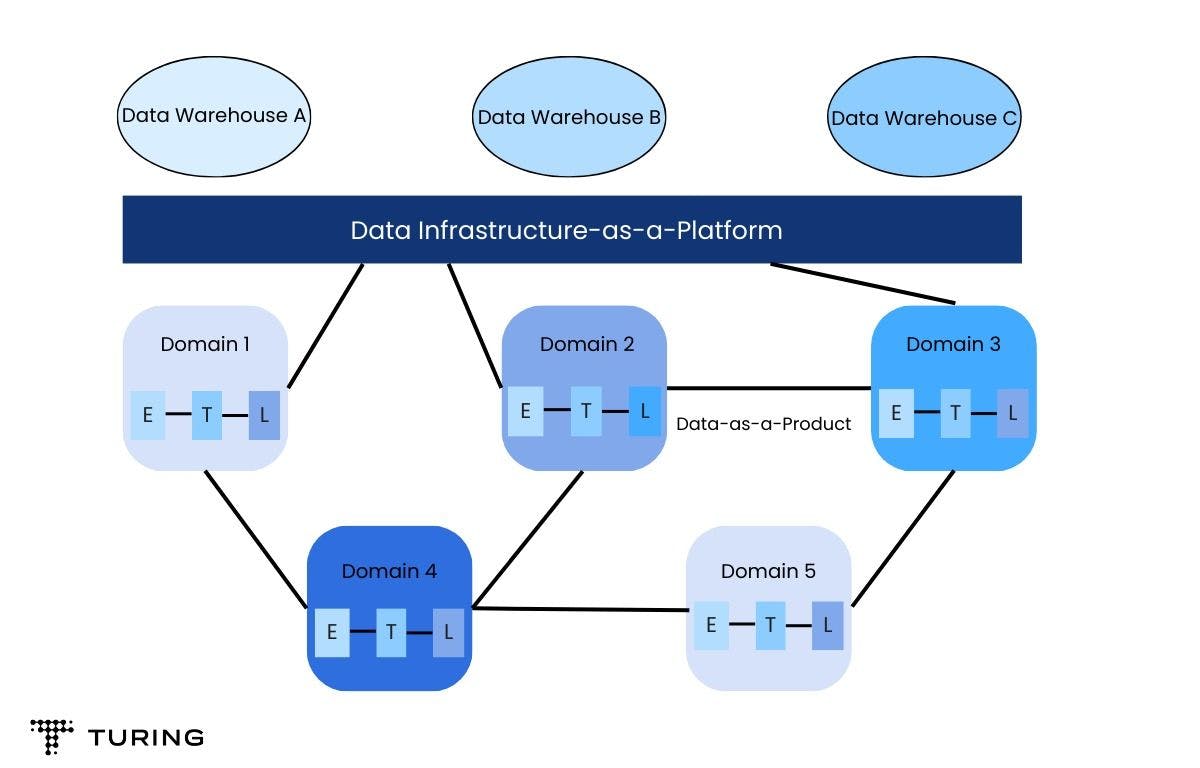
Historically, data was stored to draw insights and patterns from a firm’s previous endeavors. Data mesh is an approach to analytics that respects the fact that the world has moved beyond just building reports in the morning to submit the previous work day’s results to the bosses. These days, the functioning of all the parts and people at every level of a business is impacted by real-time analysis.
The existing paradigms like data lake can be thought of as a monolithic data architecture where every type of data generated by the business is dumped. Data mesh breaks this single structure into multiple domains, which are individually hosted and maintained by dedicated teams for each domain.
