CAP Theorem for System Design - Explained
•8 min read
- Languages, frameworks, tools, and trends

The CAP theorem stands for Consistency, Availability, and Partitions and expresses that a distributed system generally produces two of three properties simultaneously and characterizes the compromise between consistency and availability when a partition exists.
This theorem is also known as Brewer’s theorem since it was first conveyed by Eric Brewer, a computer science professor from U.C. Berkley.
So, exactly what is CAP Theorem?
This theorem suggests that a distributed system (collection of computers) should ideally share a single state while performing simultaneously. The shared system should also manage its data across multiple nodes using virtual machines or physical systems.
To understand how to use the CAP theorem for system design, let’s understand what is CAP theorem, how and when to implement different databases, and the differences between NoSQL and SQL databases.
Understanding consistency, availability, and partitions
Let’s start by taking a look at a visual representation of a two-node distributed system.

Here we can see that the nodes are connected together and we assume the user's system is writing data on one node while reading data from the other. This leads to the obvious question.
What is a CAP system?
Let’s use an example to understand CAP theorem system design.
A video editor is using his system to read the raw footage from one node or database and as he finishes various edits, he writes the completed footage to another node.
In such a scenario, there are three possible properties that CAP allows you to work with:
- Consistency & Availability (CA database)
- Consistency & Partitional Tolerance (CP Database)
- Availability & Partitional Tolerance (AP Database)
We’ll look at these in detail a little further on.
Before that, let’s understand each of these properties a little more in detail which will help you understand why is CAP theorem needed for certain applications.
Consistency
Consistency refers to the performance of reading and writes operations for all users connected via a distributed system irrespective of which a user accesses node.
Ideally, the read operation should return the exact data for all users, while the write operations should replicate any new data across all nodes.
For example, let’s assume you placed an order online but made some changes to it. Later, when you get in touch with them regarding a cancellation, even if a new representative connects with you, they will be aware of any changes made to that order.
This is because as mentioned above the written data from the changes were consistent across all connected nodes, and when the new representative tried to read your data, it returned the last written data.
Availability
Availability refers to the persistence of data to flow through at all times regardless of failed nodes. The entire distributed network should remain functional even if several nodes malfunction.
User systems are generally unaffected by the data they can retrieve in a distributed network with availability.
Using the same example from above, if you have placed an order online and made changes to it, even if the customer care network has multiple server failures, the availability of information will ensure that representatives can still retrieve your data.
However, there is no guarantee that the information retrieved will be the last written operation since the system favors availability over consistency in this scenario.
Partitions
A partition tolerance in CAP theorem refers to an interrupted communication between nodes of a distributed system. The distributed system must have partitional tolerance to overcome malfunctioning nodes and continue read/write operations.
This is the main reason why connected systems can only utilize two of the three database properties (CA, CP, AP) since partitional tolerance is almost always required to maintain database integrity.
Depending on the type of node failure and the information required by the user's systems, the network can be configured to either provide consistency of data or availability for all users.
Now, let’s look at how these database properties are utilized by the user's system.
