

Turing’s Talent Cloud connects businesses with top-tier software developers from all around the world.
In this whitepaper, we provide an overview of how Turing leverages machine learning (ML) to deliver value to both businesses and software developers. Further, we provide a high-level understanding of the foundations our ML models are built on. Finally, we go deeper into one specific case study on how AI has improved the matching process for Turing’s internal hiring team and clients who depend on Turing developers for their engineering efforts.
Overview
Turing’s Talent Cloud delivers value to companies looking to hire developers through two key foundational elements: vetting and matching. Machine learning drives their success in the following ways:
- Vetting (Technical Assessment): Developers typically undergo several hours of technical and non-technical tests and interviews. Our ML models help us recommend the right jobs for these developers based on their skills and competence. Cheating detection algorithms and heuristics help us automatically identify developers who cheated in coding challenges.
- Matching: Turing’s Talent Cloud has more than three million developers from around the world. Our ML algorithms leverage features extracted from the job requirements and developer profiles to surface the most relevant candidate. This enables clients to interview only the most qualified developers to scale their teams quickly. Further in this study, we will dig deeper into our journey of making these matching algorithms effective.
The foundations
It’s important to develop solid data foundations and technical architecture before building and deploying ML models at scale. A good data foundation and ML infrastructure helps ensure data quality, optimize data processing, and facilitate the efficient deployment of models, enabling us to scale our ML efforts effectively.
Client requirements & ML complexity
Over the past two years, Turing has developed machine learning solutions that have eliminated hiring workflow obstacles and provided benefits to our clients and developers. A prime illustration of this is the enhancement of Turing's ranking algorithms, which allow for the identification of the most competent developers for a particular job.
The complexity of this problem stems from the significant variation in our clients' requirements, such as specific skills, experience, and locations. Our initial approach was a hand-tuned ranking function, in which we manually weighted vetting signals, skill relevance, work experience, and rate. Weights were determined based on past hiring data and generated a score for a certain (job-developer) pair. The higher the score, the higher the relevance of that developer for that job.
Having evaluated different algorithms and their efficiency, it quickly became clear that further improvements were possible with machine learning models. We then formulated our problem as a binary classification task (distinguishing the developers that were hired from the others), quickly transitioned to logistic regression (LR), and eventually to gradient-boosted decision trees (GBDT)—progressing rapidly with the right algorithms for implementation.
A key characteristic of LR and GBDT model classes is their resilience to overfitting, especially when given a limited set of features. For LR, this resilience is a direct consequence of the simplicity of the model, but this makes it unable to model nonlinear effects of the features on the target label. On the other hand, GBDT is able to pick up even strongly nonlinear effects and can be hardened against overfitting thanks to its ability to impose monotonicity constraints. These constraints can bind the model into giving higher scores to developers having a higher value of a certain feature.
Model data sets
We train our machine learning models on past hiring data. In order to do this, we must reconstruct the past as faithfully as possible. Our typical approach is a binary classification task, in which we distinguish developers that were hired for a specific job from those that were not. In this framework, positive examples are straightforward to identify, but negative examples not so much. Developers that were never shown to clients are obviously not good negative examples, but at the same time, we tend to show only good developers to clients. Hence, if we only categorize negatives from developers that clients have seen, we run the risk of not teaching our models how to identify a completely irrelevant developer.
To solve this issue, we generate (job-developer) pairs by using multiple sources including positive examples (e.g., developers hired for the job), negative examples seen by clients (e.g., developers who failed the interview), negative examples unseen by clients but relevant for the job (e.g., developers with keywords in their resumes), and random negative examples (e.g., random developers selected to teach the model). Each of these classes of examples is appropriately weighted so that they all contribute to the training process with the amount of importance that we consider appropriate.
We mitigate ML model bias by choosing appropriate model architectures, removing bias from training data, and monitoring ML model performance in the real world to ensure biases are not creeping in. Mathematically, these techniques are similar to the ones used in the industry to ensure that models don’t perpetuate and reinforce existing societal biases and inequalities, particularly in the areas of employment, housing, and criminal justice.