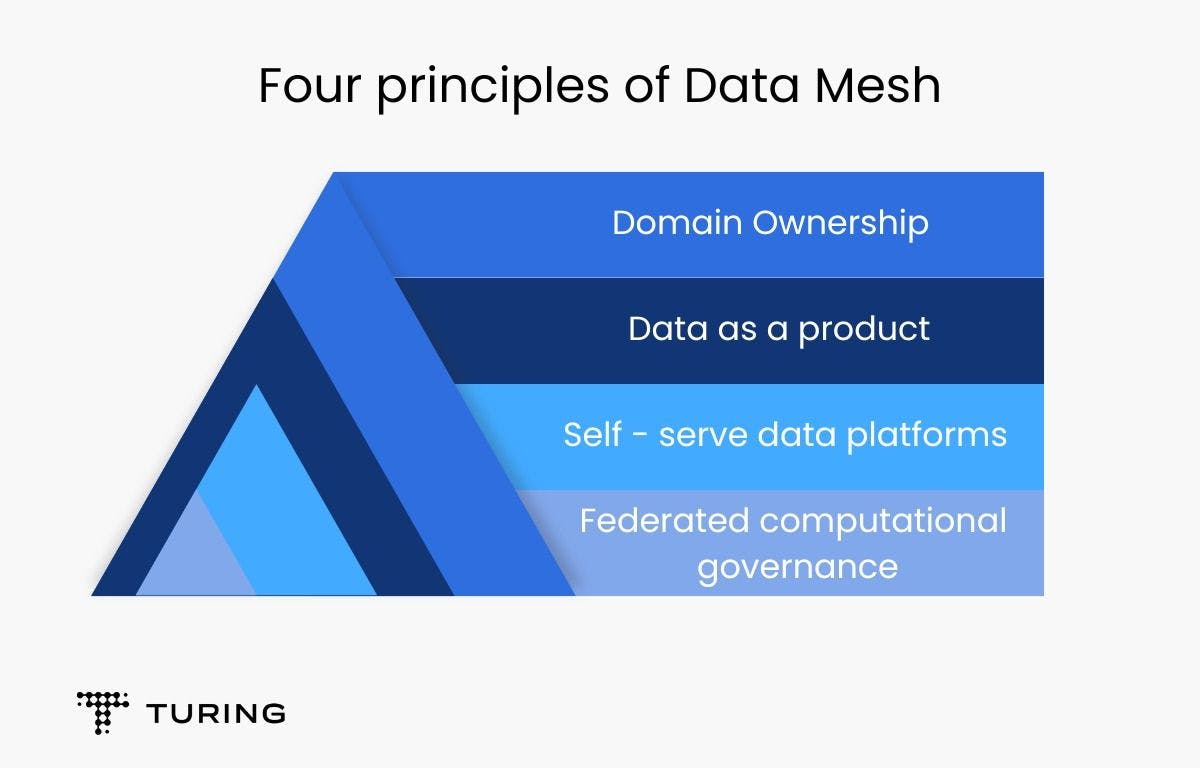
Data mesh comprises four principles:
- Domain ownership
- Data as a product
- Self-serve data platform
- Federated computational governance
Domain ownership
At its core, the objective of this principle is to ensure that the data is owned by those who understand it the best. Now the question arises, how does anyone decide ownership for a particular set of data?
As described by Zhamak Dehghani in her 2020 writeup Data Mesh Principles and Logical Architecture: Data mesh follows the seams of organizational units as the axis of decomposition. The enterprises today are decomposed based on their domain expertise. For example, a typical service-based company might divide its workforce into Order department, Shipping department, Inventory, Billing, Customer care, etc.
Each of these departments would have their own exclusive “data teams” that are well-versed in domain knowledge to maintain the generated data to the company’s standards. Nomenclature as such “data teams” from other domains gets high-quality structured data on demand.
Data as a product
Your domain’s shared data should be treated as first-class products and other “data teams” as your internal customers.
Here is another excerpt from the same article by Zhamak Dehghani: Data as a product principle is designed to address the data quality and age-old data silos problem. Or as Gartner calls it, dark data: The information assets organizations collect, process and store during regular business activities, but generally fail to use for other purposes.
This leads to another role of domain data product owner within these “data teams” whose objective is to provide this data in a clean, standardized, and proper way as a product to the other domain teams. This way of thinking is very important as it prevents data chauvinism since the decentralization and local autonomy over domains offered by data mesh can lead to the creation of more data silos and serious data quality problems.
Self-serve data platforms
How do you access data in a reasonable amount of time? This is a key question that companies mull over at the beginning of projects. Starting from scratch with a new project, you typically want the historical data in your database, and then keep it up to date with real-time events.
What usually happens is that you receive a CSV file, but that leads to another problem. The new event streams and snapshot files might have different schemas, or different names for the fields, which makes it hard to match up the schema in time. And seldom is this process automated.
This is exactly the problem this principle solves. A fair bit of complex, centralized, and autonomous infrastructure has to be installed that provides historical as well as real-time data on demand everywhere, in any database in the enterprise.
Federated computational governance
This principle is largely an organizational concern. To ensure that all these domain-specific autonomous data teams can work together, global standards for nomenclature have to be specified.
Here’s another excerpt from Zhamak’s paper where she concretely describes what federated computational governance is: To get value in forms of higher-order datasets, insights, or machine intelligence there is a need for these independent data products to interoperate; to be able to correlate them, create unions, find intersections, or perform other graphs or set operations on them at scale. For any of these operations to be possible, a data mesh implementation requires a governance model that embraces decentralization and domain self-sovereignty, interoperability through global standardization, dynamic topology, and most importantly automated execution of decisions by the platform. I call this a federated computational governance.
A decision making model led by the federation of domain data product owners and data platform product owners, with autonomy and domain-local decision making power, while creating and adhering to a set of global rules - rules applied to all data products and their interfaces - to ensure a healthy and interoperable ecosystem.
Data mesh aims to simplify the way data products are processed and exchanged across an organization with the least effort and time and has quite a few advantages over the traditional centralized approach like scalability, faster data delivery, autonomy, standardized data, etc.
However, despite the promising outlook, a lot of work by a lot of people still has to be put in. Data mesh can be still considered in its nascent stages and has quite a ways to go before it becomes the next major data architecture paradigm.