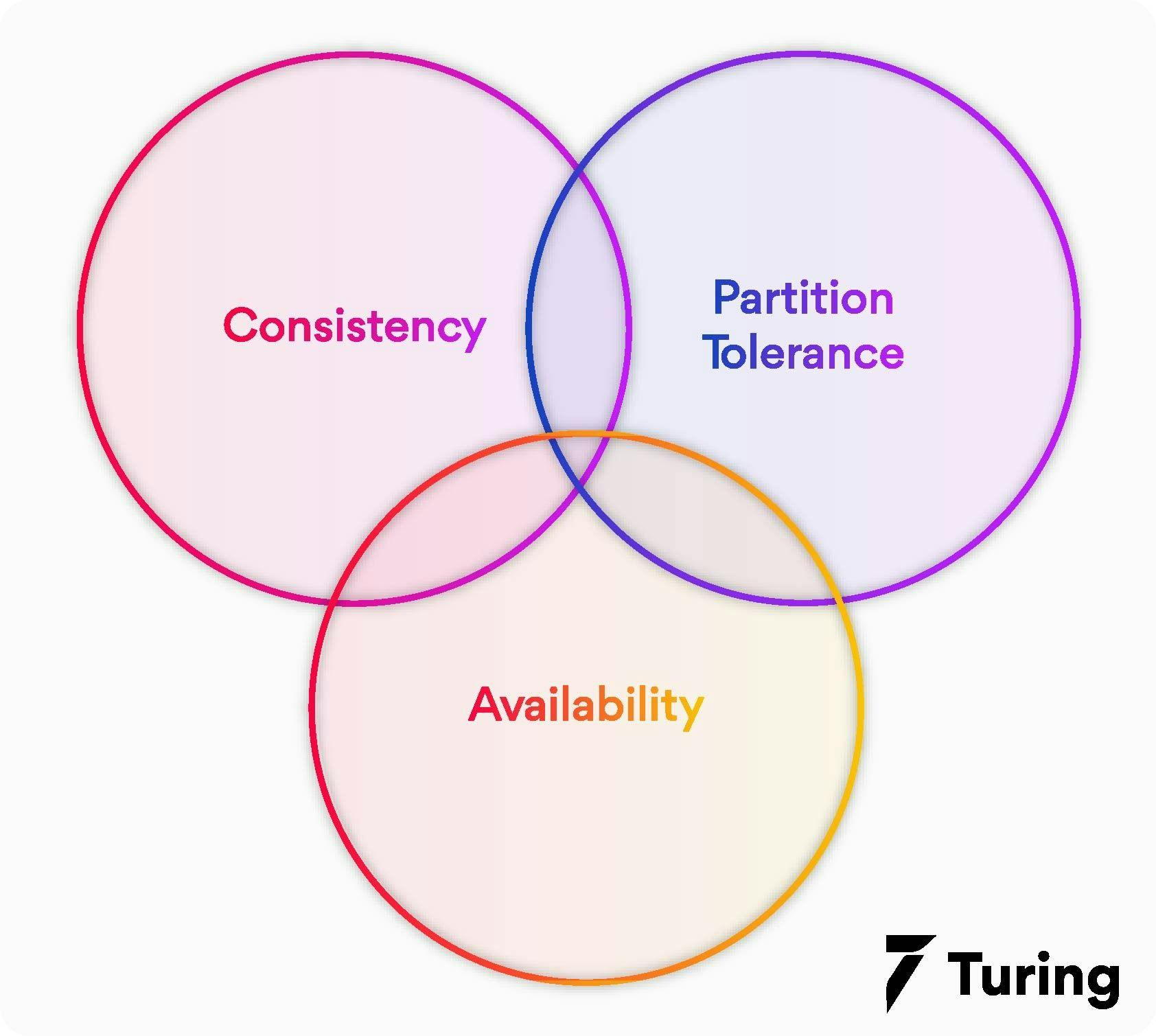
This is a simplified visual idea of how the database is accessed. Two of these properties in conjunction make up the CAP model that various industries implement within their pipeline.
Consistency & availability (CA database)
These databases, as the name suggests utilize consistency and availability of data across all connected nodes. However, this means the system does not have partitional tolerance which means that a node failure can lead to unavailability of data.
This makes CA databases pretty much redundant since node failures are bound to occur in any type of connected system.
In some cases, databases do allow CA, most notably in SQL databases such as PostgreSQL which we will discuss as we move forward.
Now let’s look at the properties of CAP theorem and how they work together in various scenarios.
Consistency & partitional tolerance (CP Database)
These databases prioritize consistency and partitional tolerance between all connected nodes. This means that if a partition or node failure occurs, these particular nodes, also known as inconsistent nodes, will be turned off.
This is done to maintain the consistency of written data across all working nodes. Data is generally replicated across the primary nodes so if they fail, the secondary nodes step in. However, since availability isn’t prioritized, write operations are restricted till the primary node is rectified.
CP databases are NoSQL databases and asynchronously update themselves based on the primary node. MongoDB is an example of a NoSQL database management system (DBMS).