ML infrastructure
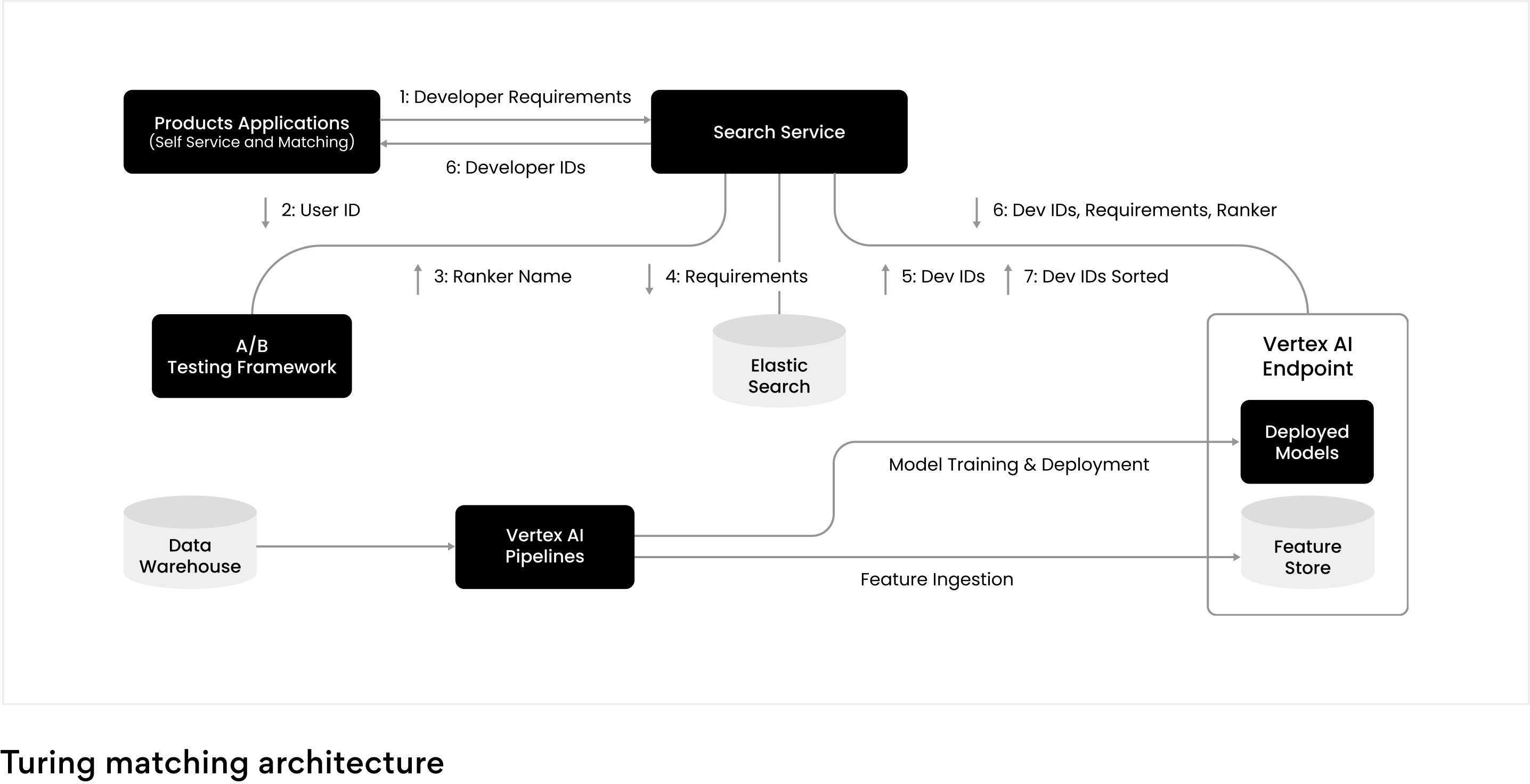
At Turing, we developed and deployed a ML platform built on top of Vertex AI, a service offering from Google Cloud. Our goal was to empower data scientists with a unified data and ML platform that made it easier and faster to train, deploy, scale, and monitor ML solutions for client problems. Our platform is fundamentally built to be scalable, be reliable, and provide low-latency predictions to power our product applications.
The above figure illustrates our overall matching architecture. Vertex AI–based pipelines are used to extract ML features from our data warehouse and ingest them into a feature store. The data from the feature store are used by our offline ML model training jobs, as well as the deployed online ML model at the time of inference, providing offline/online model consistency a desired property for any large scale ML solution.
The ML platform works in conjunction with Elasticsearch to retrieve and rank developers relevant to a particular job. Besides power search, the ML platform is used across Turing by other applications to provide recommendations, optimize our workflows, and so on.
Feature engineering
The different features used for modeling can be classified into three categories. The first category is "Developer Features," which includes information about each developer, such as their hourly rate and notice period, and is not specific to any particular job or query. The second category is "Job-Developer Features," which are a set of developer features that are dependent on the job and its required skills, such as the developer's performance on relevant tests. These features are not constant for a given developer and vary with the input. The third category is "Job Features," which includes information about the particular job and is not dependent on the developer.
Some of these features are directly generated by our products, such as performance on tests, but others require more sophisticated processing. For example, the most complex features are the text-based similarities between the developer resume and the required skills for the job (or the job description as a whole). These features are calculated by transformer models—complex machine learning models for natural language processing that are at the base of the recent wave of AI-powered chatbots. We have trained our own transformer model to generate vectorial representations of developer resumes, required skills for a job, and even job descriptions, from which we then calculate these features.
All the features we employ were carefully engineered after multiple iterations of univariate and multivariate analysis. The domain knowledge gathered from these analyses was transferred into modeling with the help of monotonicity constraints.
Offline model evaluation
Offline evaluation is the process of comparing models using offline metrics (i.e., not generated live by clients). This kind of evaluation needs to be quick, because we want to compare many models at once before deciding which one to take to production, and be reasonably predictive of future performance. We followed a leave-one-out cross-validation technique, in which we trained the model on all past jobs and evaluated its performance on one remaining job. Some crucial metrics we used in this case were the pairwise ranking score (similar to Kendall rank correlation coefficient) and win-loss-at-top-K (measuring the recall at top K positions).
Online model evaluation
Once our model passed the offline evaluation, a dedicated team manually reviewed the results for a few sample use cases to ensure that we are not gaming the metrics through some bias in the training set. Once this check passed, the model was productionized and evaluated online against the current production model in an A/B test. Decisions were taken at the end of the test period by looking at statistically significant improvements via p-values and confidence intervals.
Impact and way forward
As a result of continuous improvement from A/B testing to identify the right models, we found that our model scores gave a significant edge in the ratio of Interview Requests to Developer Chosen. Beyond a certain model score threshold, developers were more than 45 percent more likely to be chosen from an interview compared to those below this threshold.
To further improve these models, we have some exciting items on our roadmap, including introducing a multi-model ranking architecture and extending our feature set to include externally available data on developers. Equally important will be our continued efforts to improve the quality of our datasets that power these models.



Want to accelerate your business with AI?
Talk to one of our solutions architects and start innovating with AI-powered talent.