Availability & partitional tolerance (AP Database)
AP databases prioritize availability during a partition or node failure. This means that if a node fails, it is still available for use. However, the data from these failed nodes will not be the most recent version.
Apache Cassandra, similar to MongoDB is a NoSQL database, but since it’s an AP database, it does not have a primary node and keeps all nodes available.
Once the partition is rectified, it allows the user to sync their data to maintain overall consistency.
Understanding and defining databases
Before we jump into how each type of database is managed by different DBMS, let’s first understand the general idea behind them as it can help while defining your own database.
Most databases are split into two categories, namely ACID and BASE. Knowing which category your data falls into helps a lot with defining your database.
ACID and BASE
ACID stands for:
- Atomicity - this refers to the transaction criterion of a DBMS.
- Consistency - it refers to the consistency of the database across all connected nodes.
- Isolation - refers to the isolation of various user systems to prevent additional copies of data.
- Durability - refers to the capability of the DBMS to create backups in the event of any malfunction.
BASE stands for Basically Available, Soft-State, Eventually Consistent, which is exclusive to non-relational databases such as AP databases. These databases aren’t like ACID, as partitions cause inconsistency in data across the nodes.
However, they do reach consistency across the board eventually. As discussed earlier, this is a trade-off to maintain the availability of data to the end user.
Let’s look at SQL and NoSQL. These are the programming languages used to interact with relational and non-relational databases respectively.
SQL and NoSQL
SQL refers to Structured Query Language and is used to interact with relational databases. They perform what developers refer to as Create, Read, Update, and Delete. It is called CRUD for short.
Since SQL requires all data to follow a particular schema or parameters, it can seem restrictive, but there are definitely plenty of use cases for this.
This does, however, require extensive planning before rolling out the database.
NoSQL refers to Not Only Structured Query Language and is used primarily to interact and manipulate data in non-relational databases.
Unlike SQL databases, NoSQL databases are not tied to predetermined schemas as their architecture allows for flexibility.
With this information, let’s understand the importance of each database type.
CA databases with PostgreSQL
PostgreSQL is a DBMS that, as the name suggests, uses structured query language to interact with a database.
It follows the ACID principles and can be used for services such as banks where the consistency and availability of data are crucial.
PostgreSQL also supports foreign keys that can allow multiple databases to communicate with each other.
However, this requires extensive planning since data is constructed in tables that are predetermined.
CP databases with MongoDB
MongoDB is a NoSQL DBMS that utilizes documents for storing data. Because it is a schema-less architecture, unlike SQL databases, it doesn’t require a lot of planning to execute.
It can also be changed and updated as required. This is one reason why CAP theorem in big data is extremely important.
MongoDB as mentioned stores data in documents, and it utilizes BSON files to handle queries. Users can interact with the BSON files using the converted JSON files to make any changes to the database.
While MongoDB is primarily BASE oriented, in recent years it has been adopted to some of the standardizations of ACID.
This doesn’t mean that it conforms entirely to ACID, as there are still gaps that need to be fixed, but depending on the application of the database, this can prove useful.
AP databases with Cassandra
Cassandra is used to managing AP databases, which sacrifice consistency at the cost of availability.
This system is peer-to-peer and unlike consistent databases, it does not have primary and secondary nodes which can result in multiple node failures.
While Cassandra does create replicas on multiple nodes in case of failure, it does so based on the replication factor set by the user during the initial setup of the distributed system.
It means that if the replication factor is 2, then the nodes will copy data clockwise to each other on and n+1 basis, where n is the original node.
This property makes it reach the eventual consistency of data, but the most recent data won’t be available immediately.
Wrapping Up
We can now see why the CAP theorem plays a big part in the data management of large and small businesses alike. These systems when planned out properly can alleviate issues such as human error to keep data relevant and reduce redundancy.
Furthermore, the choice of database structures and management systems allow users to carefully choose the right one based on their requirements. It also understands the data that you are working on and the scalability required.

Author
Arvind Rueben
Arvind is an avid tech geek and loves to play video games and make music. He has written for blogs ranging from programming languages and tech to wine investments and travel blogs. He is also an ardent animal lover and can't resist petting every animal he sees.